この記事は、私自身、学生、研修生、好奇心旺盛な同僚に、このトピックを日常の言葉でできるだけ単純かつ透過的に説明しようとした経験に基づいて作成されました。私はこのトピックに関する研究やトレーニングなしでFPGAを操作することを学びました。私自身の経験から、このトピックと回路の理論的根拠なしに何かを理解することがいかに難しいかを知っています。経験豊富なブリーダーにとって、上記は初歩的なものです。しかし、一部の4年生の学生にとって、この記事は有用であり、これらすべての緩み、設定、および保留を理解するのに役立ちます。
この記事では、英語版を括弧で囲んだ用語を使用します。これは、単一の用語が確立されていないために行われます。重複すると、どの概念が議論されているかを理解し、必要に応じて英語のソースでその情報を見つけることが容易になります。
前書き
簡単な概念の言語で簡単に紹介します。
FPGAで何かが機能するためには、プログラマーとファームウェアユーティリティを使用して、ファームウェアファイルをFPGAにロード(アップロード、縫製)する必要があります。ファームウェアファイルは、特定のプロジェクトのCADコンパイルの結果であり、ファイルを含むフォルダーであり、各フォルダーはプロジェクトのいくつかの側面を記述します。単純なケースでは、ユーザー自身がソースコード付きのファイル、ピン配置付きのファイル、および時間制限付きのファイルのみを記述します。残りのファイルはCADによって静かに処理されます。このトライアドのうち、時間制約ファイルのみが正式にオプションです。プロジェクトの一部。実際、プロジェクトに30〜50 MHzを超える周波数が含まれていない場合は、このファイルがなくても何らかの形で機能する可能性があります。このオプションは、最初の教育プロジェクトを簡単に作成するのに適しています。ただし、トレーニングプロジェクトにすでに高いクロック周波数が含まれていて、時間制約ファイルが装備されていない場合、おそらくFPGA内のどこかでデータ処理が中断され、プロジェクトのどの時点であるかを見つけることができません。勉強ではなく仕事に関しては、制限の完全なファイルの記述が厳密に要求されます。プロジェクトの機能を検証および検証するのはあなたの責任です。
コンパイラはプロジェクトをFPGAチップに配置し、すべての物理要素の接続ファイルを受け取ります。タイミングアナライザは、接続ファイルを使用して、FPGAへのデータ転送のすべての期間を計算します。これらの期間は、無限に長くしたり、短すぎたりしないでください。時間制約のファイルは、これらの期間がどのフレームワークであるかをアナライザーに指示します。時間分析の結果を使用して、開発者は、プロジェクトのどの部分に時間、したがって頻度にマージンがあり、そのようなマージンがないかを確認できます。
同期システムは、同期クロック信号を使用してデータ処理作業を同期します。同期クロック信号は、用語では英語のクロックからのクロックと略されます。..。操作の中間結果は、クロック信号エッジの到着時の入力の状態を記憶し、次のクロックサイクルまで出力に保持できるレジスタに格納されます。
したがって、同期回路はレジスタ間データ転送(RTL、レジスタ転送ロジック、r2r転送)で構成されます。また、時間分析の重要な側面は、スラック(スラック)の測定にあります。この言葉は文字通り「時間予約」、「たるみ」と訳されますが、ロシア語圏の環境では、英語のトレースペーパーがよく使用されます-「たるみ」。レジスタ間転送では、プリセットスラック(セットアップ)とホールドスラック(ホールド)について説明します。
レジスタ間転送
レジスタ間転送(図1)は、一般的なケースでは同期クロックで動作する2つの順次接続されたレジスタのシステムと見なされます。単純なケースでは、1つのシュレッドに。 1つのレジスタはソース(ソース)の役割を果たし、もう1つのレジスタはデータの受信者(宛先)の役割を果たします。そして、次のレジスタ間転送では、この受信者レジスタはすでにソースなどと見なされます。データパス上のレジスタの間には、任意のユーザー定義の組み合わせロジックがあります。レジスタのように同期信号を持つメモリ要素がないため、非同期です。このロジックはその動作であり、ユーザーがコードで説明する論理操作です。レジスターは、ユーザーがコードで名前を付けて個別に操作する1ビットの「変数」です。またはベクトルと配列に結合します。
