
ビッグデータの現代の世界では、ApacheSparkはバッチデータ処理タスクを開発するための事実上の標準です。さらに、マイクロバッチの概念で動作するストリーミングアプリケーションを作成し、データを少しずつ処理および送信するためにも使用されます(Spark StructuredStreaming)。そして伝統的に、それはYARN(または場合によってはApache Mesos)をリソースマネージャーとして使用して、Hadoopスタック全体の一部でした。 2020年までに、適切なHadoopディストリビューションがないため、ほとんどの企業での従来の使用は大きな問題になっています。HDPとCDHの開発は停止し、CDHは開発が不十分でコストが高く、残りのHadoopプロバイダーは存在しなくなったか漠然とした未来を持っています。したがって、コミュニティや大企業の間で関心が高まっているのは、Kubernetesを使用したApache Sparkの立ち上げです。これはプライベートクラウドとパブリッククラウドでのコンテナオーケストレーションとリソース管理の標準となり、YARNでのSparkタスクの不便なリソーススケジューリングの問題を解決し、多くの商用プラットフォームを着実に開発しています。あらゆる規模とストライプの企業向けのオープンソースディストリビューション。さらに、人気の波に乗って、大多数はすでにいくつかのインスタレーションを取得し、それを使用するための専門知識を増やすことができました。これにより、移動が簡単になります。YARNでのSparkタスクの厄介なスケジューリングを解決し、あらゆる規模とストライプの企業向けに、多くの商用およびオープンソースのディストリビューションを備えた着実に進化するプラットフォームを提供します。さらに、人気の波に乗って、大多数はすでにいくつかのインストールを取得し、それを使用するための専門知識を増やすことができました。これにより、移動が簡単になります。YARNでのSparkタスクの厄介なスケジューリングを解決し、あらゆる規模とストライプの企業向けに、多くの商用およびオープンソースのディストリビューションを備えた着実に進化するプラットフォームを提供します。さらに、人気の波に乗って、大多数はすでにいくつかのインストールを取得し、それを使用するための専門知識を増やすことができました。これにより、移動が簡単になります。
バージョン2.3.0以降、Apache SparkはKubernetesクラスターでタスクを実行するための公式サポートを取得しました。本日は、このアプローチの現在の成熟度、その使用に関するさまざまなオプション、および実装中に発生する落とし穴について説明します。
まず、Apache Sparkに基づいてタスクとアプリケーションを開発するプロセスを検討し、Kubernetesクラスターでタスクを実行する必要がある典型的なケースを強調します。この投稿を準備するとき、OpenShiftは配布キットとして使用され、そのコマンドラインユーティリティ(oc)に関連するコマンドが提供されます。他のKubernetesディストリビューションの場合、標準のKubernetesコマンドラインユーティリティ(kubectl)またはそれらの類似物(たとえば、oc admポリシー)の対応するコマンドを使用できます。
最初の使用例はspark-submitです
