
前書き
GoogleDorksまたはGoogleHackingは、メディア、調査員、セキュリティエンジニア、およびその他の人がさまざまな検索エンジンにクエリを実行して、パブリックサーバーにある隠れた情報や脆弱性を発見するために使用する手法です。これは、通常のWebサイト検索クエリを最大限に使用して、表面に隠されている情報を判別する手法です。
Google Dorkingはどのように機能しますか?
OSINTツールとして機能するこの情報の収集と分析の例は、Googleの脆弱性でも、Webサイトホスティングをハッキングするためのデバイスでもありません。それどころか、高度な機能を備えた従来のデータ取得プロセスとして機能します。これは新しいことではありません。10年以上前に作成され、Googleハッキングを探索して使用するためのリポジトリとして機能するWebサイトが多数あるためです。
一方、検索エンジンは、ヘッダーとページコンテンツのインデックスを作成して保存し、それらをリンクして最適な検索クエリを作成します。しかし残念ながら、検索エンジンのWebスパイダーは、見つかったすべての情報に完全にインデックスを付けるように構成されています。 Webリソースの管理者は、この資料を公開するつもりはありませんでしたが。
ただし、Google Dorkingで最も興味深いのは、Google検索プロセスを学習する過程ですべての人を助けることができる膨大な量の情報です。新規参入者が行方不明の親戚を見つけるのを助けたり、自分の利益のために情報を抽出する方法を教えることができます。一般に、各リソースは独自の方法で面白くて驚くべきものであり、まさに彼が探しているものですべての人を助けることができます。
ドークスを通してどのような情報を見つけることができますか?
さまざまな工場機械のリモートアクセスコントローラーから、重要なシステムの構成インターフェイスにまで及びます。ネット上に投稿された膨大な量の情報を誰も見つけられないという想定があります。
ただし、順番に見ていきましょう。いつでも好きなときに携帯電話でライブで視聴できる新しいCCTVカメラを想像してみてください。 Wi-Fi経由でセットアップして接続し、アプリをダウンロードしてセキュリティカメラのログインを認証します。その後、世界中のどこからでも同じカメラにアクセスできます。
バックグラウンドでは、すべてがそれほど単純に見えるわけではありません。カメラは中国のサーバーにリクエストを送信し、リアルタイムでビデオを再生します。これにより、中国のサーバーでホストされているビデオフィードにログインして電話から開くことができます。このサーバーは、Webサイトからフィードにアクセスするためにパスワードを必要としない場合があり、カメラビューページに含まれるテキストを探している人なら誰でも公開できます。
そして残念ながら、GoogleはHTTPおよびHTTPSサーバーで実行されているインターネット上のデバイスを見つけるのに容赦なく効率的です。そして、これらのデバイスのほとんどには、それらをカスタマイズするための何らかのWebプラットフォームが含まれているため、これは、Googleにあることを意図していない多くのものがそこに行き着くことを意味します。
最も深刻なファイルタイプは、ユーザーまたは会社全体の資格情報を保持するファイルタイプです。これは通常、2つの方法で発生します。 1つ目は、サーバーが正しく構成されておらず、その管理ログまたはログがインターネット上で一般に公開されていることです。パスワードが変更されたり、ユーザーがログインできない場合、これらのアーカイブは資格情報とともにリークする可能性があります。
2番目のオプションは、同じ情報(ログイン、パスワード、データベース名など)を含む構成ファイルが公開されたときに発生します。これらのファイルは重要な情報を残すことが多いため、パブリックアクセスから非表示にする必要があります。これらのエラーはいずれも、攻撃者がこれらの抜け穴を見つけて、必要なすべての情報を取得する可能性があります。
この記事では、Google Dorksを使用して、これらすべてのファイルを見つける方法だけでなく、アドレス、電子メール、写真、さらには公開されているWebサイトのリストの形式で情報を含む脆弱なプラットフォームがどのようになり得るかについても説明します。
検索演算子の解析
ドーキングは、Googleだけでなく、さまざまな検索エンジンで使用できます。日常的に使用する場合、Google、Bing、Yahoo、DuckDuckGoなどの検索エンジンは、検索クエリまたは検索クエリ文字列を受け取り、関連する結果を返します。また、これらの同じシステムは、これらの検索用語を大幅に絞り込む、より高度で複雑な演算子を受け入れるようにプログラムされています。演算子は、検索エンジンにとって特別な意味を持つキーワードまたはフレーズです。一般的に使用される演算子の例は、「inurl」、「intext」、「site」、「feed」、「language」です。各演算子の後にコロンが続き、その後に対応する1つまたは複数のキーフレーズが続きます。
