したがって、数千の制御対象サーバーの1つでリソース(CPU、メモリ、ディスク、ネットワークなど)の異常な消費が発生した場合、「誰が責任を負い、何をすべきか」を把握する必要があります。
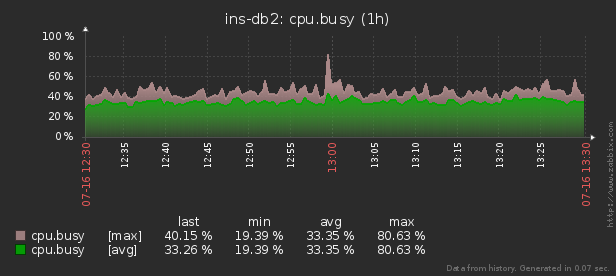
pidstatユーティリティは 、「現時点」でLinuxサーバーのリソース使用量をリアルタイムで監視するために使用できます。つまり、負荷のピークが周期的である場合、コンソールで直接「ハッチング」することができます。しかし、事後にこのデータを分析して、リソースに最大の負荷をかけたプロセスを見つけようとしています。
つまり、以前に収集したデータを、次のような間隔でグループ化および詳細化して、さまざまな美しいレポートで確認できるようにしたいと思います
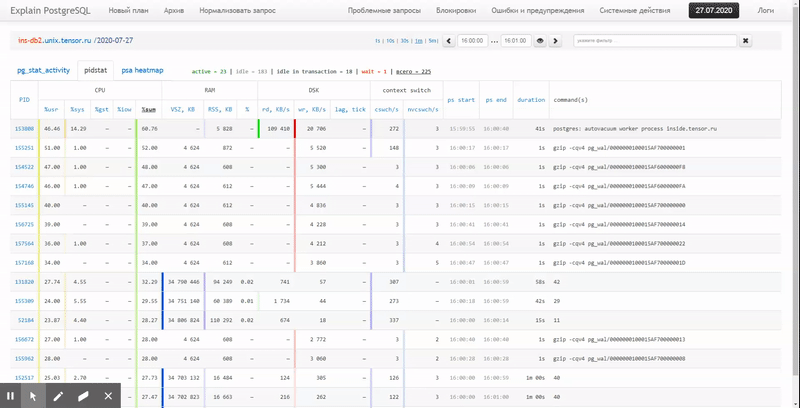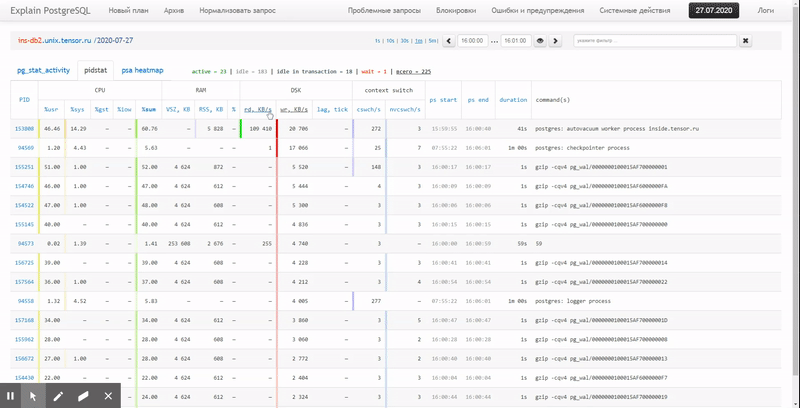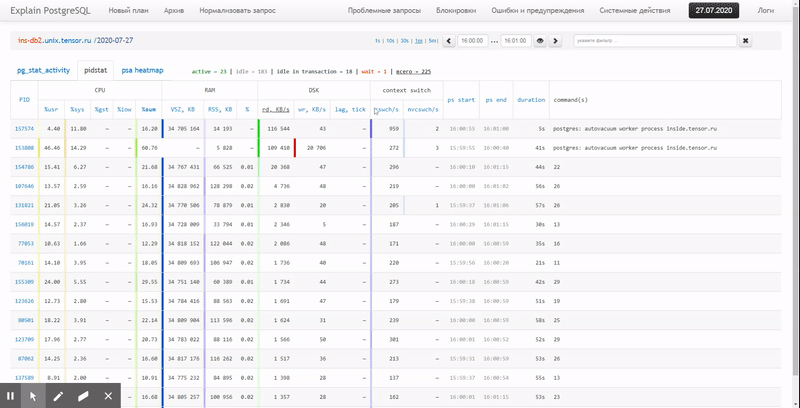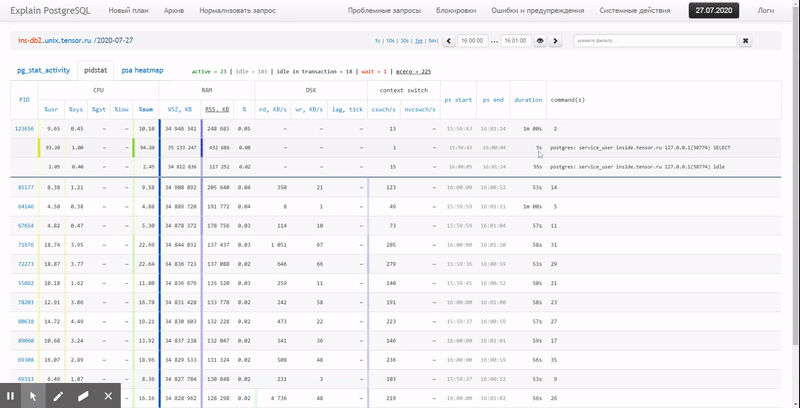
。この記事では、これらすべてをデータベースに経済的に配置する方法と、ウィンドウ関数を使用してこのデータからレポートを最も効果的に収集する方法を検討します。グループ化セット。
まず、「すべてを最大限に活用」した場合に抽出できるデータの種類を見てみましょう。
pidstat -rudw -lh 1| 時間 | UID | PID | %usr | %システム | %ゲスト | % CPU | CPU | minflt / s | majflt / s | VSZ | RSS | %MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | コマンド |
| 1594893415 | 0 | 1 | 0.00 | 13.08 | 0.00 | 13.08 | 52 | 0.00 | 0.00 | 197312 | 8512 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | ナイン | 0.00 | 0.93 | 0.00 | 0.93 | 40 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 350.47 | 0.00 | rcu_sched |
| 1594893415 | 0 | 13 | 0.00 | 0.00 | 0.00 | 0.00 | 1 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 1.87 | 0.00 | 移行/11.87 |
