私たちは理解し、創造します
記事の前の良いニュース:高い数学のスキルは、読んで(うまくいけば!)理解する必要はありません。
免責事項:この記事のコード部分は、前の記事と同様に、適合、補足、およびテストされた翻訳です。これは私の最初のコード体験の1つであり、その後さらに多くの人が殺到したため、著者に感謝します。私の適応があなたのために同じように働くことを願っています!
じゃ、行こう!
構造は次のようになります。
- マルコフチェーンとは何ですか?
- チェーンの仕組みの例
- 遷移マトリックス
- Pythonを使用したマルコフチェーンモデル-データ駆動型テキスト生成
マルコフチェーンとは何ですか?
マルコフチェーンは、ランダムプロセスの理論からのツールであり、n個の状態のシーケンスで構成されます。この場合、チェーンのノード(値)間の接続は、状態が厳密に隣接している場合にのみ作成されます。ファットタイプの単語のみを念頭に置いて、マルコフチェーンのプロパティを推測しましょう。チェーン内の特定の新しい状態の確率は現在の状態のみに依存し、過去の状態の経験を数学的に考慮しません=>マルコフチェーンはメモリのないチェーンです。 言い換えれば、新しい意味は常にハンドルで直接それを保持するものから踊ります。
チェーンの仕組みの例
コード実装を借用した記事の著者のように、ランダムな単語のシーケンスを見てみましょう。
開始-人工-毛皮のコート-人工-食品-人工-パスタ-人工-毛皮のコート-人工-終了
これが実際に素晴らしい詩であり、私たちの仕事が著者のスタイルをコピーすることであると想像してみましょう。(しかし、もちろんそうすることは非倫理的です)
どうやって決めるの?
私がやりたい最初の明白なことは、単語の頻度を数えることです(ライブテキストでこれを行う場合、最初に正規化する価値があります-各単語を補題(辞書形式)にします)。
開始== 1
人工== 1
毛皮コート== 2
パスタ== 1
食品== 1
終了== 1
マルコフチェーンがあることを念頭に置いて、前の単語に応じて新しい単語の分布をグラフィカルにプロットできます

。
- 毛皮のコート、食べ物、パスタの状態は100%人工的なp = 1の状態を伴います
- 「人工」状態は、同じ確率で4つの条件につながる可能性があり、人工毛皮のコートの状態になる確率は、他の3つよりも高くなります。
- 終了状態はどこにもつながりません
- 状態「開始」100%は状態「人工」を伴います
クールで論理的に見えますが、視覚的な美しさはそれだけではありません。遷移行列を作成することもでき、それに基づいて次の数学的正義を訴えることができます:

ロシア語で「iに応じたイベントkの一連の確率の合計==状態iの発生に応じたイベントkの確率のすべての値の合計、ここでイベントk == m + 1、およびイベントi == m(つまり、イベントkは常にiと1つ異なります)」。
しかし、最初に、マトリックスが何であるかを理解しましょう。
遷移マトリックス
マルコフチェーンを扱うときは、確率的遷移行列(ベクトルのセット)を扱います。その中で、値はグラデーション間の確率の値を反映します。
はい、はい、それは聞こえるように聞こえます。
しかし、それほど怖くはありません

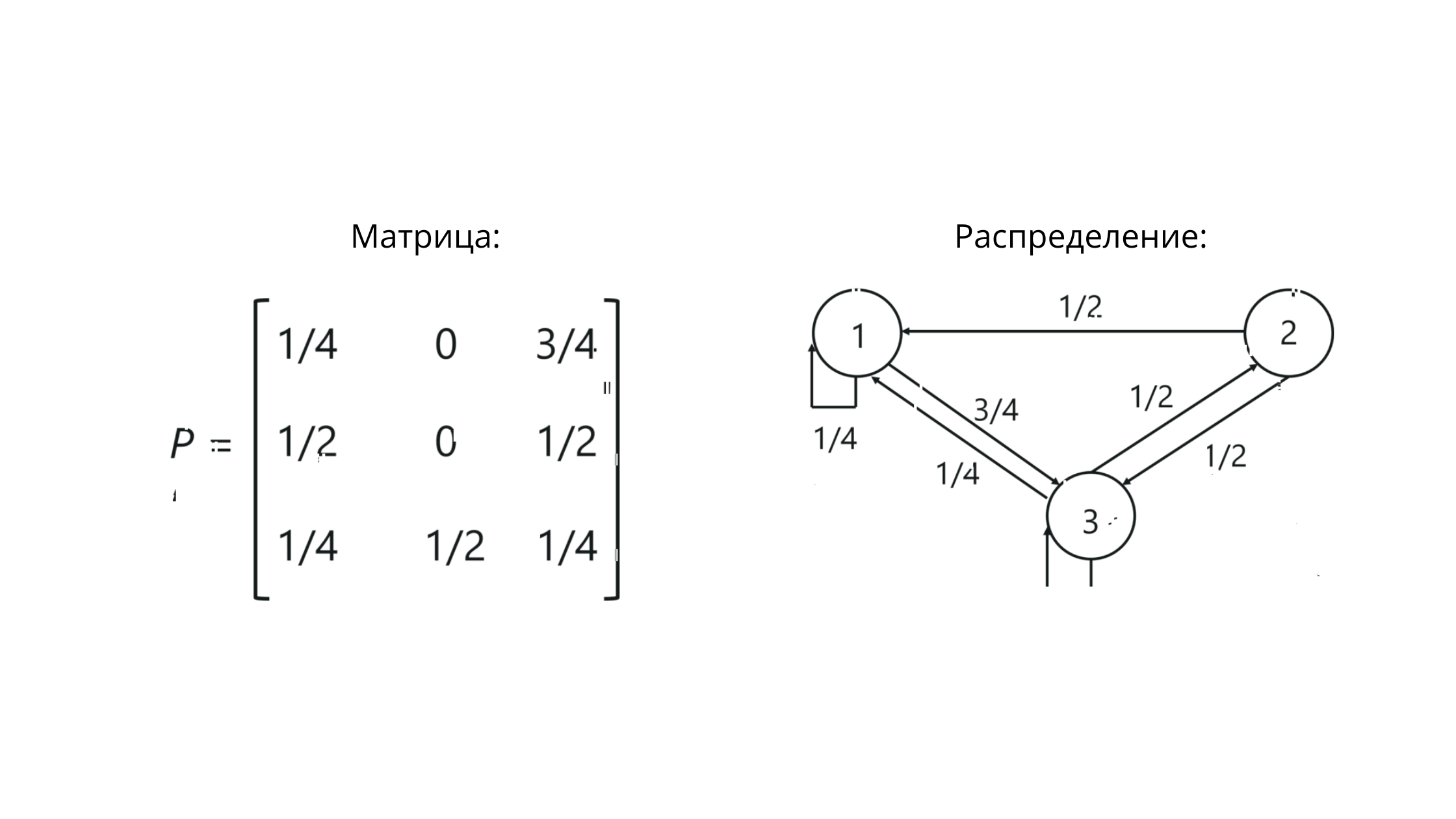
。Pは行列の表記です。ここでの列と行の交点の値は、状態間の遷移の確率を反映しています。
この例では、次のようになります

