しかし、データサイエンティストの仕事はデータと結びついており、最も重要で時間のかかる瞬間の1つは、データをニューラルネットワークに送信したり、特定の方法で分析したりする前にデータを処理することです。
この記事では、私たちのチームが、ステップバイステップの手順とコードを使用してデータをすばやく簡単に処理する方法について説明します。さまざまなデータセットに適用できるように、コードを十分に柔軟にしようとしました。
多くの専門家はこの記事で特別なことを何も見つけないかもしれませんが、初心者は何か新しいことを学ぶことができ、高速で構造化されたデータ処理のために別のノートブックを作ることを長い間夢見ていた人は誰でもコードをコピーして自分でフォーマットするか、既製のものをダウンロードできます。 Githubのノートブック。
データセットを取得しました。次はどうする?
つまり、標準:私たちが何を扱っているのか、全体像を理解する必要があります。これにはパンダを使用して、さまざまなデータタイプを簡単に定義します。
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 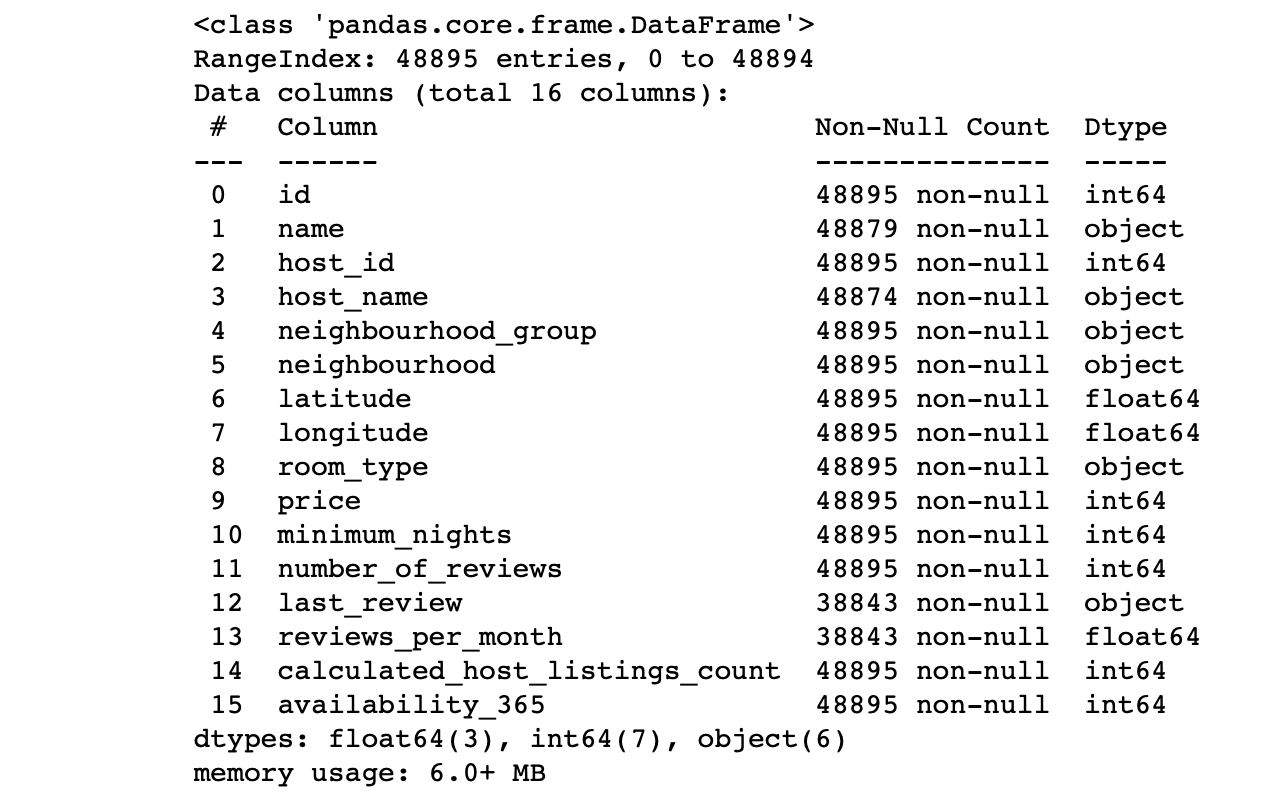
列の値を確認します:
- 各列の行数は合計行数に対応していますか?