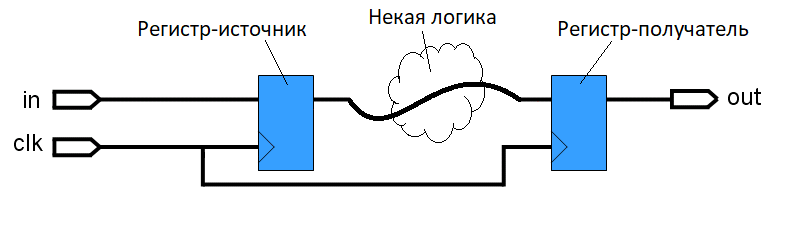
図: 1.レジスタからレジスタへのデータ転送のスキーム
受信レジスタによるデータの受信に関連する2つの概念があります。セットアップ時間とホールド時間間隔です。それらは、受信機の入力での信号が安定していて適切でなければならない時間の範囲を概説します。安定-本質的には、その電圧が2つの論理状態(「0」または「1」)のいずれかに非常に近く、混乱の可能性がある状態でぶら下がらないことを意味します。関連性-このビットの情報は、前のクロックからの遅いビットではなく、それをキャプチャするクロックのこのクロックに有意義に関連している必要があることを意味します。
セットアップ時間-プリセット時間。クロックフロントが到着する前に、データ信号がすでに安定状態に設定されている必要がある最小時間。
ホールドタイム-ホールドタイム。クロックフロントの到着後、データ信号を安定した状態に保持する必要がある最小時間。
つまり、レシーバーの入力のデータは、クロックフロントの到着時だけでなく、その周囲の特定の保護時間間隔(図2)でも、少なくともSetup_time + Hold_timeの期間で、安定していて最新である必要があります。この間隔の間にデータ安定条件が満たされた場合、レジスタは間違いなく着信データをキャプチャできます。そうでない場合、障害が発生しないことを保証する人は誰もいません。
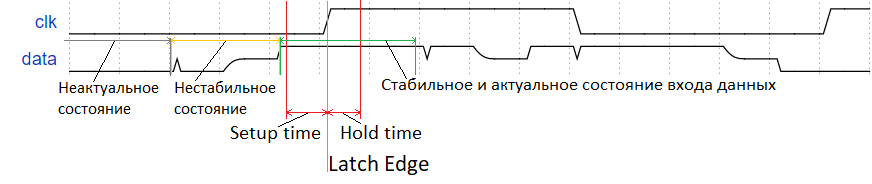
図: 2.レジスタのクロック入力でのキャプチャエッジ周辺のガード間隔としてのセットアップ時間とホールド時間
セットアップ時間とホールド時間の値は、FPGAメーカーによって厳密に定義されています。それらは結晶製造技術に依存し、分析の定数と見なされ、結晶の各レジスターで同じです。いずれにせよ、これらの値はユーザーにまったく依存しません;それらのアカウンティングは時間分析ユーティリティのみのタスクです。それらが何に等しいかを知ることは私たちにとって重要ではありません。それらが存在し、ゼロに等しくないことを知ることだけが重要です。
時間分析の本質は、プロジェクト内のレジスタの各ペアのスラックを計算することです。この間でデータが転送され、ガード期間中はデータが安定している必要があります。プロジェクトにはそのようなr2rペアが数千、さらには数百万もありますが、プロジェクトが機能することを確認するには、それぞれを分析する必要があります。
また、それぞれ2つのスラックがあります-セットアップスラックとホールドスラック(図3)。
セットアップスラックは、データが安定した瞬間からセットアップ時間間隔の開始までの時間マージンを特徴づけます。
ホールドスラックは、ホールド時間間隔の終了からデータによる安定性の喪失までのデータの時間マージンを特徴づけます。
たるみは正でなければなりません。スラックが負の場合、入力データの安定性の条件が満たされず、データがビートします。たるみが多いほど良いですが、各レジスタの受信者で、プリセットとホールドのたるみには2つの共通の時間が1つあることを理解する必要があります。これは、一方のたるみの増加が常に他方の減少につながることを意味します。したがって、最良のオプションは、両方のスラックが正であり、互いにほぼ等しい場合です。たるみのバランスが観察されます。
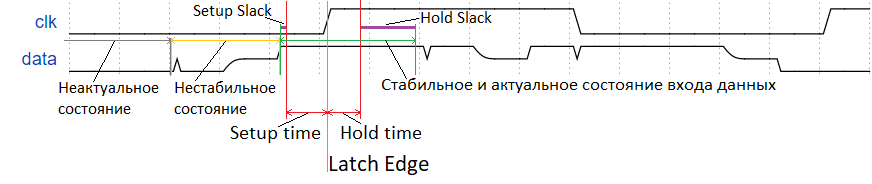
図:3.正のスラック、データ受信が成功するための条件は満たされていますが、スラック間にバランスがありません
スラック計算
次に、これらのスラックの計算方法に移りましょう。 SetupSlackから始めましょう。
図のデータ転送スキームを考えてみましょう。 4.