これらの演算子を使用すると、Webサイトのページ内の特定のテキスト行や、特定のURLでホストされているファイルなど、より具体的な情報を検索できます。特に、Google Dorkingは、非表示のログインページ、利用可能な脆弱性に関する情報を示すエラーメッセージ、および共有ファイルを見つけることもできます。主な理由は、Webサイト管理者がパブリックアクセスから除外することを単に忘れている可能性があるためです。
最も実用的であると同時に興味深いGoogleサービスは、削除またはアーカイブされたページを検索する機能です。これは、「cache:」演算子を使用して実行できます。オペレーターは、Googleキャッシュに保存されているWebページの保存(削除)バージョンを表示するように機能します。この演算子の構文を次に示します。
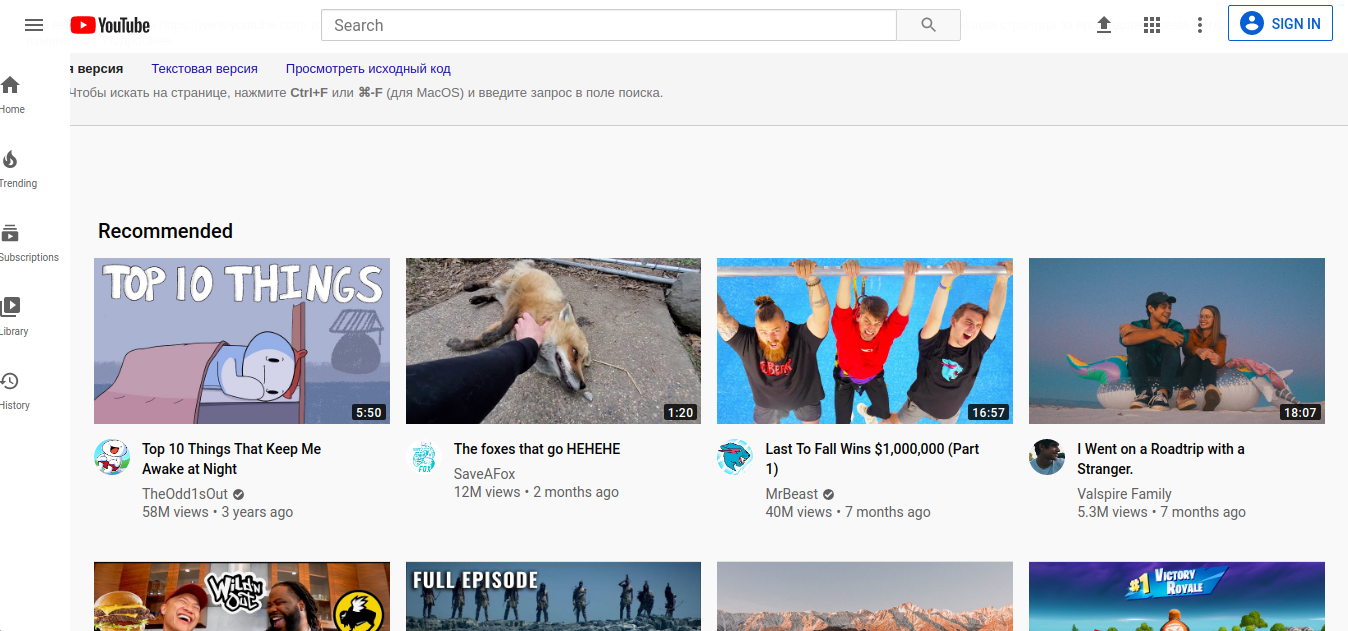
キャッシュ:www.youtube.com
上記のリクエストをGoogleに行った後、YoutubeWebページの以前のバージョンまたは古いバージョンへのアクセスが提供されます。このコマンドを使用すると、ページのフルバージョン、テキストバージョン、またはページソース自体(完全なコード)を呼び出すことができます。 Googleスパイダーによって作成されたインデックス作成の正確な時間(日付、時間、分、秒)も示されます。ページ自体は通常のHTMLページと同じ方法で検索されますが(キーボードショートカットCTRL + F)、ページはグラフィックファイルの形式で表示されます。 「cache:」コマンドの結果は、WebページがGoogleによってインデックスに登録された頻度によって異なります。開発者自身がHTMLドキュメントの先頭に特定の頻度でアクセスするインジケーターを設定した場合、Googleはそのページをセカンダリとして認識し、通常はPageRank比を優先して無視します。これは、ページのインデックス作成の頻度の主な要因です。したがって、特定のWebページがGoogleクローラーによる訪問の間に変更された場合、「cache:」コマンドを使用してインデックスに登録したり読み取ったりすることはありません。この機能をテストするときに特に効果的な例は、頻繁に更新されるブログ、ソーシャルメディアアカウント、およびオンラインポータルです。
誤って配置された、またはある時点で削除する必要がある削除された情報またはデータは、非常に簡単に復元できます。Webプラットフォーム管理者の怠慢は、彼を不要な情報を広めるリスクにさらす可能性があります。
ユーザー情報
ユーザー情報の検索は、検索結果を正確かつ詳細にする高度な演算子を使用して使用されます。演算子「@」は、ソーシャルネットワーク(Twitter、Facebook、Instagram)でインデックスを作成するユーザーを検索するために使用されます。同じポーランドの大学の例を使用すると、次のようにこの演算子を使用して、ソーシャルプラットフォームの1つでその公式の代表者を見つけることができます。
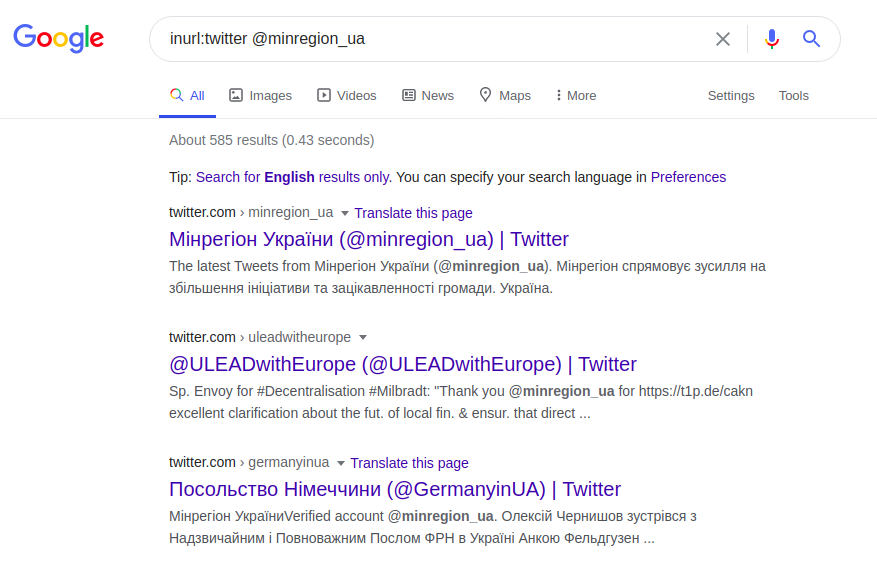
inurl:twitter @minregion_ua
このTwitterリクエストは、ユーザー「minregion_ua」を検索します。私たちが探しているユーザー(ウクライナのコミュニティと地域の開発省)の場所または仕事の名前と彼の名前がわかっていると仮定すると、より具体的な要求を行うことができます。また、機関のWebページ全体を面倒に検索する代わりに、電子メールアドレスに基づいて正しいクエリを実行し、アドレス名に少なくとも要求されたユーザーまたは機関の名前が含まれている必要があると想定できます。例えば:
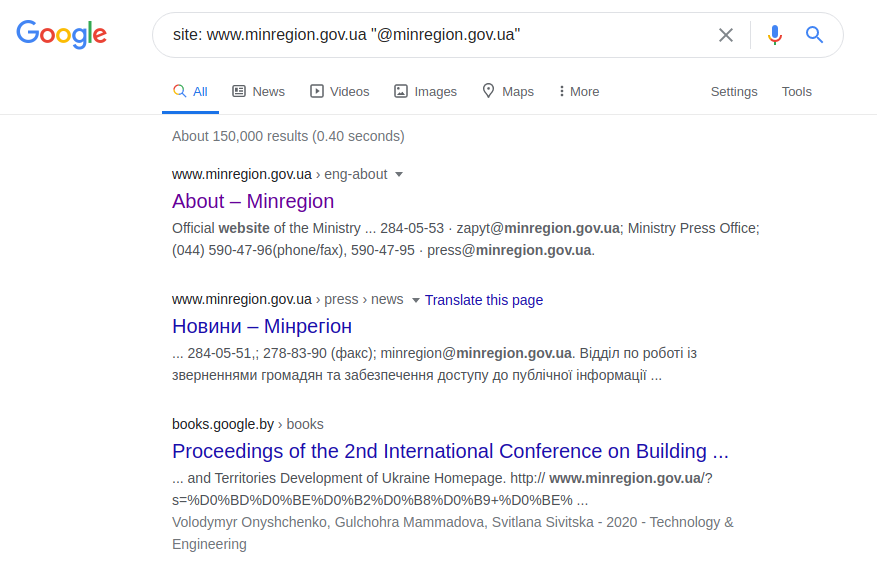
サイト:www.minregion.gov.ua "@ minregion.ua"運が良く
、Webリソース管理者の専門性が欠如していることを期待して、以下に示すように、それほど複雑でない方法を使用して、電子メールアドレスにのみリクエストを送信することもできます。
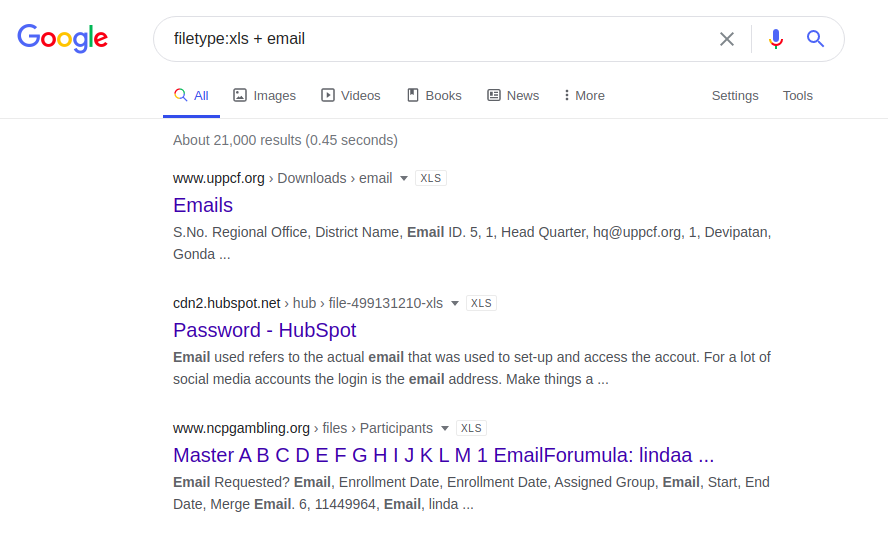
email.xlsx
ファイルタイプ:xls + email
さらに、次のリクエストを使用して、Webページから電子メールアドレスを取得することができます。

サイト:www.minregion.gov.ua intext:e-mail
上記のクエリは、ウクライナのコミュニティおよびテリトリー開発省のWebページでキーワード「email」を検索します。電子メールアドレスの検索は使用が制限されており、通常、事前に少し準備してユーザー情報を収集する必要があります。
残念ながら、Googleの電話帳でインデックスに登録された電話番号を検索できるのは、米国のみです。例えば:
電話帳:Arthur Mobile AL
ユーザー情報の検索は、Googleの「画像検索」または逆画像検索でも可能です。これにより、Googleによってインデックスに登録されたサイトで同一または類似の写真を見つけることができます。
Webリソース情報