- 各列のデータの本質は何ですか?
- どの列をターゲットにして予測を行いますか?
これらの質問への回答により、データセットを分析し、次のステップの計画を大まかに描くことができます。
また、各列の値を詳しく調べるために、パンダのdescribe()関数を使用できます。ただし、この関数の欠点は、文字列値を持つ列に関する情報を提供しないことです。後で扱います。
df.describe()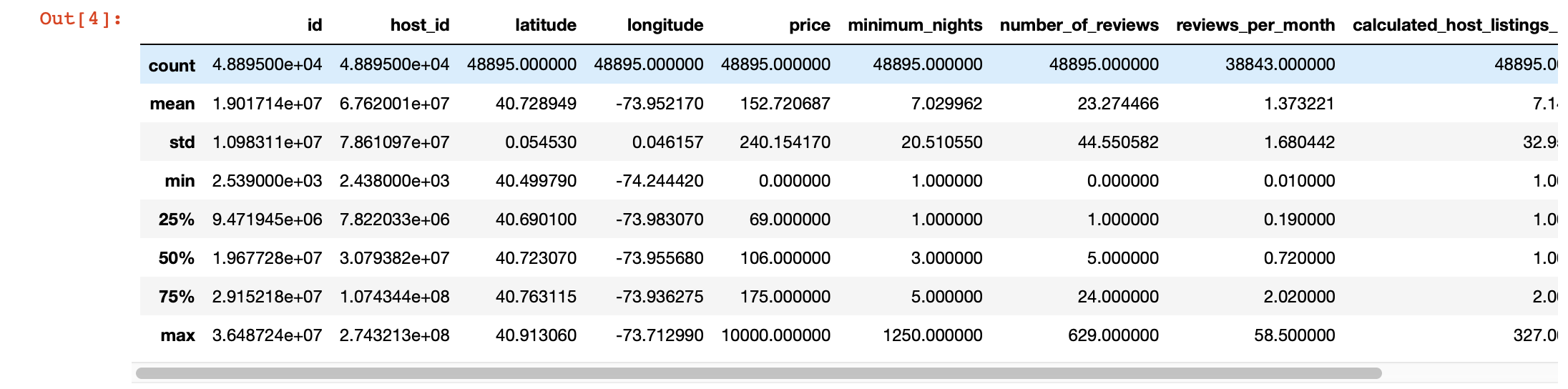
魔法の視覚化
値がまったくない場所を見てみましょう:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')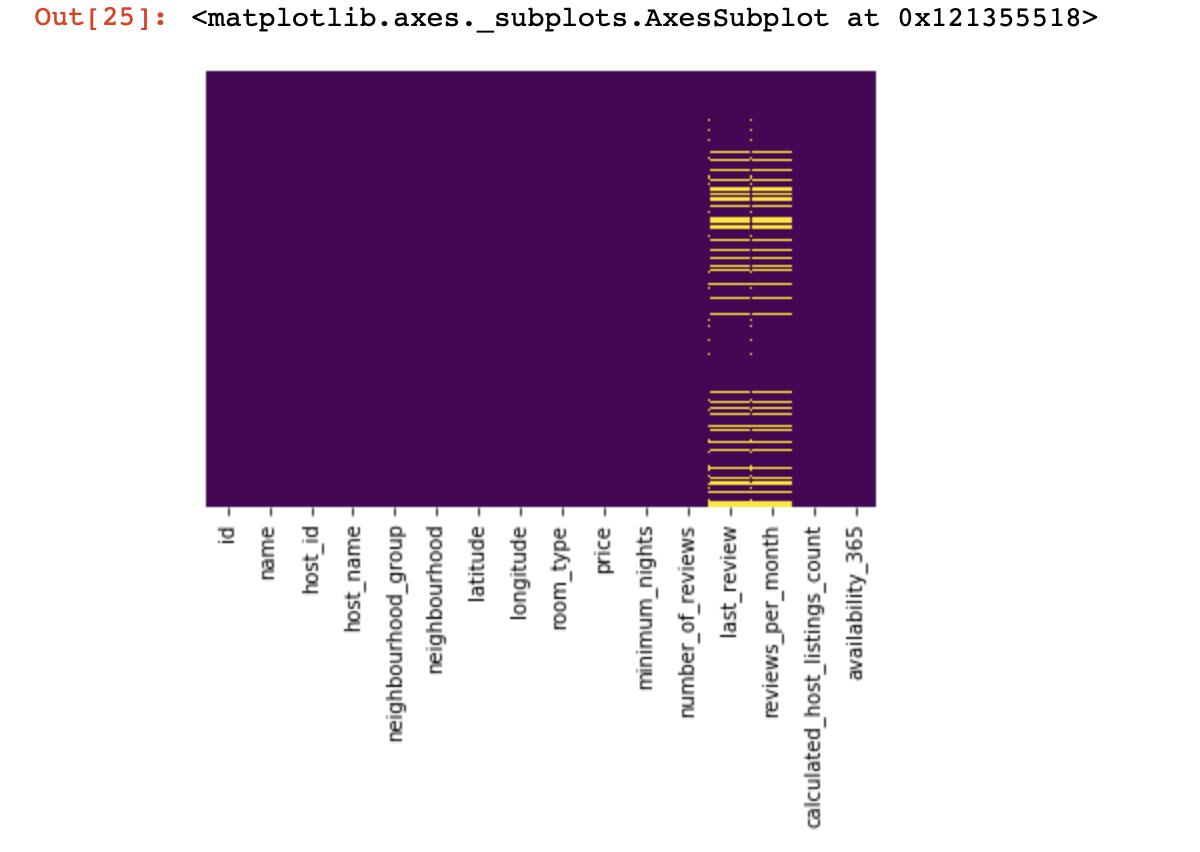
上から見た小さな外観でしたが、次にもっと興味深いことに進み
ます。可能であれば、すべての行で値が1つしかない列を見つけて削除してみましょう(結果にはまったく影響しません)。
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , これで、重複した行(既存の行の1つと同じ順序で同じ情報を含む行)から自分自身とプロジェクトの成功を保護します。
df.drop_duplicates(inplace=True) # , .