タスクとアプリケーションを開発する過程で、開発者はデータ変換をデバッグするためにタスクを実行する必要があります。理論的には、スタブはこれらの目的に使用できますが、有限システムの実際の(テストではありますが)インスタンスを使用した開発は、このクラスの問題でより速く、より良くなることが示されています。エンドシステムの実際のインスタンスでデバッグする場合、次の2つのシナリオが考えられます。
- 開発者は、スタンドアロンモードでローカルにSparkタスクを実行します。
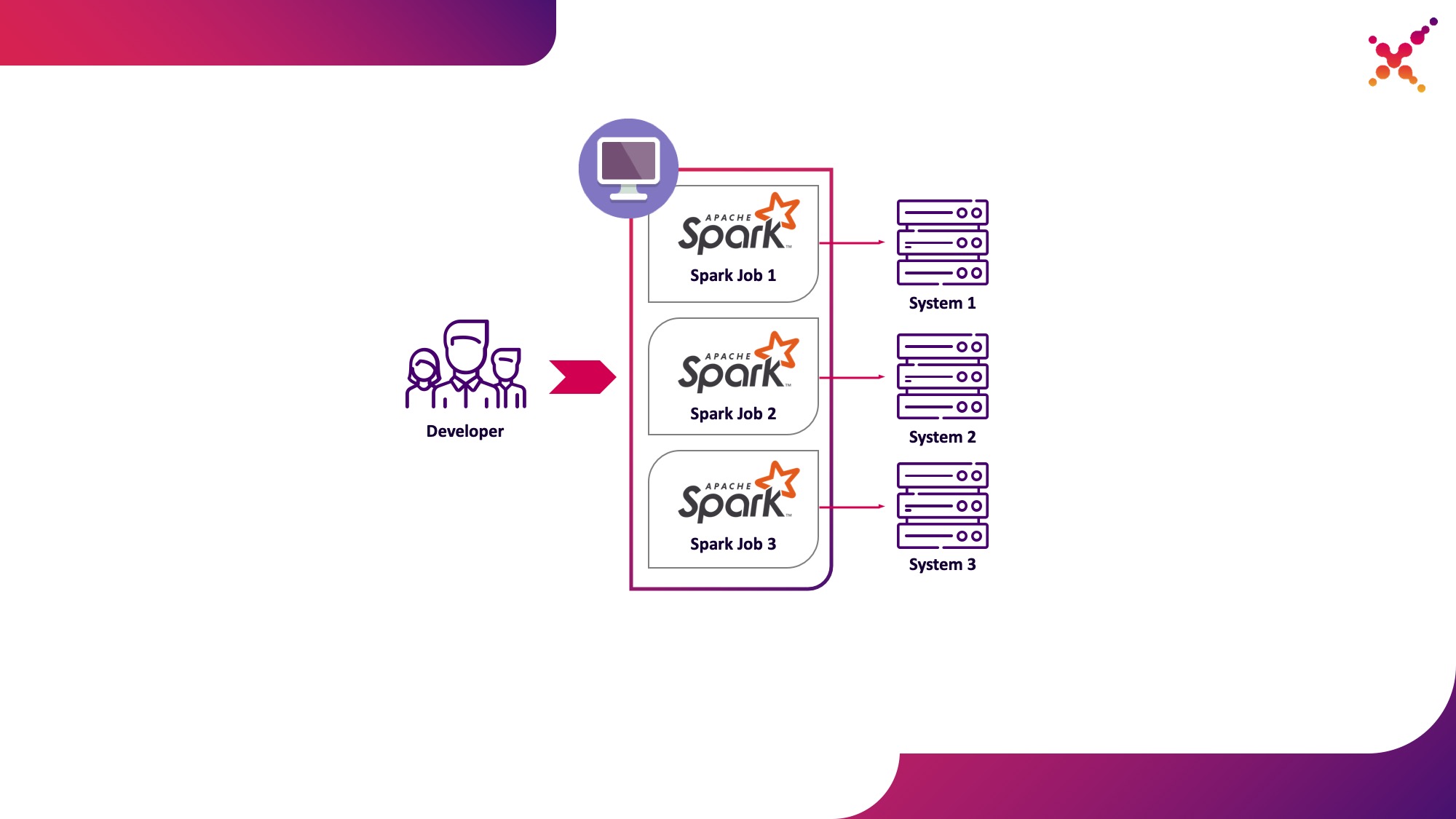
- 開発者は、テストループ内のKubernetesクラスターでSparkタスクを実行します。

最初のオプションには存在する権利がありますが、いくつかの欠点があります。
- 開発者ごとに、職場から必要なエンドシステムのすべてのコピーへのアクセスを提供する必要があります。
- 作業マシンには、開発されたタスクを実行するための十分なリソースが必要です。
2番目のオプションには、これらの欠点がありません。Kubernetesクラスターを使用すると、タスクの実行に必要なリソースのプールを割り当て、エンドシステムのインスタンスへの必要なアクセスを提供し、開発チームのすべてのメンバーにKubernetesロールモデルを使用して柔軟にアクセスを提供できるためです。これを最初の使用例として強調しましょう。テストループでKubernetesクラスター上のローカル開発マシンからSparkタスクを実行します。
ローカルで実行するようにSparkを構成するプロセスを詳しく見てみましょう。Sparkの使用を開始するには、Sparkをインストールする必要があります。
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Kubernetesでの作業に必要なパッケージを収集します。
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
完全なビルドには多くの時間がかかります。DockerイメージをビルドしてKubernetesクラスターで実行するには、実際には「assembly /」ディレクトリからのjarファイルのみが必要なので、次のサブプロジェクトのみをビルドできます。
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
KubernetesでSparkタスクを実行するには、ベースイメージとして機能するDockerイメージを作成する必要があります。ここでは2つのアプローチが可能です。
- 生成されたDockerイメージには、Sparkタスクの実行可能コードが含まれています。
- 作成されたイメージには、Sparkと必要な依存関係のみが含まれ、実行可能なコードはリモートでホストされます(たとえば、HDFSで)。
まず、Sparkタスクのテスト例を含むDockerイメージを作成しましょう。Dockerイメージを構築するために、Sparkには「docker-image-tool」と呼ばれるユーティリティがあります。それについての助けを研究しましょう:
./bin/docker-image-tool.sh --help
Dockerイメージを作成し、それらをリモートレジストリにアップロードするために使用できますが、デフォルトではいくつかの欠点があります。
- Spark、PySpark、Rの場合は必ず3つのDockerイメージを一度に作成します。
- 画像の名前を指定することはできません。