Googleにはいくつかの便利な演算子があります。特に「related:」は、目的のWebサイトに「類似した」Webサイトのリストを表示します。類似性は、論理的または意味のあるリンクではなく、機能的なリンクに基づいています。
関連:minregion.gov.ua
この例は、ウクライナの他の省庁のページを表示します。この演算子は、高度なGoogle検索の[関連ページ]ボタンのように機能します。同様に、特定のWebページに情報を表示する「info:」リクエストが機能します。これは、Webサイトのタイトル()、つまりメタ説明タグ(<メタ名=「説明」)に表示されるWebページの特定の情報です。例:

info:minregion.gov.ua
別のクエリ「define:」は、研究論文を見つけるのに非常に役立ちます。これにより、百科事典やオンライン辞書などのソースから単語の定義を取得できます。そのアプリケーションの例:
定義:ウクライナの領土
ユニバーサル演算子--tilde( "〜")を使用すると、類似した単語または同義語を検索できます。
〜コミュニティ〜開発
上記のクエリは、「コミュニティ」(テリトリー)と「開発」(開発)という単語を含むWebサイトと、「コミュニティ」という同義語を含むWebサイトの両方を表示します。クエリを変更する「link:」演算子は、検索範囲を特定のページに指定されたリンクに制限します。
リンク:www.minregion.gov.ua
ただし、この演算子はすべての結果を表示するわけではなく、検索条件を拡張するものでもありません。
ハッシュタグは、情報をグループ化できる一種の識別番号です。現在、Instagram、VK、Facebook、Tumblr、TikTokで使用されています。Googleでは、多数のソーシャルネットワークを同時に検索することも、推奨されるものだけを検索することもできます。検索エンジンの一般的なクエリの例は次のとおりです。
#polyticavukrainі
演算子「AROUND(n)」を使用すると、特定の数の単語から離れた場所にある2つの単語を検索できます。例:

ウクライナ周辺省(4)
上記のクエリの結果、これら2つの単語(「省」と「ウクライナ」)を含むWebサイトが表示されますが、これらは他の4つの単語で区切られています。
Googleは記録された形式に従ってコンテンツにインデックスを付けるため、ファイルタイプによる検索も非常に便利です。これを行うには、「filetype:」演算子を使用します。現在使用されているファイル検索は非常に広範囲です。利用可能なすべての検索エンジンの中で、Googleはオープンソースを検索するための最も洗練された一連のオペレーターを提供しています。
前述の演算子の代わりに、MaltegoやOryon OSINTBrowserなどのツールをお勧めします。自動データ検索を提供し、特別なオペレーターの知識を必要としません。プログラムのメカニズムは非常に単純です。GoogleまたはBingに送信された正しいクエリを使用して、関心のある機関によって公開されたドキュメントが検索され、これらのドキュメントのメタデータが分析されます。このようなプログラムの潜在的な情報リソースは、「。doc」、「。pdf」、「。ppt」、「。odt」、「。xls」、「。jpg」などの拡張子を持つ各ファイルです。
さらに、ファイルを公開する前に、「メタデータのクリーンアップ」を適切に処理する方法についても言及する必要があります。一部のWebガイドは、メタ情報を取り除くための少なくともいくつかの方法を提供します。ただし、それはすべて管理者自身の個人的な好みに依存するため、最善の方法を推測することは不可能です。一般に、最初にメタデータを格納しない形式でファイルを記述してから、ファイルを使用可能にすることをお勧めします。インターネット上には、主に画像用の無料のメタデータクリーニングプログラムが多数あります。ExifCleanerは、最も望ましいものの1つと見なすことができます。テキストファイルの場合は、手動でクリーンアップすることを強くお勧めします。
サイト所有者が無意識のうちに残した情報
Googleによってインデックスが作成されたリソースは、公開されたままにするか(たとえば、サーバーに残された内部ドキュメントや会社の資料)、同じ人が便宜上保持します(たとえば、音楽ファイルや映画ファイル)。このようなコンテンツの検索は、Googleを使用してさまざまな方法で行うことができ、最も簡単な方法は推測することです。たとえば、特定のディレクトリにファイル5.jpg、8.jpg、9.jpgがある場合、1から4、6から7、さらには9のファイルがあると予測できます。したがって、あるべきではない資料にアクセスできます。公開されることになっていた。もう1つの方法は、Webサイトで特定の種類のコンテンツを検索することです。音楽ファイル、写真、映画、本(電子書籍、オーディオブック)を検索できます。
別のケースでは、これらはユーザーが無意識のうちにパブリックアクセスに残したファイルである可能性があります(たとえば、自分で使用するためのFTPサーバー上の音楽)。この情報は、「filetype:」演算子または「inurl:」演算子を使用する2つの方法で取得できます。例えば:
ファイルタイプ:docサイト:gov.ua
サイト:www.minregion.gov.uaファイルタイプ:pdf
サイト:www.minregion.gov.ua inurl:doc
検索クエリを使用してプログラムファイルを検索し、目的のファイルを拡張子でフィルタリングすることもできます。
ファイルタイプ:iso
Webページの構造に関する情報
特定のWebページの構造を表示し、その構造全体を明らかにするために、サーバーとその脆弱性を将来的に支援するために、「site:」演算子のみを使用してこれを行うことができます。次のフレーズを分析してみましょう。
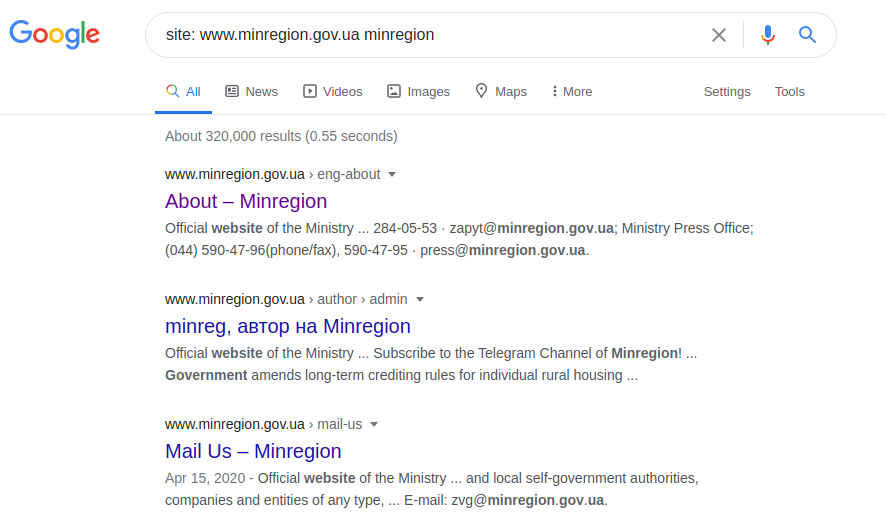
サイト:www.minregion.gov.uaのminregion
私たちは、ドメイン「www.minregion.gov.ua」の言葉「minregion」の検索を開始。このドメインのすべてのサイト(Googleはテキスト、見出し、サイトのタイトルの両方で検索)にこの単語が含まれています。したがって、その特定のドメインのすべてのサイトの完全な構造を取得します。ディレクトリ構造が利用可能になると、次のクエリを使用して、より正確な結果を取得できます(ただし、これが常に発生するとは限りません)。
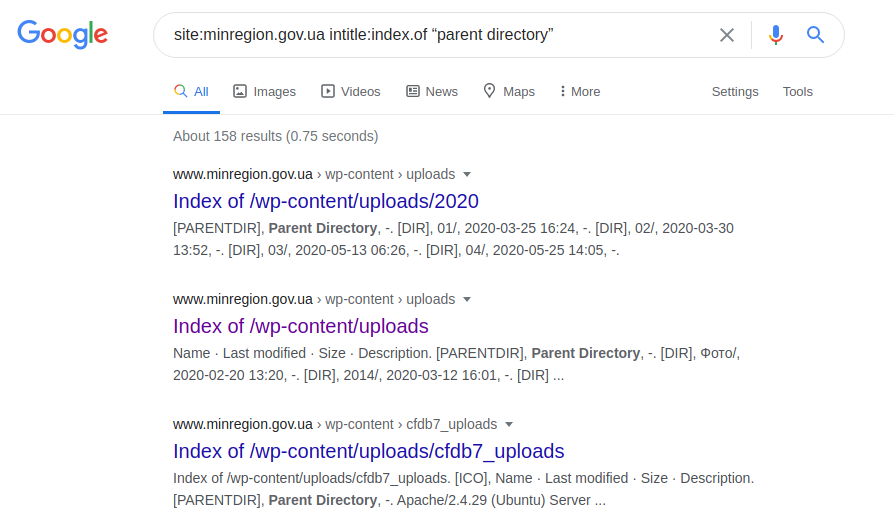
site:minregion.gov.ua intitle:index.of "parent directory"
これは、 "minregion.gov.ua"の最も保護されていないサブドメインを表示し、ファイルのダウンロードの可能性とともに、ディレクトリ全体を検索する機能を備えている場合があります。したがって、当然のことながら、このような要求は、他のサーバーの制御下で保護または実行できるため、すべてのドメインに適用できるわけではありません。
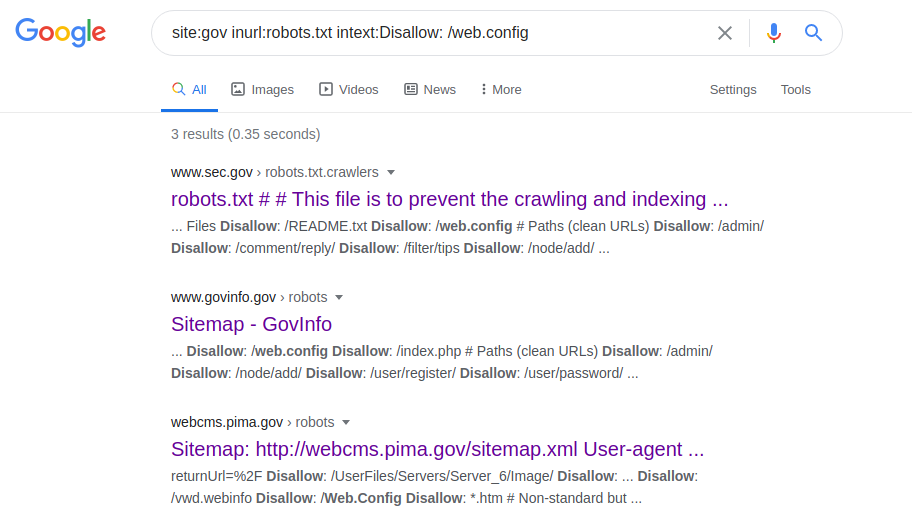
サイト:gov inurl:robots.txt intext:禁止:/web.config
この演算子を使用すると、さまざまなサーバーの構成パラメーターにアクセスできます。リクエストを行った後、robots.txtファイルに移動し、「web.config」へのパスを探して、指定されたファイルパスに移動します。サーバーの名前、そのバージョン、およびその他のパラメーター(ポートなど)を取得するために、次の要求が行われます。
サイト:gosstandart.gov.by intitle:index.of server.at
各サーバーのホームページには、インターネット情報サービス(IIS)などの固有のフレーズがいくつかあります。
intitle:welcome.to intitle:インターネットIIS
サーバー自体の定義とそこで使用されるテクノロジーは、要求されているクエリの工夫にのみ依存します。たとえば、技術仕様、マニュアル、またはいわゆるヘルプページを明確にすることでこれを試みることができます。この機能を実証するために、次のクエリを使用できます。
サイト:gov.ua inurl:手動apacheディレクティブモジュール(Apache)
たとえば、SQLエラーのあるファイルのおかげで、アクセスを拡張できます。
「#Mysqldump」ファイルタイプ:SQL
データベースのSQLエラーは、特に、データベースの構造とコンテンツに関する情報を提供する可能性があります。次に、次のリクエストにより、Webページ全体、その元のバージョンおよび/または更新されたバージョンにアクセスできます。
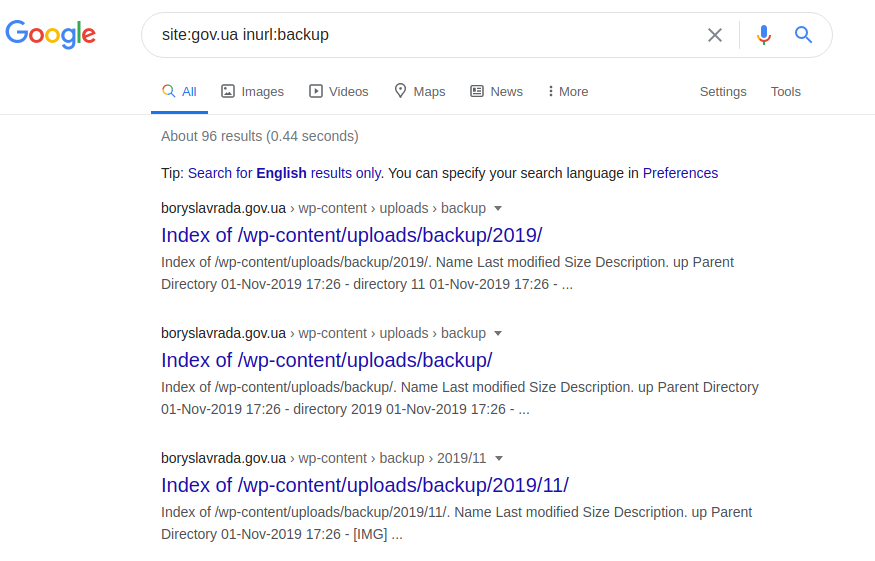
サイト:gov.ua inurl:バックアップ
サイト:gov.ua inurl:バックアップintitle:index.of inurl:admin
現在、上記の演算子を使用しても、知識のあるユーザーが事前にブロックできるため、期待した結果が得られることはめったにありません。
また、FOCAプログラムを使用すると、上記の演算子を検索したときと同じコンテンツを見つけることができます。開始するには、プログラムにドメイン名の名前が必要です。その後、特定の機関のサーバーに接続されているドメイン全体と他のすべてのサブドメインの構造を分析します。この情報は、[ネットワーク]タブの下のダイアログボックスにあります。
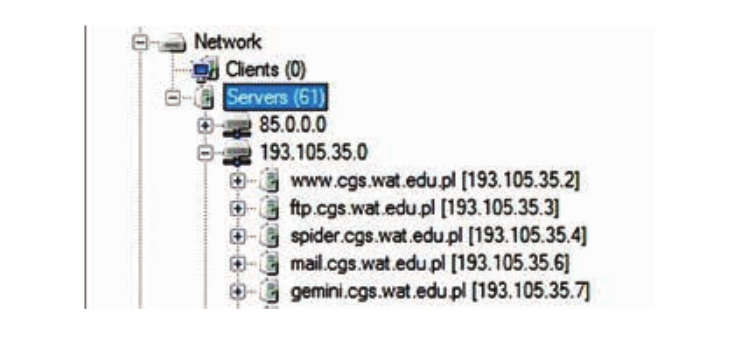
したがって、潜在的な攻撃者は、Web管理者が残したデータ、内部ドキュメント、および隠しサーバーに残された会社の資料を傍受する可能性があります。
考えられるすべてのインデックス作成演算子についてさらに詳しく知りたい場合は、ここですべてのGoogleDorking演算子のターゲットデータベースを確認できます。また、GitHubで最も一般的で脆弱なURLリンクをすべて収集し、自分にとって興味深いものを検索しようとする1つの興味深いプロジェクトに精通することもできます。これは、このリンクで確認できます。