これらの値はすべて、いくつかのクラスに分けられます。それらのいくつかは絶えず変化し(CPUとディスクのアクティビティ)、他はめったに変化せず(メモリ割り当て)、コマンドは同じプロセス内でめったに変化しないだけでなく、異なるPIDで定期的に繰り返されます。
基本構造
簡単にするために、節約する「クラス」ごとに1つのメトリック(%CPU、RSS、およびコマンド)に制限しましょう。
Commandが定期的に繰り返されることが事前にわかっているので、コマンドを別のテーブル辞書に移動するだけです。ここで、MD5ハッシュがUUIDキーとして機能します。
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);また、データ自体については、このタイプのテーブルが適しています。
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);%CPUは常に小数点以下2桁の精度で到達し、確かに100.00を超えないため、100を掛けて簡単に入力できることに注意してください
smallint。これにより、操作中のアカウンティングの精度の問題から私たちを救うことができますが、4バイトrealまたは8バイトよりも2バイトだけを保存する方がよいでしょうdouble precision。
PostgreSQLストレージにレコードを効率的にパックする方法の詳細については、「大量にかなりの金額を節約する」の記事と、書き込み用のデータベーススループットを向上させる方法についての記事「サブライトでの書き込み:1ホスト、1日、1TB」を参照してください。
NULLの「無料」ストレージ
データベースのディスクサブシステムのパフォーマンスとデータベースのサイズを節約するために、できるだけ多くのデータをNULLの形式で表現しようとします。これらのストレージは、レコードヘッダーに少ししかかからないため、実質的に「空き」です。
PostgreSQLでレコードを表現する内部メカニズムの詳細については、PGConf.Russia2016でのNikolaiShaplovの講演「その中身:低レベルのデータストレージ」を参照してください。スライド#16はNULLストレージ専用です。データの種類を詳しく見てみましょう。
- CPU / DSKは
絶えず変化しますが、非常に頻繁にゼロになります。したがって、ベースに0ではなくNULLを書き込むと便利です。 - RSS / CMD
変更されることはめったにありません。したがって、同じPID内で繰り返す代わりにNULLを書き込みます。
特定のPIDのコンテキストで見ると、次のような図になり

ます。プロセスが別のコマンドを実行し始めると、使用されるメモリの値も以前とは異なる可能性があることは明らかです。したがって、CMDを変更すると、RSSの値も異なることに同意します。以前の値に関係なく修正します。
つまり、CMD値が入力されたエントリには、RSS値も含まれます。この瞬間を思い出してみましょう、それは私たちにとってまだ役に立ちます。