。行の値の合計== 1であることに注意してください。これは、確率行列の行の値の合計が1に等しくなければならないため、すべてが正しく構築されたことを意味します。
フェイクファーコートとペーストの
ない裸の例:さらに裸の例は、次のIDマトリックスです。
- AからBに戻ることが不可能な場合、およびBからAに戻ることが不可能な場合[1]
- AからBへの移行が可能な場合[2]

リスペクト。理論が終了しました。
Pythonを使用しています。
Pythonを使用したマルコフチェーンに基づくモデル-データに基づいてテキストを生成する
ステップ1
作業用の関連パッケージをインポートし、データを取得します。
import numpy as np
data = open('/Users/sad__sabrina/Desktop/1.txt', encoding='utf8').read()
print(data)
, , , , ( « memorylessness »). , , , , , , ; .., , .
テキストの構造に焦点を当てるのではなく、utf8エンコーディングに注意してください。これは、データを読み取るために重要です。
ステップ2
データを単語に分割します。
ind_words = data.split()
print(ind_words)
['\ufeff', '', '', '', '', ',', '', '', ',', '', '', '', '', '', '', '', ',', '', '', '', ',', '', '', '', '', '(', '', '', '«', 'memorylessness', '»).', '', ',', '', '', '', '', ',', '', '', '', '', '', '', '', ',', '', '', '', '', '', '', '', '', '', ',', '', '', '', '', '', '', '', ',', '', '', ',', '', '', '', ';', '..,', '', '', '', '', ',', '', '', '', '', '', '', '.']ステップ3
単語のペアをリンクする関数を作成しましょう。
def make_pairs(ind_words):
for i in range(len(ind_words) - 1):
yield (ind_words[i], ind_words[i + 1])
pair = make_pairs(ind_words)関数の主なニュアンスは、yield()演算子の使用にあります。これは、マルコフ連鎖基準(メモリレスストレージ基準)を満たすのに役立ちます。イールドを使用すると、関数はすべてを保存するのではなく、反復(繰り返し)するときに新しいペアを作成します。
1つの単語が別の単語に変わる可能性があるため、ここで誤解が生じる可能性があります。関数の辞書を作成することでこれを解決します。
ステップ4
word_dict = {}
for word_1, word_2 in pair:
if word_1 in word_dict.keys():
word_dict[word_1].append(word_2)
else:
word_dict[word_1] = [word_2]ここに:
- ディクショナリのペアの最初の単語に関するエントリがすでにある場合、関数は次の潜在的な値をリストに追加します。
- それ以外の場合:新しいエントリが作成されます。
ステップ5
最初の単語をランダムに選択し、単語を真にランダムにするには、islower()文字列メソッドを使用してwhile条件を設定します。これは、文字列に小文字が含まれている場合にTrueを満たし、数字または記号の存在を許可します。
この場合、ワード数を20に設定します。
first_word = np.random.choice(ind_words)
while first_word.islower():
chain = [first_word]
n_words = 20
first_word = np.random.choice(ind_words)
for i in range(n_words):
chain.append(np.random.choice(word_dict[chain[-1]]))ステップ6
ランダムなことを始めましょう!
print(' '.join(chain))
; .., , , (join()関数は、文字列を操作するための関数です。括弧内に、行(スペース)の値の区切り文字を指定しました。
そしてテキスト...まあ、それは機械のように聞こえ、ほとんど論理的です。
PSお気づきかもしれませんが、マルコフチェーンは言語学に役立ちますが、そのアプリケーションは自然な言語処理を超えています。こことここで、他のタスクでのチェーンの使用に慣れることができます。
PPS私のコードの練習があなたに理解できないことが判明した場合、私は元の記事を添付しています。必ず実際にコードを適用してください-「実行されて生成された」ときの感覚は充電されています!
ご意見をお待ちしております。記事に建設的なコメントをいただければ幸いです。