# .データセットを2つに分割します。1つは定性的な値で、もう1つは定量的な値です。
ここで、簡単に説明する必要があります。定性的データと定量的データでデータが欠落している行が互いに強く相関していない場合は、何を犠牲にするかを決定する必要があります。データが欠落しているすべての行、それらの一部のみ、または特定の列です。行が関連している場合、データセットを2つに分割する権利があります。それ以外の場合は、最初に、欠落しているデータを定性的および定量的に相関させない行を処理してから、データセットを2つに分割する必要があります。
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])これは、これら2つの異なるタイプのデータを簡単に処理できるようにするためです。後で、それが私たちの生活をどれだけ簡素化するかを理解します。
定量的なデータを扱います
最初にすべきことは、定量的データに「スパイ列」があるかどうかを判断することです。これらの列は、定量的なデータを装い、それ自体が定性的なデータとして機能するため、これと呼びます。
それらをどのように定義しますか?もちろん、それはすべて分析しているデータの性質に依存しますが、一般に、そのような列には固有のデータがほとんどない場合があります(3〜10個の固有の値の範囲)。
print(df_numerical.nunique())スパイ列を定義したら、それらを定量的データから定性的データに移動します。
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - 最後に、定量的データと定性的データを完全に分離し、それらを適切に処理できるようになりました。1つ目は、空の値がある場所を理解することです(NaN、場合によっては0が空の値と見なされます)。
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())この段階で、ゼロが欠落した値を意味する可能性がある列を理解することが重要です。これは、データの収集方法に関連していますか?それとも、データ値に関連している可能性がありますか?これらの質問には、ケースバイケースで回答する必要があります。
したがって、それでもゼロがあるデータがない可能性があると判断した場合は、ゼロをNaNに置き換えて、後でこの失われたデータを簡単に処理できるようにする必要があります。
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)次に、不足しているデータがどこにあるかを見てみましょう。
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()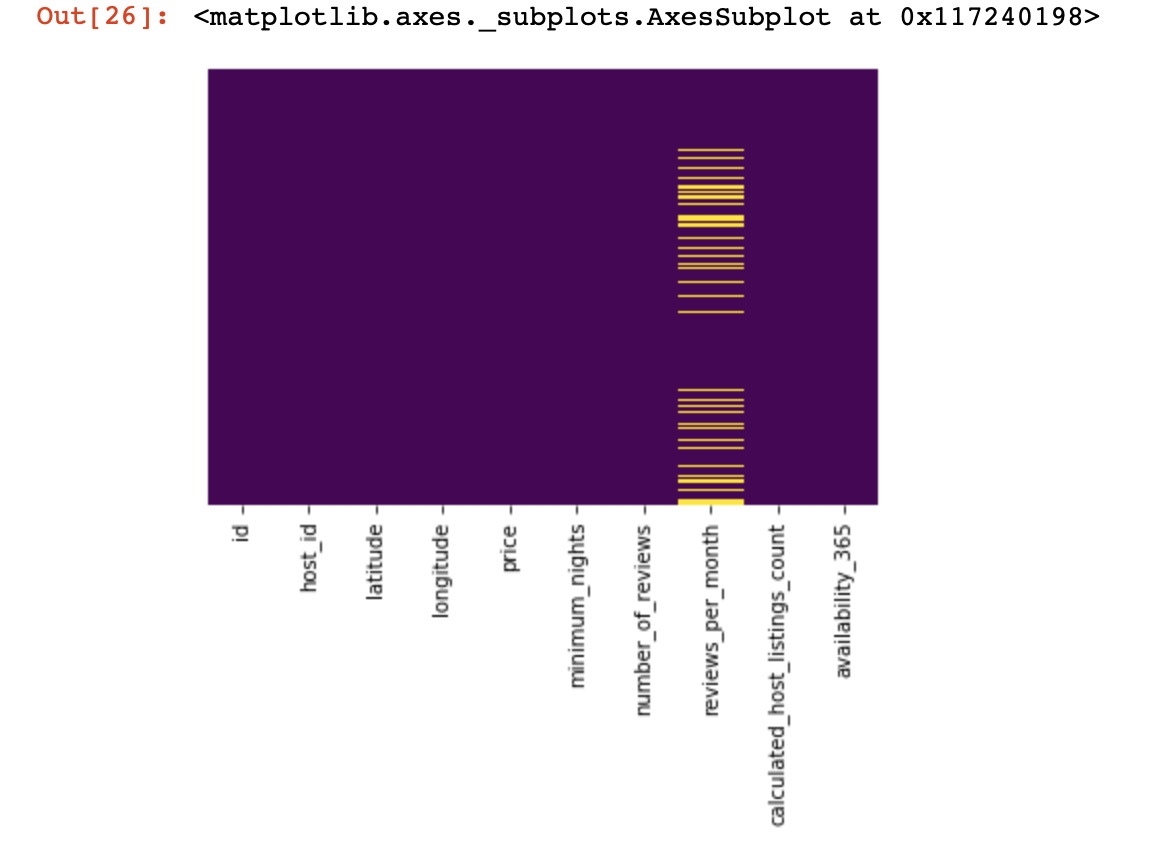
ここで、欠落している列内の値は黄色でマークする必要があります。そして、楽しみは今始まります-これらの値でどのように振る舞うか?これらの値または列を持つ行を削除しますか?または、これらの空の値を他のもので埋めますか?