したがって、以下に示すこのユーティリティの修正バージョンを使用します。
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
これを使用して、Sparkを使用してPi番号を計算するためのテストタスクを含むベースSparkイメージを作成します(ここで、{docker-registry-url}はDockerイメージレジストリのURL、{repo}はレジストリ内のリポジトリの名前であり、OpenShiftのプロジェクトと一致します) 、{image-name}は画像の名前です(たとえば、Red Hat OpenShiftの統合画像レジストリのように3レベルの画像分離が使用されている場合)、{tag}はこのバージョンの画像のタグです):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
コンソールユーティリティを使用してOKDクラスターにログインします(ここでは、{OKD-API-URL}はOKDクラスターAPI URLです)。
oc login {OKD-API-URL}
Dockerレジストリでの承認のために現在のユーザーのトークンを取得しましょう。
oc whoami -t
OKDクラスターの内部Dockerレジストリにログインします(前のコマンドで取得したトークンをパスワードとして使用します)。
docker login {docker-registry-url}
ビルドされたDockerイメージをDockerレジストリOKDにアップロードします。
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
アセンブルされた画像がOKDで利用可能であることを確認しましょう。これを行うには、対応するプロジェクトの画像のリストを含むURLをブラウザーで開きます(ここで、{project}はOpenShiftクラスター内のプロジェクトの名前、{OKD-WEBUI-URL}はOpenShift WebコンソールのURLです)-https:// {OKD-WEBUI-URL} / console /プロジェクト/ {プロジェクト} /ブラウズ/画像/ {画像名}。
タスクを実行するには、ポッドをルートとして実行する権限を持つサービスアカウントを作成する必要があります(この点については後で説明します)。
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
作成したサービスアカウントとDockerイメージを指定して、spark-submitコマンドを実行してSparkタスクをOKDクラスターに公開します。
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
ここで:
-nameは、Kubernetesポッド名の形成に参加するタスクの名前です。
--class-タスクの開始時に呼び出される実行可能ファイルのクラス。
--conf-Spark構成パラメーター。
spark.executor.instances実行するSparkエグゼキュータの数。
spark.kubernetes.authenticate.driver.serviceAccountNameポッドの起動時に使用されるKubernetesサービスアカウントの名前(Kubernetes APIと対話するときのセキュリティコンテキストと機能を定義するため)。