美しいレポートをまとめる
次に、特定の時間間隔で特定のホストのリソースコンシューマーを表示するクエリをまとめましょう。
ただし、SELF JOINとウィンドウ関数に関する記事と同様に、最小限のリソースを使用してすぐに実行しましょう。
着信パラメータの使用
SQLクエリ中にいくつかの場所でレポートパラメータ(または$ 1 / $ 2)の値を指定しないために、これらのパラメータがキーによって配置されている唯一のjsonフィールドからCTEを選択します:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
生データの取得
複雑な集計を発明しなかったため、データを分析する唯一の方法はデータを読み取ることです。このためには、明らかなインデックスが必要です。
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
分析キーのグループ化
見つかったPIDごとに、そのアクティビティの間隔を決定し、この間隔の最初のレコードからCMDを取得します。
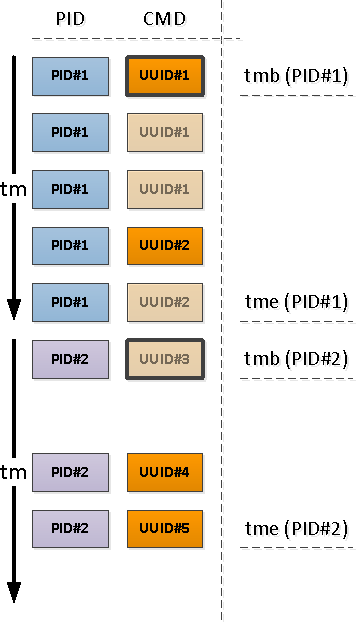
これを行うには、一意化スルー
DISTINCT ONおよびウィンドウ関数を使用します。
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
プロセスアクティビティの制限
間隔の開始に関連して、最初に出くわすレコードは、すでにCMDフィールドが入力されているレコード(上の図のPID#1)か、時系列で入力された「上」の値の継続を示すNULL(PID#2)のいずれかであることに注意してください。 )。
前の操作の結果としてCMDなしで残されたPIDは、間隔の開始よりも早く開始されました。つまり、これらの「始まり」を見つける必要があります。

アクティビティの次のセグメントが塗りつぶされたCMD値で始まることが確実にわかっているためです(つまり、塗りつぶされたRSSがあります。 )、条件付きインデックスはここで役立ちます:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
セグメントのアクティビティの終了時刻を知りたい(そして知りたい)場合は、各PIDについて、「双方向」を使用して下限を決定する必要があります。
PostgreSQLアンチパターンで同様の手法をすでに使用しています:レジストリナビゲーション。

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
投稿フォーマットのJSON変換
precmd/pstcmd後続の行に影響を与えるフィールドと、絶えず変化するCPU / DSKのみ
を選択したことに注意してください-いいえ。したがって、元のテーブルとこれらのCTEのレコードの形式は私たちにとって異なります。問題ない!