組み合わせて結果を得る
より具体的な例として、以下は一般的に使用されるGoogleオペレーターの小さなコレクションです。さまざまな追加情報と同じコマンドを組み合わせて、検索結果に機密情報を取得するプロセスの詳細が表示されます。結局のところ、通常の検索エンジンであるGoogleにとって、情報を収集するこのプロセスは非常に興味深いものになる可能性があります。
米国国土安全保障局のウェブサイトで予算を検索してください。
次の組み合わせは、「予算」という単語を含む、公開されているすべてのExcelスプレッドシートを提供します。
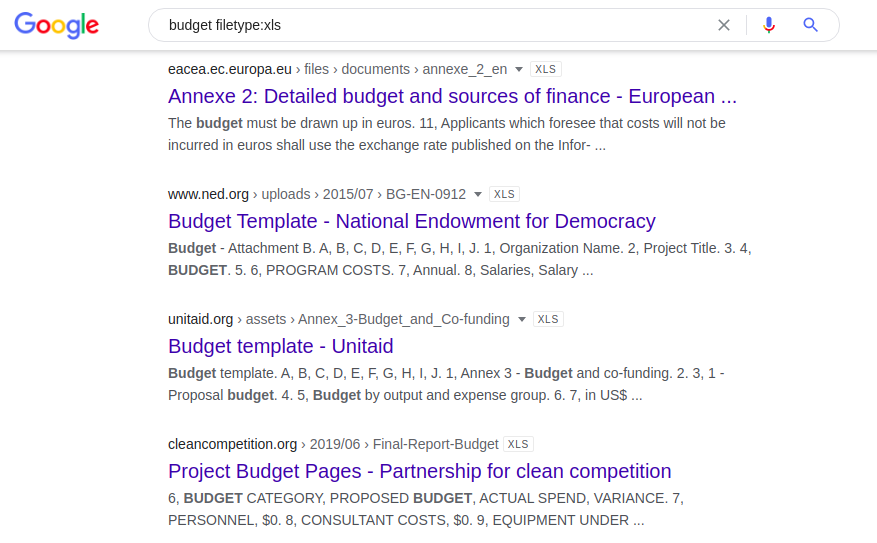
予算ファイルタイプ:xls
「filetype:」演算子は同じファイル形式の異なるバージョン(たとえば、docとodt、またはxlsxとcsv)を自動的に認識しないため、これらの各形式を個別に分割する必要があります。
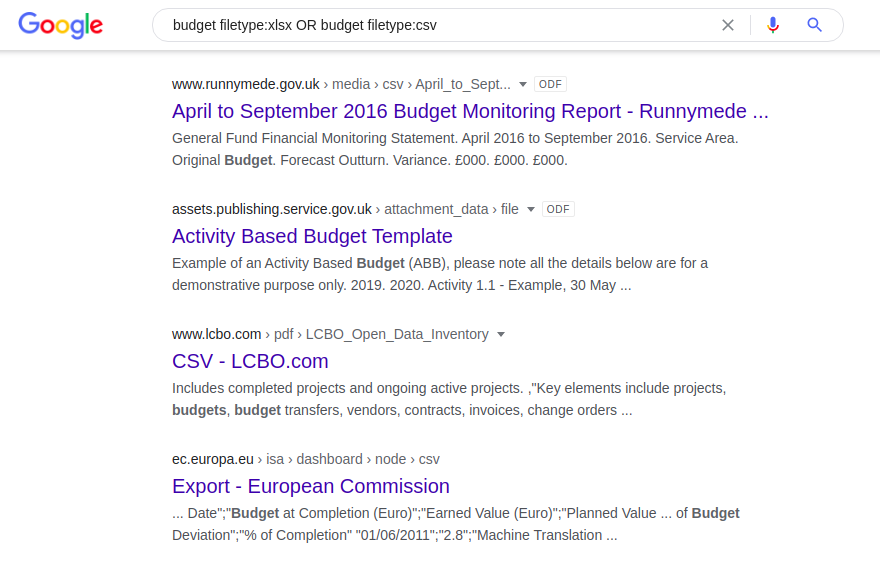
予算ファイルタイプ:xlsxまたは予算ファイルタイプ:csv
後続のdorkは、NASAWebサイトでPDFファイルを返します。
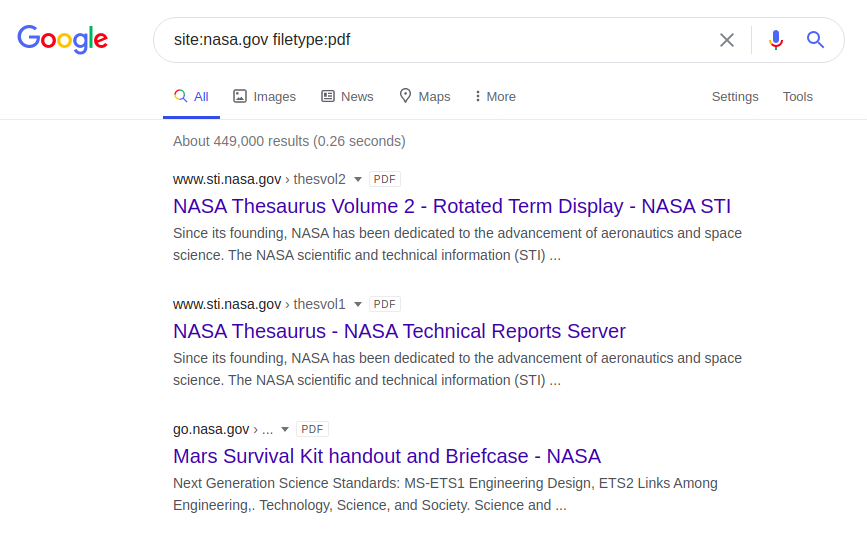
サイト:nasa.govファイルタイプ:pdf
キーワード「budget」でdorkを使用するもう1つの興味深い例は、国防総省の公式Webサイトで「pdf」形式の米国のサイバーセキュリティドキュメントを検索することです。
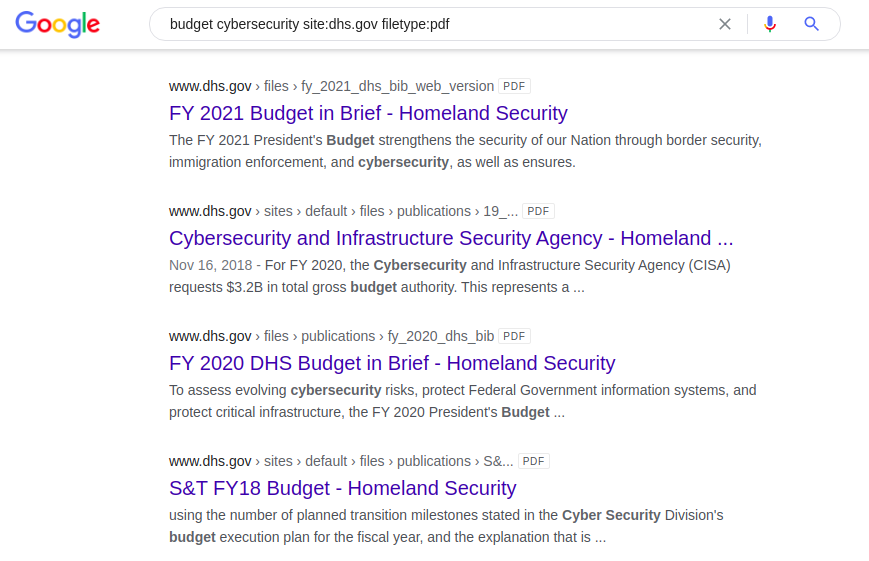
予算サイバーセキュリティサイト:dhs.govファイルタイプ:pdf
同じdorkアプリケーションですが、今回の検索エンジンは、米国国土安全保障省のWebサイトに「budget」という単語を含む.xlsxスプレッドシートを返します。
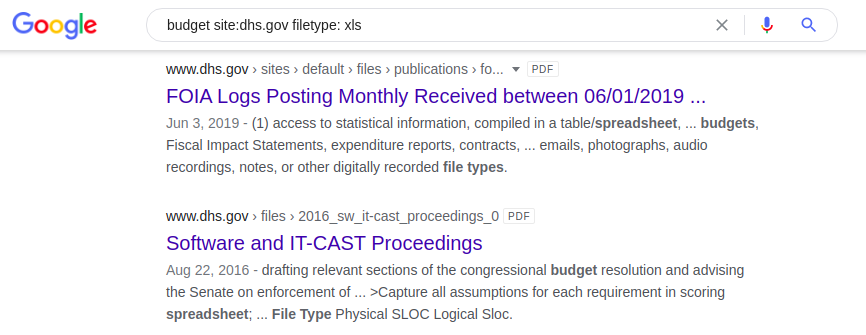
予算サイト:dhs.govファイルタイプ:xls
パスワードを検索する
ログインとパスワードで情報を検索すると、自分のリソースの脆弱性を検索するのに役立ちます。それ以外の場合、パスワードはWebサーバー上の共有ドキュメントに保存されます。さまざまな検索エンジンで次の組み合わせを試すことができます。
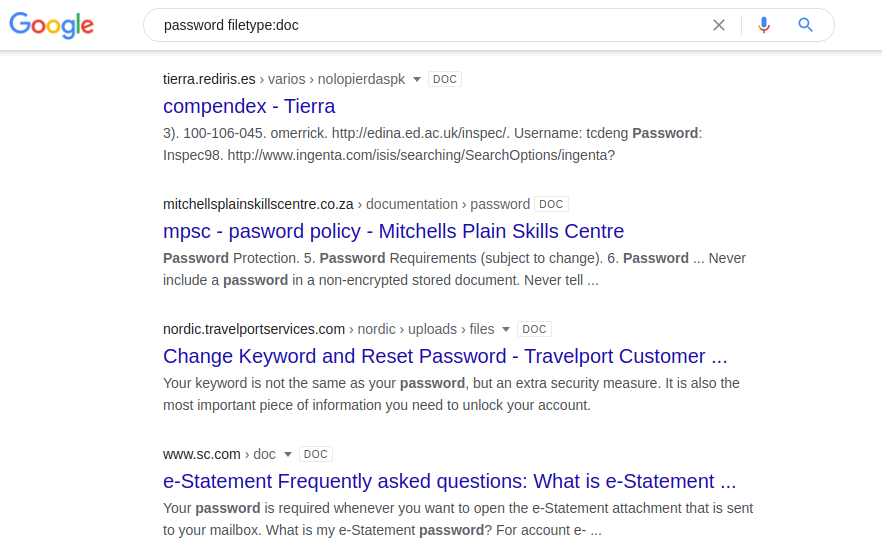
パスワードファイルタイプ:doc / docx / pdf / xls
パスワードファイルタイプ:doc / docx / pdf / xlsサイト:[サイト名]
このようなクエリを別の検索エンジンに入力しようとすると、まったく異なる結果が得られる可能性があります。たとえば、「site:[Site Name]」という用語を使用せずにこのクエリを実行すると、Googleは、一部のアメリカの高校の実際のユーザー名とパスワードを含むドキュメントの結果を返します。他の検索エンジンは、結果の最初のページにこの情報を表示しません。以下に示すように、YahooとDuckDuckGoが例です。
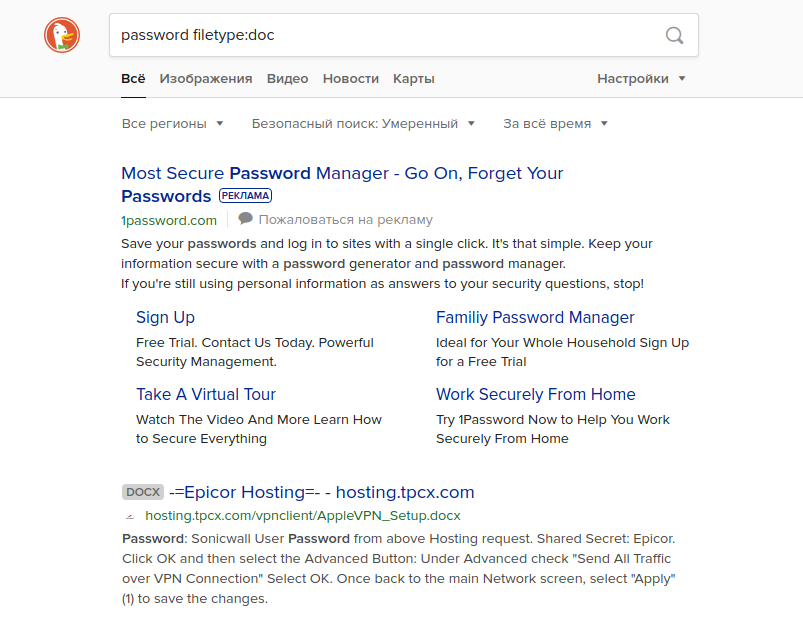
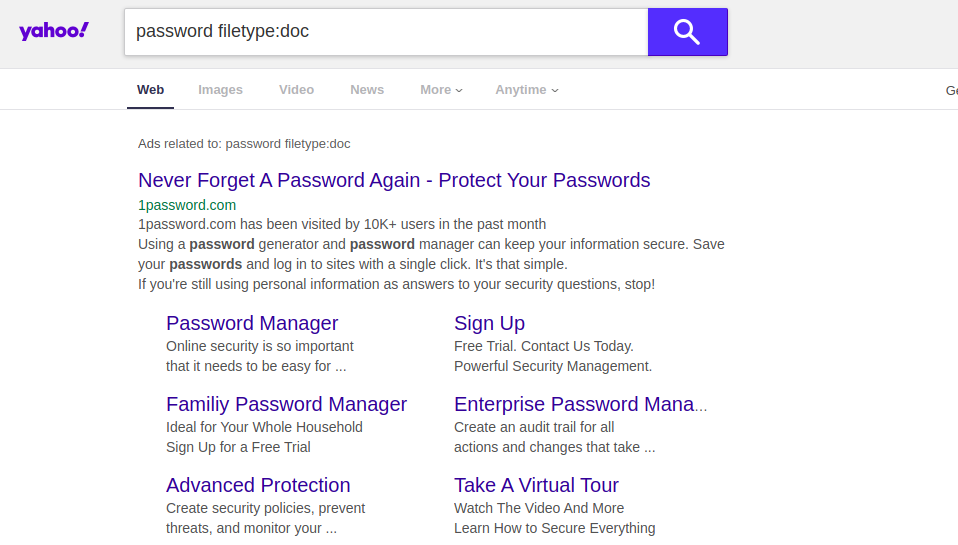
ロンドンの住宅価格
もう1つの興味深い例は、ロンドンの住宅の価格に関する情報に関するものです。以下は、4つの異なる検索エンジンに入力されたクエリの結果です。
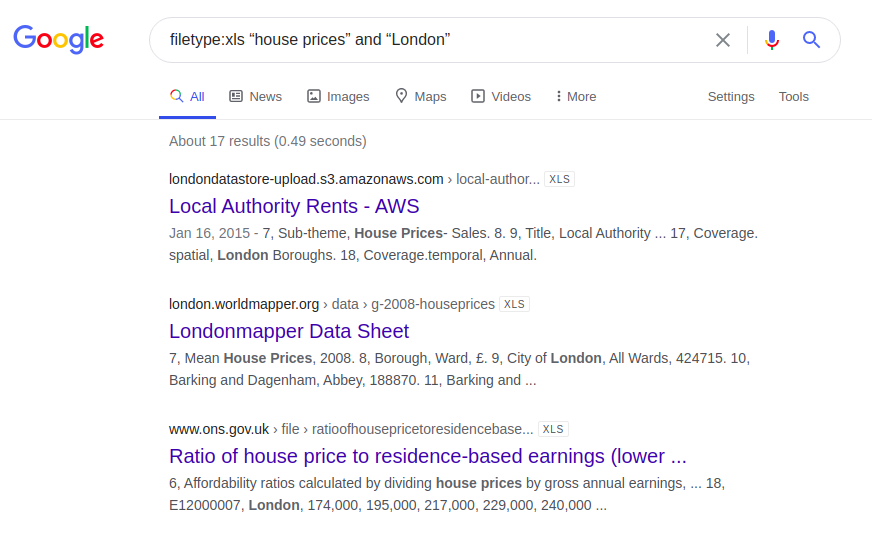
filetype:xls "houseprices"と "London"
おそらく、あなたはあなた自身のアイデアと、あなた自身の情報検索でどのウェブサイトに焦点を合わせたいか、あるいはあなた自身のリソースを適切にチェックして潜在的な脆弱性についてのアイデアを持っているでしょう。 ..。
代替の検索インデックス作成ツール
GoogleDorkingを使用して情報を収集する他の方法もあります。これらはすべて代替手段であり、検索の自動化として機能します。以下では、共有する罪ではない最も人気のあるプロジェクトのいくつかを見てみることを提案します。
Googleハッキングオンライン
Google Hacking Onlineは、確立されたオペレーターを使用したWebページを介したさまざまなデータのGoogle Dorking検索のオンライン統合であり、ここで見つけることができます。このツールは、目的のリソースへのリンクの目的のIPアドレスまたはURLを、推奨される検索オプションとともに検索するための単純な入力フィールドです。
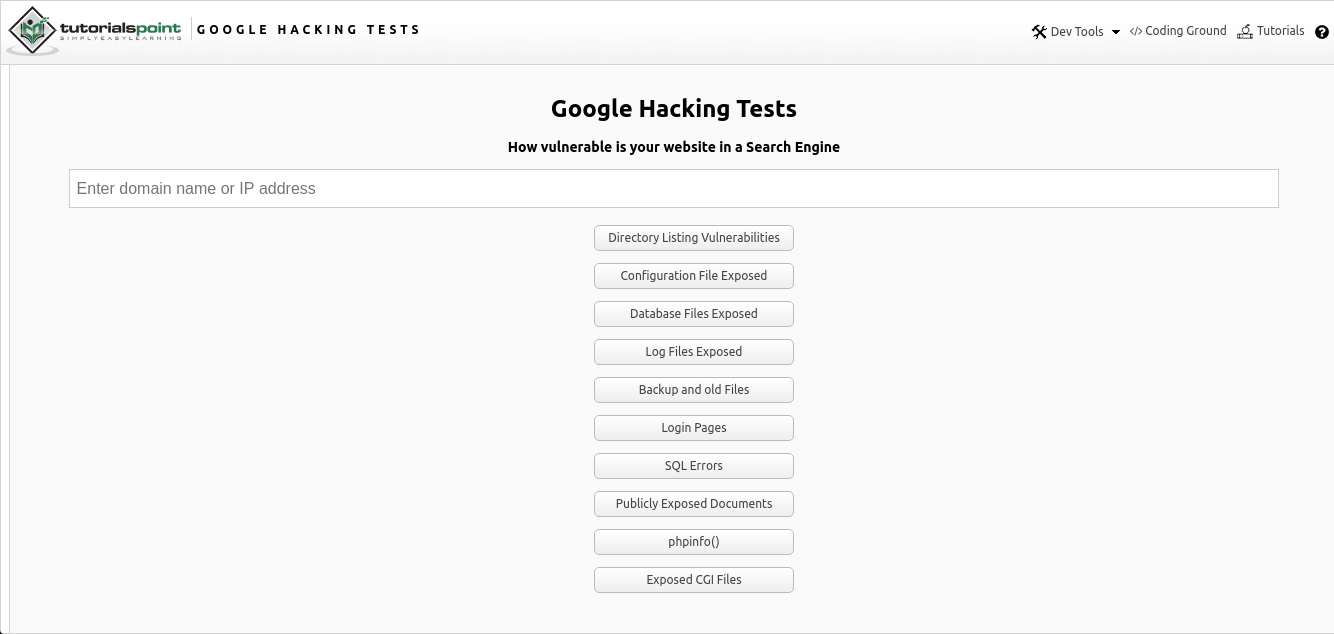
上の図からわかるように、いくつかのパラメーターによる検索は、いくつかのオプションの形式で提供されます。
- 公開されている脆弱なディレクトリを検索する
- 構成ファイル
- データベースファイル
- ログ
- 古いデータとバックアップデータ
- 認証ページ
- SQLエラー
- 公開されているドキュメント
- サーバーのphp構成情報( "phpinfo")