spark.kubernetes.namespace-ドライバーポッドとエグゼキューターポッドが実行されるKubernetes名前空間。
spark.submit.deployMode-Spark起動方法(「クラスター」は標準のspark-submitに使用され、「client」はSparkオペレーター以降のバージョンのSparkに使用されます)。
spark.kubernetes.container.imageポッドの実行に使用されるDockerイメージ。
spark.master-Kubernetes APIのURL(外部は、呼び出しがローカルマシンから発生するように指定されます)。
local://はDockerイメージ内のSpark実行可能ファイルへのパスです。
対応するOKDプロジェクトに移動し、作成されたポッドを調べます-https:// {OKD-WEBUI-URL} /コンソール/プロジェクト/ {プロジェクト} /ブラウズ/ポッド。
開発プロセスを簡素化するために、別のオプションを使用できます。このオプションでは、起動するすべてのタスクで使用される共通のベースSparkイメージが作成され、実行可能ファイルのスナップショットが外部ストレージ(Hadoopなど)に公開され、spark-submitをリンクとして呼び出すときに指定されます。この場合、たとえばWebHDFSを使用してイメージを公開するなど、Dockerイメージを再構築せずに、さまざまなバージョンのSparkタスクを実行できます。ファイルを作成するリクエストを送信します(ここで、{host}はWebHDFSサービスのホスト、{port}はWebHDFSサービスのポート、{path-to-file-on-hdfs}はHDFS上のファイルへの目的のパスです):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
これはフォームの応答を受け取ります(ここで{location}はファイルをダウンロードするために使用する必要があるURLです):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Spark実行可能ファイルをHDFSにロードします(ここで、{path-to-local-file}は現在のホスト上のSpark実行可能ファイルへのパスです):
curl -i -X PUT -T {path-to-local-file} "{location}"
その後、HDFSにアップロードされたSparkファイルを使用してspark-submitを作成できます(ここで、{class-name}は、タスクを完了するために起動する必要があるクラスの名前です)。
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
同時に、HDFSにアクセスしてタスクを機能させるには、Dockerfileとentrypoint.shスクリプトを変更する必要がある場合があることに注意してください。Dockerfileにディレクティブを追加して、依存ライブラリを/ opt / spark / jarsディレクトリにコピーし、HDFS構成ファイルをエントリポイントのSPARK_CLASSPATHに含めます。 sh。
2番目の使用例-ApacheLivy