- row_to_json-フィールドを持つ各レコードをjsonオブジェクトに変換します
- array_agg -'{...}'のすべてのエントリを収集します:: json []
- array_to_json -array-from-JSONをJSON-arrayに変換します '[...]' :: json
- json_populate_recordset -JSON配列から特定の構造の選択を生成します
ここでは見つかった「始まり」と「終わり」を共通のヒープに接着し、元のレコードのセットに追加します。json_populate_recordset、複数の呼び出しではなく単一の呼び出しを使用しますjson_populate_record。これは、ときどき高速になるためです。
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
ヌルギャップを埋める
記事「SQLHowTo:ウィンドウ関数を使用してチェーンを構築する」で説明されているモデルを使用してみましょう。まず、「リピート」グループを選択しましょう。
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
さらに、CMDとRSSによると、グループは互いに独立しているため、次のように
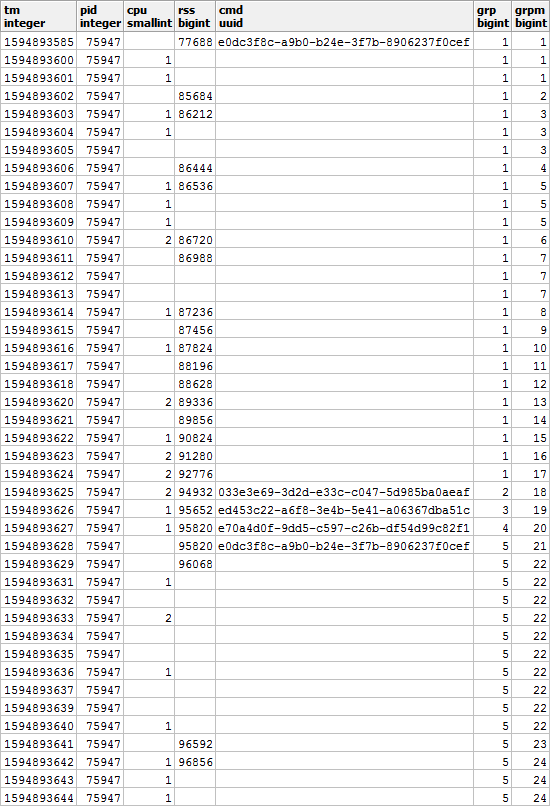
なります。RSSのギャップを埋め、各セグメントの期間を計算して、時間の経過に伴う負荷分散を正しく考慮します。
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
グループ化セットを使用したマルチグループ化
結果として、プロセス全体の要約情報とアクティビティのさまざまなセグメントによる詳細の両方を確認したいので、GROUPINGSETSを使用して一度に複数のキーセットによるグループ化を使用します。
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
このユースケースでは(array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]、追加のジェスチャなしで、グループ化時にセット全体から最初の空でない(最初ではない場合でも)値を取得できます。ターゲットサンプルの複数のセクションを一度に取得するオプションは、詳細を含むさまざまなレポートを生成するのに非常に便利です。そのため、すべての詳細データを再構築する必要はありませんが、メインサンプルと一緒にUIに入ります。
JOINの代わりに辞書
見つかったすべてのセグメントのCMD「辞書」を作成します。
「マスタリング」手法の詳細については、記事「PostgreSQLアンチパターン:辞書を使用して重いJOINをヒットしましょう」を参照してください。
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
そして今
JOIN、代わりにそれを使用して、最終的な「美しい」データを取得します。
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
最後に、実行時にクエリ全体が非常に軽量であることが判明したことを確認しましょう。

[explain.tensor.ruを見てください]
44msと33MBのデータのみが読み取られました!