これは、空の値で基本的に何ができるかを判断するのに役立つ大まかな図です
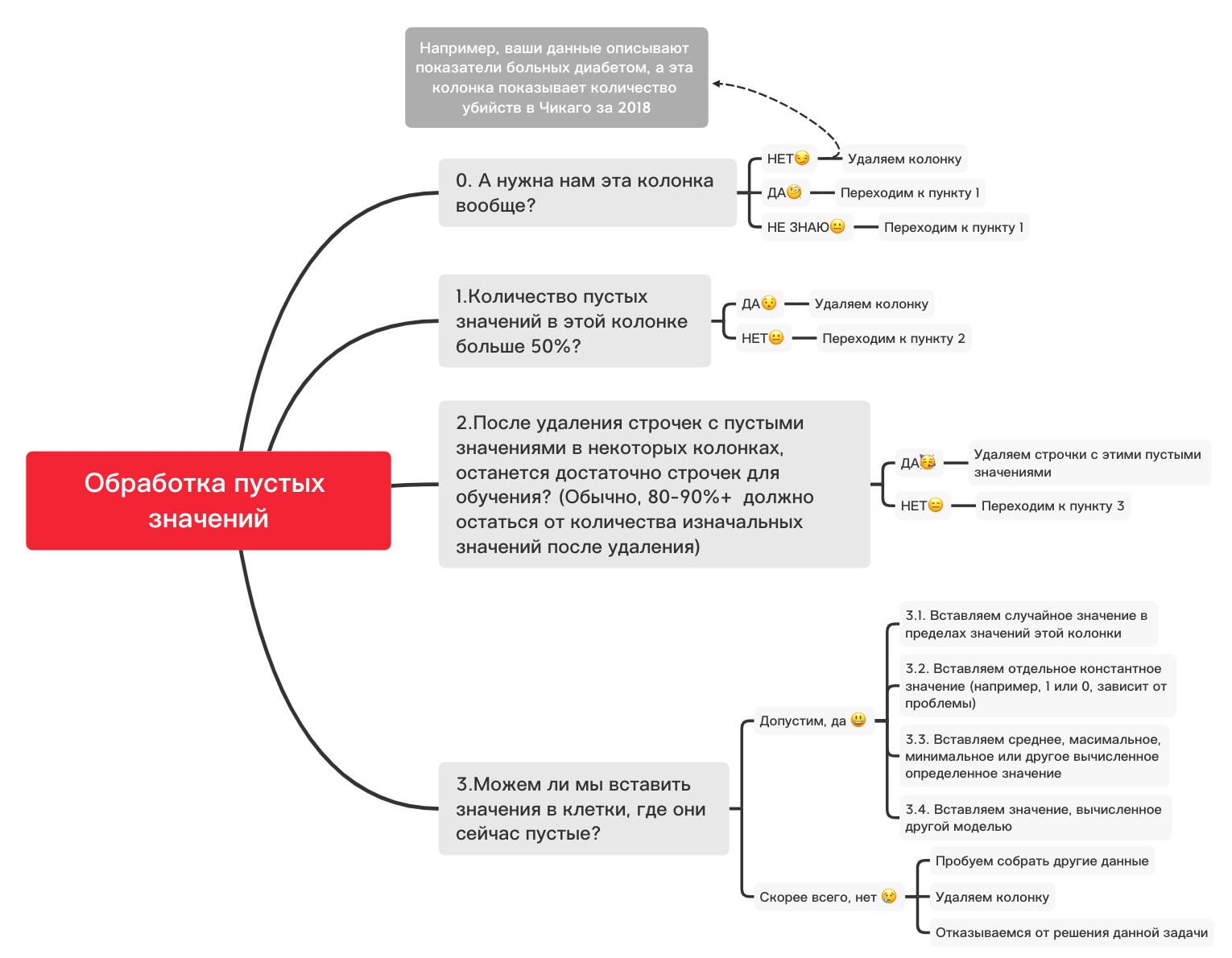
。0。不要な列を削除します
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1.この列に50%を超える空白値がありますか?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2.値が空の行を削除します
df_numerical.dropna(inplace=True)# , 3.1。ランダムな値を挿入します
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2。定数値を挿入
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3。平均値または最も頻度の高い値を挿入します
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4。別のモデルで計算された値の挿入
値は、sklearnライブラリまたは他の同様のライブラリのモデルを使用した回帰モデルを使用して計算できる場合があります。私たちのチームは、近い将来、これをどのように行うことができるかについて、別の記事を捧げます。
したがって、定量的データに関する説明は中断されますが、さまざまなタスクのデータ準備と前処理をより適切に行う方法については他にも多くのニュアンスがあり、この記事では定量的データの基本的な事項が考慮されているため、今が定性的データに戻るときです。これは、定量的から数歩後退しています。このノートブックを好きなように変更して、さまざまなタスクに合わせて調整できるため、データの前処理が非常に迅速に行われます。
定性的データ
基本的に、高品質のデータの場合、文字列(またはオブジェクト)から数値にフォーマットするために、ワンホットエンコーディング方式が使用されます。この点に進む前に、空の値を処理するために上記の図とコードを使用しましょう。
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')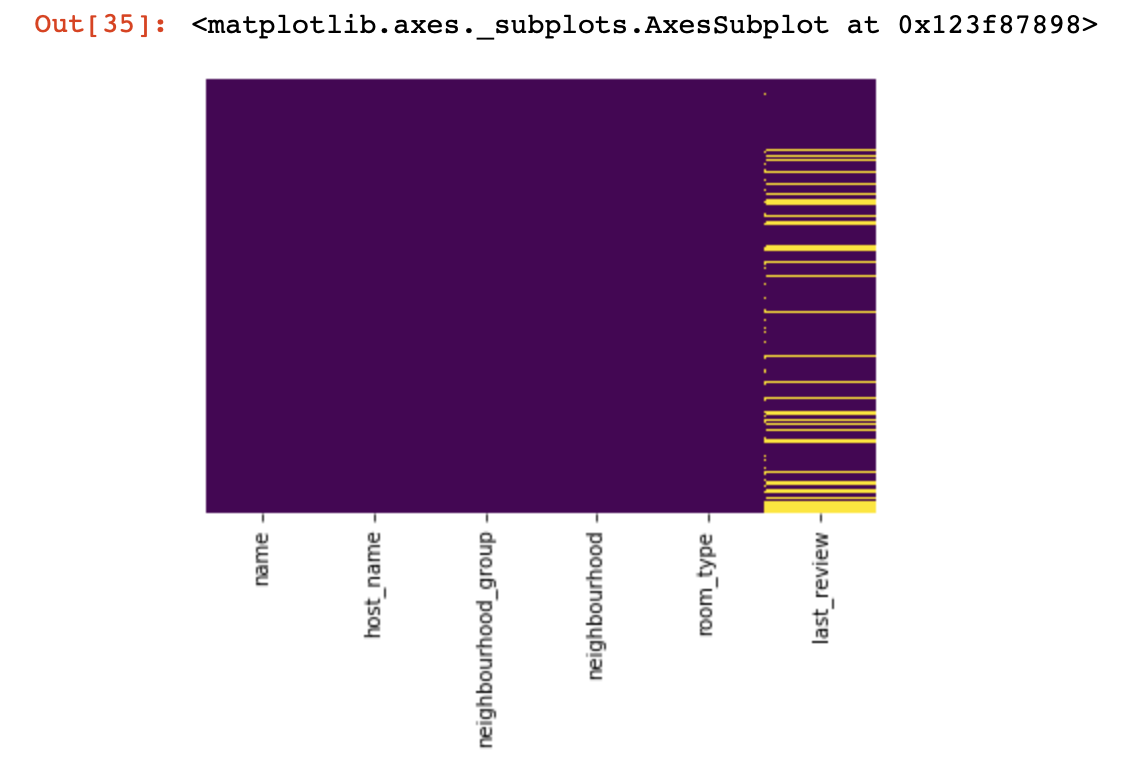