- Common Gateway Interface(CGI)ファイル
すべては、Webページファイル自体に記述されているバニラJSで機能します。最初に、入力されたユーザー情報、つまりWebページのホスト名またはIPアドレスが取得されます。そして、入力された情報をオペレーターに要求します。特定のリソースを検索するためのリンクが新しいポップアップウィンドウで開き、結果が表示されます。
BinGoo
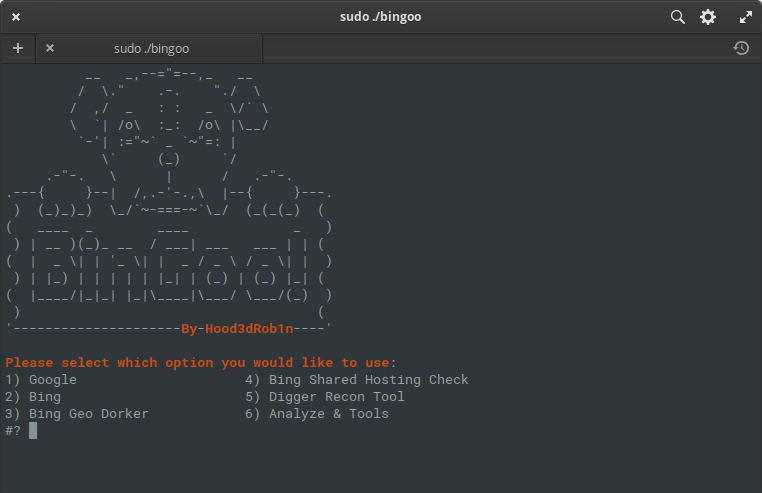
BinGooは、純粋なbashで記述された用途の広いツールです。検索演算子GoogleとBingを使用して、提供された検索用語に基づいて多数のリンクをフィルタリングします。一度に1人のオペレーターを検索するか、1行に1人のオペレーターをリストして、一括スキャンを実行するかを選択できます。最初の収集プロセスが完了するか、他の方法でリンクを収集したら、分析ツールに移動して、脆弱性の一般的な兆候を確認できます。
結果は、得られた結果に基づいて適切なファイルにきちんと分類されます。ただし、分析はここで停止するわけではありません。さらに進んで、追加のSQLまたはLFI機能を使用して実行するか、SQLMAPおよびFIMAPラッパーツールを使用して、正確な結果を得ることができます。
また、ドメインタイプに基づくジオドーキング、ドメイン内の国コード、事前構成されたBing検索とドークリストを使用して他のサイトで発生する可能性のある脆弱性を探す共有ホスティングチェッカーなど、作業を楽にするいくつかの便利な機能も含まれています。提供されたリストと確認用のサーバー応答コードに基づいた管理ページの簡単な検索も含まれています。一般的に、これは与えられた情報の主な収集と分析を実行するツールの非常に興味深くコンパクトなパッケージです!あなたはここでそれを知ることができます。
パゴド
Pagodoツールの目的は、潜在的に脆弱なWebページとアプリケーションをインターネット経由で収集するためのGoogleDorkingオペレーターのパッシブインデックス作成です。プログラムは2つの部分で構成されています。 1つ目はghdb_scraper.pyで、これはGoogle Dorksオペレーターを照会および収集し、2つ目はpagodo.pyは、ghdb_scraper.pyを通じて収集された演算子と情報を使用し、Googleクエリを通じてそれを解析します。
pagodo.pyファイルには、最初にGoogleDorksオペレーターのリストが必要です。同様のファイルがプロジェクト自体のリポジトリに提供されているか、ghdb_scraper.pyを使用して1回のGETリクエストでデータベース全体をクエリするだけです。次に、個々のdorksステートメントをテキストファイルにコピーするか、追加のコンテキストデータが必要な場合はjsonに配置します。
この操作を実行するには、次のコマンドを入力する必要があります。
python3 ghdb_scraper.py -j -s必要なすべての演算子を含むファイルができたので、「-g」オプションを使用してpagodo.pyにリダイレクトし、潜在的に脆弱なパブリックアプリケーションの収集を開始できます。pagodo.pyファイルは、「google」ライブラリを使用して、次のような演算子を使用してそのようなサイトを検索します
。intitle: "ListMail Login" admin -demo
site:example.com
残念ながら、Googleを介した非常に多くのリクエスト(つまり、約4600)のプロセスは単純です。動作しないでしょう。Googleはすぐにあなたをボットとして識別し、一定期間IPアドレスをブロックします。検索クエリをより有機的に見せるために、いくつかの改善が追加されました。
google Pythonモジュールは、Google検索全体でユーザーエージェントをランダム化できるように特別に調整されています。この機能はモジュールバージョン1.9.3で利用可能であり、各検索クエリに使用されるさまざまなユーザーエージェントをランダム化できます。この機能を使用すると、大規模な企業環境で使用されるさまざまなブラウザをエミュレートできます。
2番目の機能強化は、検索間の時間をランダム化することに焦点を当てています。最小遅延は-eパラメーターを使用して指定され、ジッター係数は最小遅延数に時間を追加するために使用されます。 50個のジッタのリストが生成され、そのうちの1つが各Google検索の最小遅延にランダムに追加されます。
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))さらにスクリプトでは、ジッタ配列からランダムな時間が選択され、要求の作成の遅延に追加されます。
pause_time = self.delay + random.choice (self.jitter)自分で値を試すことができますが、デフォルト設定は問題なく機能します。ツールの処理には数日かかる場合があることに注意してください(平均3日、指定されたオペレーターの数と要求間隔によって異なります)。そのため、時間があることを確認してください。