さらに、タスクが開発され、得られた結果をテストする必要がある場合、CI / CDプロセス内でタスクを起動し、その実行ステータスを追跡するという疑問が生じます。もちろん、ローカルのspark-submit呼び出しを使用して実行できますが、CIサーバーエージェント/ランナーにSparkをインストールして構成し、Kubernetes APIへのアクセスを設定する必要があるため、CI / CDインフラストラクチャが複雑になります。この場合、ターゲット実装は、Kubernetesクラスター内でホストされるSparkタスクを実行するためのRESTAPIとしてApacheLivyを使用することを選択しました。これは、通常のcURL要求を使用してKubernetesクラスターでSparkタスクを起動するために使用できます。これは任意のCIソリューションに基づいて簡単に実装でき、Kubernetesクラスター内に配置すると、KubernetesAPIと対話する際の認証の問題が解決されます。
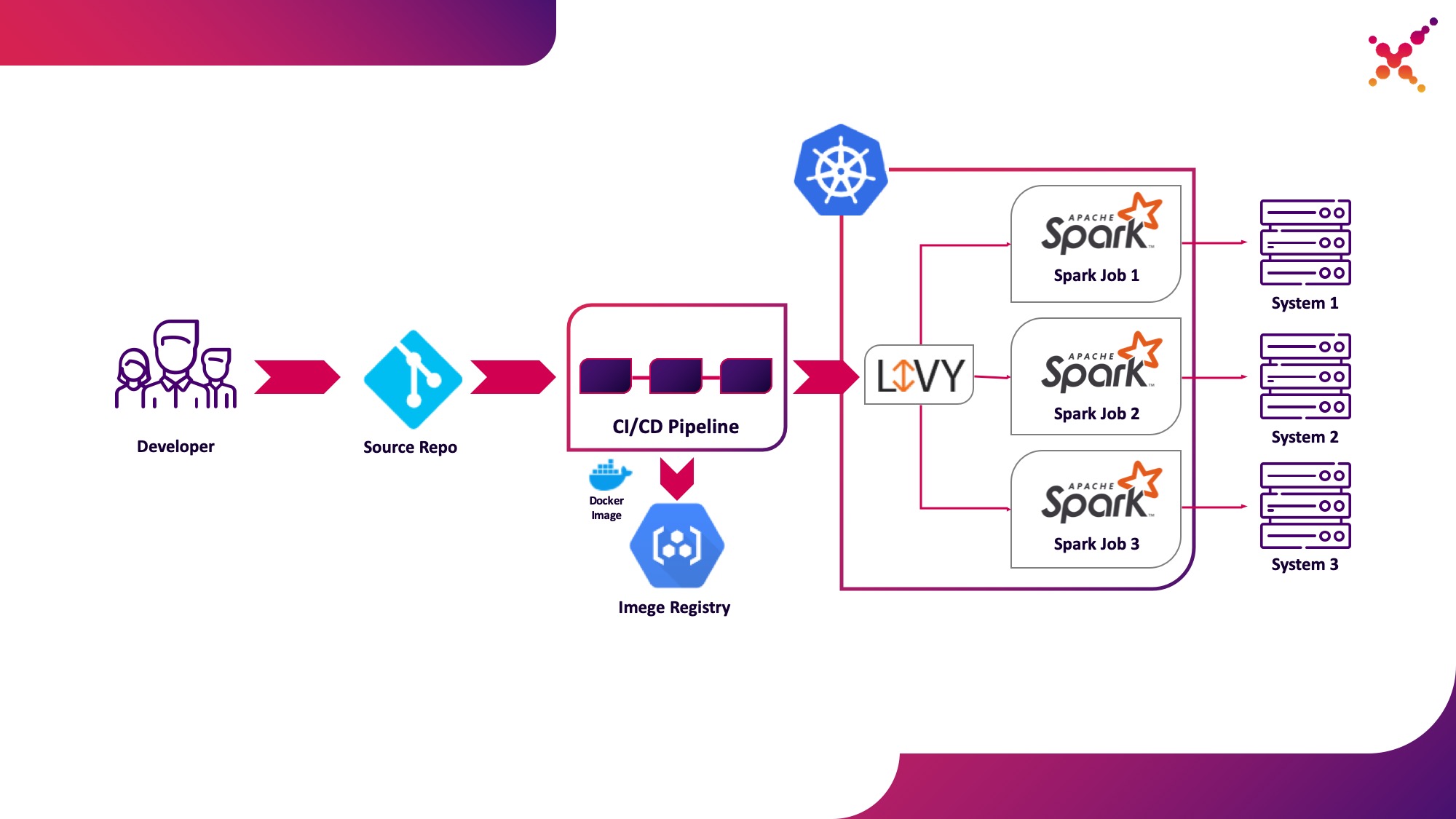
2番目のユースケースとして強調しましょう-テストループ内のKubernetesクラスターでCI / CDプロセスの一部としてSparkタスクを実行します。
Apache Livyについて少し説明します。これは、WebインターフェイスとRESTful APIを提供するHTTPサーバーとして機能し、必要なパラメーターを渡すことでリモートでspark-submitを実行できます。従来はHDPディストリビューションの一部として出荷されていましたが、適切なマニフェストと一連のDockerイメージを使用して、OKDまたはその他のKubernetesインストールにデプロイすることもできます(例:github.com/ttauveron/k8s-big-data-experiments/tree/master)。 /livy-spark-2.3。この場合、次のDockerfileからSparkバージョン2.4.5を含む、同様のDockerイメージが作成されました。
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
生成されたイメージをビルドして、内部OKDリポジトリなどの既存のDockerリポジトリにアップロードできます。これを展開するには、次のマニフェストを使用します({registry-url}はDockerイメージレジストリのURL、{image-name}はDockerイメージの名前、{tag}はDockerイメージのタグ、{livy-url}はサーバーにアクセスできる目的のURLです。 Livy; Red Hat OpenShiftがKubernetesディストリビューションとして使用されている場合は「Route」マニフェストが使用され、それ以外の場合はタイプNodePortの対応するIngressまたはServiceマニフェストが使用されます):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
アプリケーションを適用してポッドを正常に起動すると、次のリンクからLivyグラフィカルインターフェイスを利用できるようになります:http:// {livy-url} / ui。Livyを使用すると、PostmanなどからのRESTリクエストを使用してSparkタスクを公開できます。リクエストを含むコレクションの例を以下に示します(「args」配列では、実行中のタスクが機能するために必要な変数を含む構成引数を渡すことができます)。