0.不要な列を削除する
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1.この列に50%を超える空白値がありますか?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2.値が空の行を削除します
df_categorical.dropna(inplace=True)# ,
# 3.1。ランダムな値を挿入します
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2。定数値を挿入
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)したがって、最後に、品質データの空の値を処理しました。今こそ、データベースにある値をワンホットエンコードするときです。この方法は、アルゴリズムが高品質のデータでトレーニングできるようにするためによく使用されます。
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))それで、最終的に、定性的データと定量的データを別々に処理し終えました-それらを組み合わせる時が来ました
new_df = pd.concat([df_numerical,df_categorical], axis=1)データセットを1つにマージした後、最終的にはsklearnライブラリのMinMaxScalerを使用してデータ変換を使用できます。これにより、値が0から1の間になり、将来モデルをトレーニングするときに役立ちます。
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)このデータは、ニューラルネットワーク、標準のMLアルゴリズムなど、あらゆるものに対応できるようになりました。
この記事では、時系列に関連するデータの作業は考慮しませんでした。そのようなデータの場合、タスクに応じてわずかに異なる処理手法を使用する必要があるためです。将来的には、私たちのチームはこのトピックに別の記事を捧げます。そして、このような興味深い、新しくて役立つものをあなたの人生にもたらすことができることを願っています。