ツール自体を実行するには、次のコマンドで十分です。ここで、「example.com」は対象のWebサイトへのリンクであり、「dorks.txt」はghdb_scraper.pyが作成したテキストファイルです。
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1また、このリンクをクリックすると、ツールに触れて慣れることができます。
Googleドーキングからの保護方法
主な推奨事項
Google Dorkingには、他のオープンソースツールと同様に、侵入者が機密情報を収集するのを保護および防止する独自の手法があります。「GoogleDorking」による脅威を回避するために、Webプラットフォームおよびサーバーの管理者は、5つのプロトコルに関する次の推奨事項に従う必要があります。
- オペレーティングシステム、サービス、およびアプリケーションの体系的な更新。
- アンチハッカーシステムの実装と保守。
- Googleロボットとさまざまな検索エンジンの手順、およびそのようなプロセスを検証する方法についての認識。
- 公開ソースから機密コンテンツを削除する。
- パブリックコンテンツとプライベートコンテンツを分離し、パブリックユーザーのコンテンツへのアクセスをブロックします。
.Htaccessおよびrobots.txtファイルの構成
基本的に、「ドーキング」に関連するすべての脆弱性と脅威は、さまざまなプログラム、サーバー、またはその他のWebデバイスのユーザーの不注意または怠慢によって生成されます。したがって、自己保護とデータ保護のルールは、問題や複雑さを引き起こしません。
検索エンジンによるインデックス作成の防止に注意深く取り組むには、ネットワークリソースの2つの主要な構成ファイル「.htaccess」と「robots.txt」に注意を払う必要があります。 1つ目は、指定されたパスとディレクトリをパスワードで保護します。 2つ目は、検索エンジンによるインデックス作成からディレクトリを除外します。
独自のリソースに、Googleでインデックスを作成してはならない特定の種類のデータまたはディレクトリが含まれている場合は、まず、パスワードを使用してフォルダへのアクセスを構成する必要があります。以下の例では、任意のWebサイトのルートディレクトリにある「.htaccess」ファイルにどのように、何を正確に書き込む必要があるかを明確に確認できます。
まず、次のように数行追加します。AuthUserFile / your / directory / here /
.htpasswd
AuthGroupFile / dev / null
AuthName "Secure Document"
AuthType Basic
require user username1
require user username2
require user username3
AuthUserFile行で、ディレクトリにある.htaccessファイルの場所へのパスを指定します。そして最後の3行で、アクセスが提供される対応するユーザー名を指定する必要があります。次に、「。htaccess」と同じフォルダに「.htpasswd」を作成し、次のコマンドを実行する必要があります
。htpasswd-c .htpasswd username1 username1
のパスワードを2回入力すると、完全にクリーンなファイル「.htpasswd」が作成されます。現在のディレクトリであり、暗号化されたバージョンのパスワードが含まれます。
複数のユーザーがいる場合は、それぞれにパスワードを割り当てる必要があります。ユーザーを追加するために、新しいファイルを作成する必要はありません。次のコマンドを使用して、-cオプションを使用せずに、既存のファイルにユーザーを追加するだけです。
htpasswd .htpasswd username2
その他の場合は、robots.txtファイルを設定することをお勧めします。このファイルは、Webリソースのページのインデックス作成を担当します。特定のページアドレスにリンクする検索エンジンのガイドとして機能します。そして、探しているソースに直接移動する前に、robots.txtはそのような要求をブロックするか、スキップします。
ファイル自体は、インターネット上で実行されているWebプラットフォームのルートディレクトリにあります。設定は、「User-agent」と「Disallow」の2つの主要なパラメータを変更するだけで実行されます。最初のものは、すべてまたは一部の特定の検索エンジンを強調表示してマークします。2つ目は、正確にブロックする必要があるもの(ファイル、ディレクトリ、特定の拡張子を持つファイルなど)を示しています。以下にいくつかの例を示します。ディレクトリ、ファイル、およびインデックス作成プロセスから除外された特定の検索エンジンの除外。
ユーザーエージェント:*
禁止:/ cgi-bin /
ユーザーエージェント:*
禁止:/~joe/junk.html
ユーザーエージェント:Bing
禁止:/
メタタグの使用