図。 4.データ転送方式
ここでは、トリガーフロント、キャプチャフロント、データ到着時間、データ待機時間、クロック到着時間などの概念を紹介します。起動エッジは、ソースレジスタの入力に来て、データ転送処理を開始したクロックの目の前です。ラッチ・エッジは、入力上のグラブのデータにそれを受信レジスタに到着し、力クロック前です。 データの到着の瞬間(データ到着時間)は、受信レジスタへのデータの実際の到着として定義されます。
データ所要時間は、それは時間と定義されて取るデータが転送先レジスタに予め設定された時間の前に目的地に到達するために。クロックの到着時間
(Clock Arrival Time)は、回路全体のクロック入力からレシーバーのクロック入力までのキャプチャーのエッジの通過時間として定義されます。さらに、キャプチャフロントとは、ローンチフロントの次のフロントを意味します。起動フロントはソースから受信者にデータを送信し、1クロック期間後、キャプチャフロントは受信者側でこのデータをキャッチします。
回路全体のクロック入力は、クロックが分岐する場所から、その上で動作するすべてのレジスタに分岐する単一のポイントとして理解されます。これは通常、グローバルクロックバッファの出力またはPLLの出力です。最も原始的なケースでは、これはクロックジェネレータが接続されているFPGAレッグです。
時間分析に含まれる用語には、ポイント値がない場合がありますが、設計トレースと結晶温度に応じて、特定の範囲の可能な値があります。したがって、最悪のスラックが分析されます。データ交換は、スラックの最悪の状況でも、それがポジティブなままである場合、成功したと見なされます。
データ到着の瞬間はトリガーエッジとどのように関連していますか?
データの到着は、トリガーエッジによって開始されたイベントのレジスターを持つチェーンを通過すると見なされます。
トリガーフロントはシステムのクロック入力に現れ、しばらくの間ソースレジスタの入力に到達し、しばらくの間このレジスタがトリガーされて新しいデータを出力に送信し、次にこのデータは組み合わせロジック回路を通過して受信レジスタに送られます。データパッセージの最悪で最も遅いバリアントが考慮されるため、用語には「max」プレフィックスが付いています。
この式では、トリガーエッジの用語は、イベントが発生する基準点の意味を持ち、ナノ秒単位で測定される値ではありません。
期間トリガーエッジが回路全体のクロック入力からソースのクロック入力に移動するのにかかる最大時間です。原則として、アナライザーは単に「正確に以上」から「正確に以下」までの時間範囲を取り、この式に「間違いなく以下」の上限を代入します。この値はユーザーに依存しません。コンパイラーは、レジスターをクリスタルのどこに配置するかを自ら決定し、クロックがクリスタルに移動するのにかかる時間を考慮に入れます。クロック信号がグローバルクロックバッファからレジスタに分岐する接続のネットワークは、クロック信号がほぼ同じ時間で任意のレジスタに到達するように設計されています。したがって、実際には、 そして 非常に小さいですが、それでも考慮されます。
期間-これはクロックから出力までの時間であり、レジスタはクロック入力のエッジを確認して出力のデータを変更するために費やします。アナライザーは、この値がチップ上のすべてのレジスターで等しいと見なします。この値はユーザーに依存しません。
最終学期イベント(データ)がレジスタ間の組み合わせロジックを通過する最大時間であり、ユーザーが定義します。この値は、ユーザーに大きく依存します。レジスタ間の組み合わせロジックの量を表します。同様に、組み合わせロジックの長いチェーンは、多くの場合、ユーザーによる不正確なコーディングの結果です。
シュレッドが受信者に到着した瞬間は、計算が簡単です。
これは、キャプチャエッジが受信レジスタのクロック入力に到達する最も早い瞬間です。
期間-これは、キャプチャフロントが受信者のクロック入力に到達する最小時間です。つまり、前の式と同様に、この時間は「間違いなく以上」です。この場合のダッシュは、ソースではなく、受信者のクロック入力について話していることを意味します。
データの待機時間は、レシーバーレジスタに事前設定された時間より前にデータがレシーバーに到達するのにかかる時間として定義されます。