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
コレクションから最初のリクエストを実行し、OKDインターフェイスに移動して、タスクが正常に起動されたことを確認しましょう-https:// {OKD-WEBUI-URL} / console / project / {project} / browser / pods。この場合、セッションはLivyインターフェイス(http:// {livy-url} / ui)に表示され、その中でLivy APIまたはグラフィカルインターフェイスを使用して、タスクの進行状況を追跡し、セッションログを調べることができます。
それでは、Livyがどのように機能するかを示しましょう。これを行うには、ポッド内のLivyコンテナのログをLivyサーバーで調べてみましょう-https:// {OKD-WEBUI-URL} / console / project / {project} / browser / pods / {livy-pod-name}?Tab = logs。それらから、「livy」という名前のコンテナでLivy REST APIを呼び出すと、上記で使用したものと同様のspark-submitが実行されることがわかります(ここで、{livy-pod-name}はLivyサーバーで作成されたポッドの名前です)。このコレクションは、Livyサーバーを使用してSpark実行可能ファイルのリモートホスティングでタスクを実行できるようにする2番目の要求も提供します。
3番目の使用例-SparkOperator
タスクがテストされたので、定期的に実行することに疑問が生じます。 Kubernetesクラスターでタスクを定期的に実行するネイティブの方法はCronJobエンティティであり、それを使用できますが、現時点では、オペレーターを使用してKubernetesのアプリケーションを制御することが非常に一般的であり、Sparkにはかなり成熟したオペレーターがあります。これはエンタープライズレベルのソリューションでも使用されます。 (例:Lightbend FastData Platform)。これを使用することをお勧めします-現在の安定バージョンのSpark(2.4.5)では、KubernetesでSparkタスクの起動を構成するためのオプションが非常に限られています。次のメジャーバージョン(3.0.0)では、Kubernetesの完全なサポートが発表されていますが、リリース日は不明です。 Spark Operatorは、重要な構成パラメーターを追加することにより、この欠点を補います(たとえば、SparkポッドでHadoopへのアクセスを構成するConfigMapをマウントし、スケジュールに従ってタスクを定期的に実行する機能。
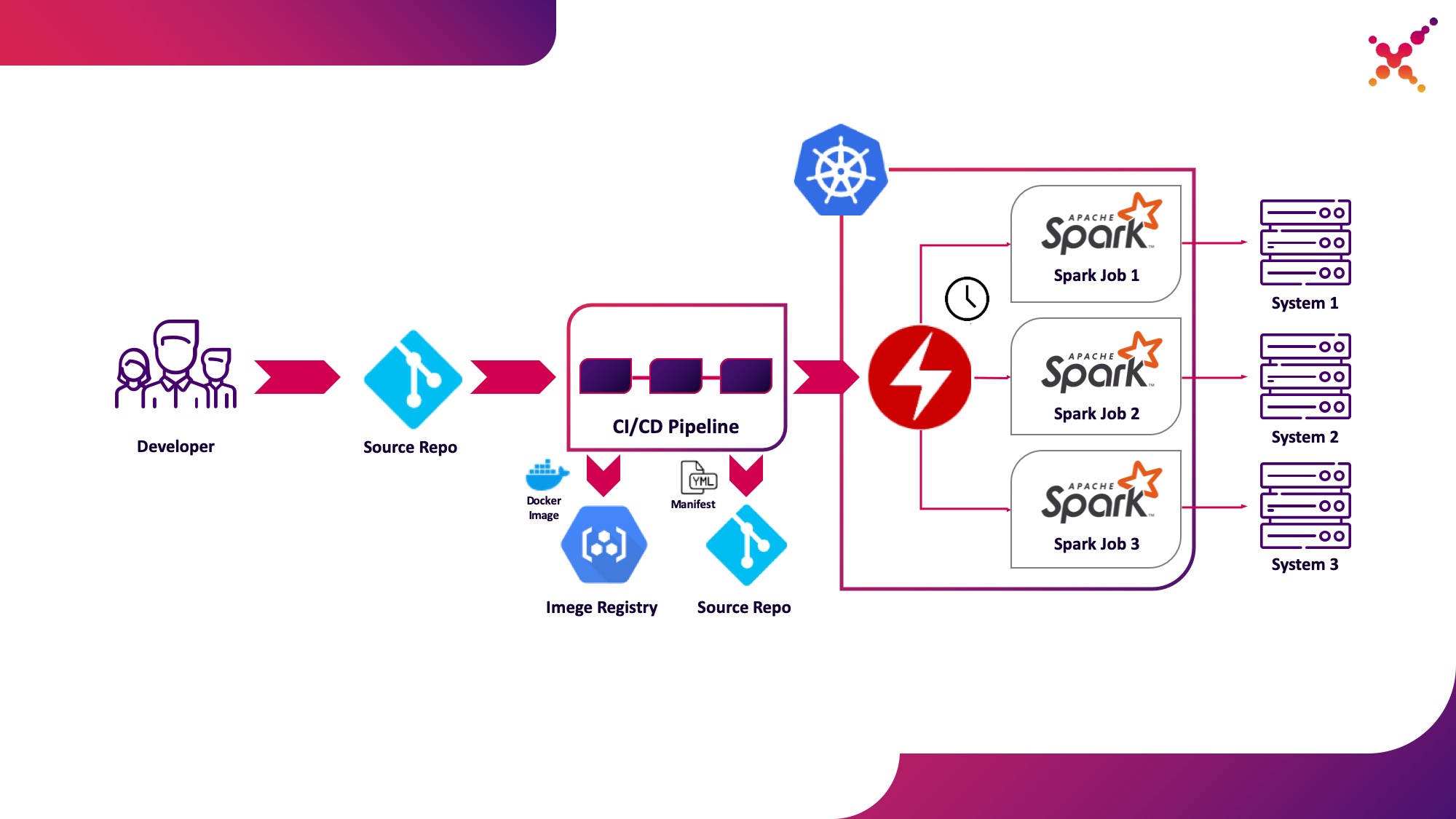
これを3番目のユースケースとして強調しましょう。本番ループのKubernetesクラスターでSparkタスクを定期的に実行します。
Spark Operatorはオープンソースであり、Google Cloud Platform(github.com/GoogleCloudPlatform/spark-on-k8s-operator)で開発されています。そのインストールは3つの方法で行うことができます:
- Lightbend FastData Platform / Cloudflowインストールの一部として。