また、Webスパイダーの制限を別のWebページに導入することもできます。それらは、一般的なWebサイト、ブログ、および構成ページの両方にあります。 HTMLの見出しには、次のフレーズのいずれかを
付ける必要があります。<meta name =“ Robots” content =“ none” \>
<meta name =“ Robots” content =“ noindex、nofollow” \>
このようなエントリをページヘッダーに追加すると、Googleロボットはセカンダリページまたはメインページにインデックスを付けません。この文字列は、インデックスを作成しないページに入力できます。ただし、この決定は、検索エンジンとユーザー自身の間の相互合意に基づいています。 Googleやその他のWebスパイダーは前述の制限を順守しますが、インデックスなしで最初に構成されたデータを取得するためにそのようなフレーズを「ハント」する特定のWebロボットがあります。
インデックスセキュリティのより高度なオプションのうち、CAPTCHAシステムを使用できます。これは、自動化されたボットではなく、人間だけがページのコンテンツにアクセスできるようにするコンピューターテストです。ただし、このオプションには小さな欠点があります。ユーザー自身にとってはあまりユーザーフレンドリーではありません。
Google Dorksのもう1つの簡単な防御手法は、たとえば、管理ファイル内の文字をASCIIでエンコードして、GoogleDorkingの使用を困難にすることです。
ペンテストの練習
ペンテストの実践は、ネットワークおよびWebプラットフォームの脆弱性を特定するためのテストです。このようなテストは、Google Dorkingを含むWebページまたはサーバーの脆弱性のレベルを一意に決定するため、独自の方法で重要です。インターネット上にある専用のペンテストツールがあります。そのうちの1つはSiteDiggerです。これは、選択したWebページのGoogleHackingデータベースを自動的にチェックできるサイトです。また、Wiktoスキャナー、SUCURI、その他のさまざまなオンラインスキャナーなどのツールもあります。それらは同じように機能します。
Google Hack Honeypotなど、攻撃者を誘惑して攻撃者に関する機密情報を取得するために、バグや脆弱性とともにWebページ環境を模倣するより高度なツールがあります。 Google Dorkingからの保護に関する知識がほとんどなく、経験が不十分な標準ユーザーは、まずネットワークリソースをチェックして、Google Dorkingの脆弱性を特定し、公開されている機密データを確認する必要があります。これらのデータベース、haveibeenpwned.comおよびdehashed.comを定期的にチェックして、オンラインアカウントのセキュリティが侵害され、公開されていないかどうかを確認することをお勧めします。
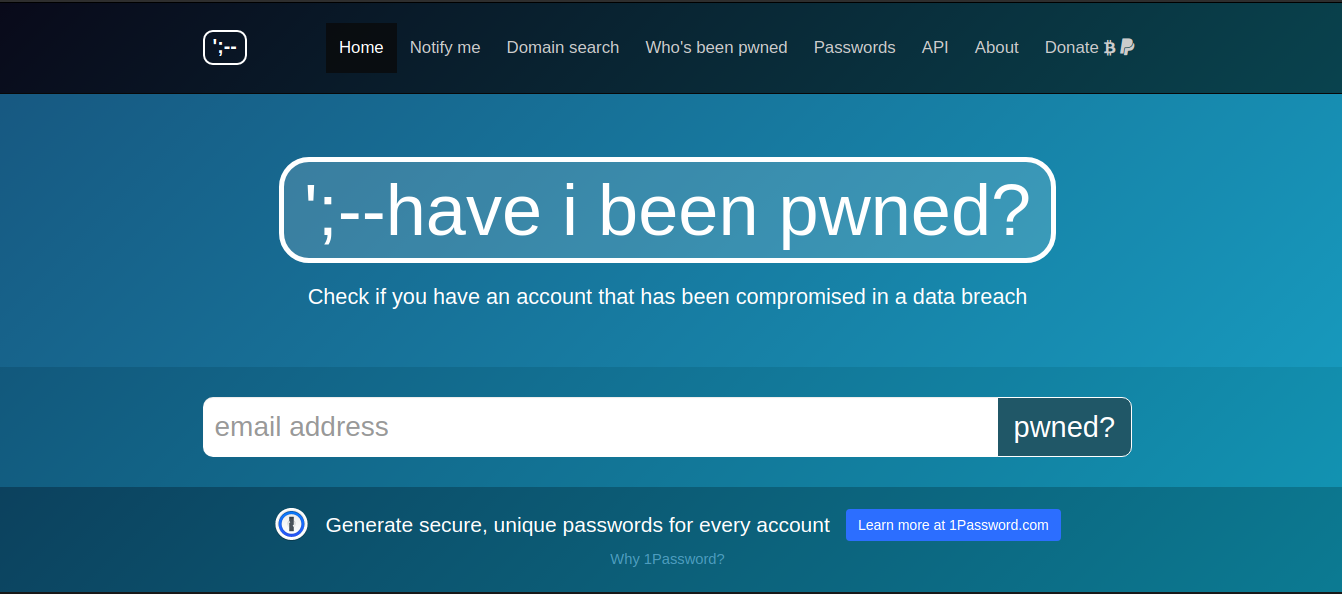
https://haveibeenpwned.com/は、アカウントデータ(電子メールアドレス、ログイン、パスワード、およびその他のデータ)が収集されたセキュリティが不十分なWebページを指します。現在、データベースには50億を超えるアカウントが含まれています。https://dehashed.comで、ユーザー名、電子メールアドレス、パスワードとそのハッシュ、IPアドレス、名前、電話番号で情報を検索するためのより高度なツールを利用できます。さらに、リークされたアカウントはオンラインで購入できます。1日のアクセスはたったの2ドルです。
結論
Google Dorkingは、機密情報の収集とその分析プロセスの不可欠な部分です。これは当然のことながら、最もルートで主要なOSINTツールの1つと見なすことができます。 Google Dorkingのオペレーターは、自分のサーバーのテストと、潜在的な被害者に関するすべての可能な情報の検索の両方を支援します。これは確かに、特定の情報を探索する目的で検索エンジンを正しく使用した非常に印象的な例です。ただし、このテクノロジーを使用する意図が良い(自分のインターネットリソースの脆弱性をチェックする)か、不親切(さまざまなリソースから情報を検索して収集し、違法な目的で使用する)かは、ユーザーが決定するだけです。
代替方法と自動化ツールは、Webリソースを分析するためのさらに多くの機会と利便性を提供します。BinGooなどの一部は、Bingの通常のインデックス付き検索を拡張し、追加のツール(SqlMap、Fimap)を介して受信したすべての情報を分析します。次に、選択したWebリソースのセキュリティに関するより正確で具体的な情報を表示します。
同時に、オンラインプラットフォームが適切に保護され、本来あるべきではない場所にインデックスが作成されないようにする方法を理解し、覚えておくことが重要です。また、各Web管理者に提供される基本的な規定も順守してください。結局のところ、他の人が自分の間違いであなたの情報を入手したという無知と無意識は、すべてが以前のように返されることを意味するわけではありません。