期間 -これはすでにセットアップ時間として認識されており、クリスタルの各レジスタで同じと見なされます。今回はユーザーに依存しません。
期間あるクロック・セットアップ不確実性、予め設定された時間の不確実性は。CSUの時間分析における他の不確実性と同様に、物理的なプロセスではなく、分析にジッタの影響を反映する方法、または万が一の場合に備えて分析にガードタイムを導入する方法です。簡単に言えば、これは難しいプロセスを考慮に入れるための時間の確保です。
これらの用語が定義されたので、事前設定されたスラックを、目的地までの移動が許可されている時間と実際にかかる時間との最小の差として定義できます。
次に、これらの用語を拡張して、少し並べ替えてみましょう。
ここに新しい用語が登場しました。
周期については明らかです。これはクロック周波数の周期です。LaunchEdgeとLatchEdgeの間の時間。
期間-これはクロックスキューです-システムのクロック入力から異なる同期レジスタへの1つのクロックフロントの到着時間の広がりの最小値。最小クロックスプレッドは、受信者への最小クロック遅延とソースへの最大クロック遅延の差として定義されます。..。アナライザーは、チップ上のさまざまなレジスターの今回の推定に違いはありません。
これが、プリセットスラックの計算方法です。正のマージンは良いですが、負のマージンは悪いです。たるみは文字通りたるみに変換されます。したがって、スラックがある場合、レジスタ間転送は「vnatyag」に構成されておらず、条件付きの「スレッド」は自由にサグします。たるみは負です。これは、伝送スレッドが引っ張られて壊れたことを意味します。
図5は、スラック式をグラフィカルに表現する方法を示しています
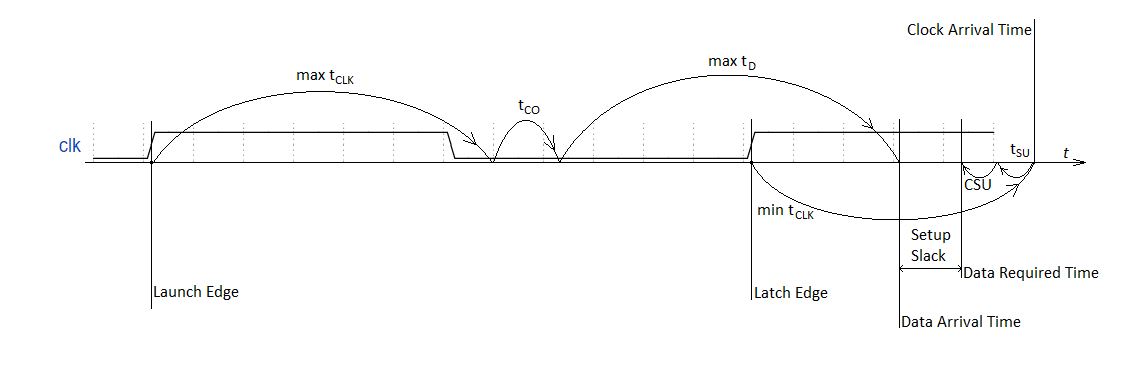
。 5.セットアップスラック式のグラフ
表示これは、クロック信号のバックグラウンドでの関係を示しています。これは、どのレジスタの入力でもなく、システムのクロック入力でのクロック信号です。
同様の方法で保持スラックを計算してみましょう。
また、用語の符号が変わった式で表すこともできます。
これらの用語は現在、反対側から検討されています。
ここで、データ通過の最速のバリアントが検討され、「最大」は「最小」でした。
クロックフロントの到着の瞬間も、可能な限り最新のものとして、別の観点から見られます。
Hold Slackの場合、LaunchEdgeとLatchEdgeのフロントは、クロック周期で区切られた2つの異なるフロントではなく、同じフロントになっていることに注意してください。この場合、受信レジスタは、クロックフロントの到着からの保持時間中に入力でデータを保持する時間を持っている必要があります。ただし、データは、ソースレジスタの別の場所にある同じフロントによって入力で変更されます。したがって、保持スラックの分析では、違い期間ではなく、ゼロに等しい。
この場合の所要時間は、保留時間をキャッチしないように、受信者のデータの入力時にデータが変更されてはならない時間として定義されます。
期間 -これはすでに私たちに知られていますホールドタイム、ホールドタイム。これは、チップ上のすべてのレジスタで同じと見なされ、ユーザーに依存しません。
期間あるクロック・ホールド不確実性、保持時間の不確実性は。それは一般的にCSUと同じ意味を持ち、原則としてそれと同等と見なされます。
プリセットスラックの場合のように、用語を展開して交換すると、保持スラック式は次の形式に変換できます。
この式をもう一度見てください
上に、スラックを計算する方法が提示されました。これは、行われているプロセスの人間の理解の特徴です。ここで「フロントが来ています...」、「データが来ています...」。興味があれば、補足として、時間制約のアナライザーがこれらの計算をどのように想像するかを説明します。
アナライザーは、マシンの理由に基づいて、用語を異なる方法でグループ化します。しかし、最終的には同じ結果になります。
これは、クロックセットアップ関係(SR)およびクロックホールド関係(HR)という用語を使用します。これは、それぞれ、プリセットとホールドのトリガーエッジ間の時間の比率として変換できます。
図6は、これらのフロントがどのように関連しているかを示しています

。6.スラック計算で使用されるフロント。