- ヘルム付き:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
演算子が正しく設定されている場合、Spark演算子を持つアクティブなポッド(たとえば、CloudflowをインストールするためのCloudflowスペースのcloudflow-fdp-sparkoperator)が対応するプロジェクトに表示され、「sparkapplications」という名前の対応するKubernetesリソースタイプが表示されます。次のコマンドを使用して、使用可能なSparkアプリケーションを調べることができます。
oc get sparkapplications -n {project}
Spark Operatorでタスクを実行するには、次の3つのことを行う必要があります。
- 必要なすべてのライブラリ、構成ファイル、実行可能ファイルを含むDockerイメージを作成します。ターゲット画像では、これはCI / CDステージで作成され、テストクラスターでテストされた画像です。
- Kubernetesクラスターからアクセス可能なレジストリにDockerイメージを公開します。
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- 辞書「spec.sparkVersion」は、使用されているSparkのバージョンを示している必要があります。
- 辞書「spec.driver.serviceAccount」には、アプリケーションの起動に使用される、対応するKubernetes名前空間内のサービスアカウントが存在する必要があります。
- 辞書「spec.executor」は、アプリケーションに割り当てられたリソースの量を示す必要があります。
- 「spec.volumeMounts」ディクショナリは、ローカルSparkタスクファイルが作成されるローカルディレクトリを指定する必要があります。
マニフェストを生成する例(ここで{spark-service-account}は、Sparkタスクを実行するためのKubernetesクラスター内のサービスアカウントです):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
このマニフェストは、マニフェストを公開する前に、SparkアプリケーションがKubernetes APIと対話するために必要なアクセス権を提供する必要なロールバインディングを作成する必要があるサービスアカウントを指定します(必要な場合)。この場合、アプリケーションにはポッドを作成する権限が必要です。必要なロールバインディングを作成しましょう:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
このマニフェストの仕様でhadoopConfigMapパラメーターを指定できることにも注意してください。これにより、対応するファイルをDockerイメージに最初に配置しなくても、Hadoop構成でConfigMapを指定できます。また、タスクの定期的な起動にも適しています。「schedule」パラメーターを使用して、このタスクの起動のスケジュールを指定できます。
その後、マニフェストをspark-pi.yamlファイルに保存し、Kubernetesクラスターに適用します。
oc apply -f spark-pi.yaml
これにより、「sparkapplications」タイプのオブジェクトが作成されます。