結果の式をより理解しやすい形式にすぐに変換できます。
最長のレジスタ間時間(最大r2rが必要)は、事前設定された間隔の開始前にデータが宛先に到達するために使用できる最大時間です。
最長のレジスタ間遅延(最長のr2r遅延)は、最長のパスに沿ってソースレジスタから宛先レジスタにデータを転送するのにかかる時間です。
これで、プリセットスラックを、宛先レジスタに到達するために利用可能な時間とそこに到達するための実際の時間との差として定義できます。
この式の項を拡張すると、プリセットスラックの見慣れた表現が得られます。
次に、保持のたるみについて説明します。最小のr2r要件は、宛先レジスタの入力でデータを保持するのにかかる時間です。
最短のレジスタ間遅延:
ここで、プリセットのスラックを、データがレシーバーの入力を離れる最速時間と、データをそこに保持するのにかかる時間との差として定義します。
用語を拡張すると、式はすでにおなじみの形式にもなります。
退屈な公式からどのような結論を引き出すことができますか?
スラックがどのように計算されるかを見てきました。この知識の使い方は?
スラック式をもう一度見てみましょう。
プロジェクトの一部の緩みがマイナスになった場合は、条件を変更することでそれらを変更できます。つまり、悪いたるみを修正する方法がわかります。
ユーザーに依存せず、クリスタルテクノロジーのみに依存する用語があります。それ..。干渉する方法はありません。
CSUとCHUの項がありますが、これらは通常、アナライザーがCUパラメーター(クロックの不確実性、クロック周波数の不安定性)と同じになります。一般的に、このパラメーターは小さく、数十ピコ秒です。これは、ユーザーが制限ファイルで指定します。そして、ユーザーは、クロックジェネレーターの仕様からそれを取得します。発振器から外部クロックを受け取り、それをシステムクロック入力で内部クロックに変換するクロックバッファまたは内部FPGA PLLは、CU値を発振器から受け取った値と同じに保つと考えられます。 CUが指定されていない場合、アナライザーはそれをデフォルト値に設定します。たとえば、Quartusはそれを20psに設定します。一般的な場合、この用語は、クロッキングの不安定性が少ない、安定性の高いオシレーターを使用する方がよいことを示しています。優れた発振器は20〜60psのオーダーです。
期間の項は、データ送信の誤った方向に対抗するための明白な方法は、クロック周波数を下げることであることを示しています。参照条件には通常、ある程度のシステムパフォーマンスが必要であり、それを下回ると実行できないため、これは合理的ですが、常に受け入れられるとは限りません。また、パフォーマンスはクロック周波数に直接依存します。プリセットとホールドスラックの違いもわかります。ホールドスラックは周波数に依存しません。
そして最後に、用語本質的に、書かれたコードの効率を特徴づけます。したがって、スラックの問題を解決する主な方法は、適切に書き直すことです。ビッグタイムあまりにも多くの組み合わせロジックを必要とする複雑すぎるハードウェア設計に現れます。プロジェクトにこのような複雑な構造がある場合、問題を解決する古典的な方法は、操作のシーケンスに別の1〜2個のレジスタを挿入することにより、1つの複雑なr2r転送をいくつかの単純な転送に分割することです。この場合、操作のサイクルの遅延は増加しますが、操作速度は増加します。たとえば、1クロックサイクルで複数のベクトルを追加することはお勧めできません。中間の合計で、いくつかのベクトルを順番に追加することをお勧めします。いくつかの複雑な構造をいくつかの単純な構造のパイプラインに分割することが不可能な場合があります。その場合、そのようなロジックは、根本的に異なる方法で書き直す必要があります。
結論
この記事のポイントは、たるみの概念の存在と、このたるみが物理的に何に依存するかについて学ぶことです。これを知っていると、時間制約のアナライザーのレポートを独自に調査し、結論を導き出し、プロジェクトのパフォーマンスをデバッグすることができます。これらは、実際の計算を行う必要がほとんどない式です。あなたはそれらを暗記する必要さえありません。レジスタ間転送で何が起こっているのかを理解し、プロジェクトの速度を決定する要因を理解することだけが重要です。