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
これにより、アプリケーションを含むポッドが作成され、そのステータスが作成された「sparkapplications」に表示されます。次のコマンドで表示できます。
oc get sparkapplications spark-pi -o yaml -n {project}
タスクが完了すると、PODは「完了」ステータスに移行します。このステータスも「sparkapplications」に更新されます。アプリケーションログは、ブラウザで表示するか、次のコマンドを使用して表示できます(ここで、{sparkapplications-pod-name}は実行中のタスクのポッドの名前です)。
oc logs {sparkapplications-pod-name} -n {project}
Sparkタスクは、専用のsparkctlユーティリティを使用して管理することもできます。これをインストールするには、リポジトリをそのソースコードで複製し、Goをインストールして、次のユーティリティをビルドします。
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
実行中のSparkタスクのリストを調べてみましょう。
sparkctl list -n {project}
Sparkタスクの説明を作成しましょう。
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
sparkctlを使用して、説明されているタスクを実行してみましょう。
sparkctl create spark-app.yaml -n {project}
実行中のSparkタスクのリストを調べてみましょう。
sparkctl list -n {project}
開始されたSparkタスクのイベントのリストを調べてみましょう。
sparkctl event spark-pi -n {project} -f
実行中のSparkタスクのステータスを調べてみましょう。
sparkctl status spark-pi -n {project}
結論として、Kubernetesで現在の安定バージョンのSpark(2.4.5)を操作することで発見された欠点について検討したいと思います。
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- Kubernetesを使用したSparkタスクの実行は、まだ正式に実験モードであり、将来、使用されるアーティファクト(構成ファイル、Dockerベースイメージ、および起動スクリプト)に大幅な変更が加えられる可能性があります。実際、資料を準備するときに、バージョン2.3.0と2.4.5がテストされたとき、動作は大幅に異なっていました。
更新を待ちます-Sparkの新しいバージョン(3.0.0)が最近リリースされました。これにより、KubernetesでのSparkの動作に具体的な変更が加えられましたが、このリソースマネージャーのサポートの実験的なステータスは保持されました。おそらく、次のアップデートにより、システムのセキュリティを恐れることなく、また機能コンポーネントを個別に改良する必要なしに、YARNを放棄してKubernetesでSparkタスクを実行することを完全に推奨できるようになります。
フィン。