-要するに、どのような計画がありますか?まず、Pythonを学ぶ理由について説明します。次に、CPythonインタープリターがどのように機能するか、メモリをどのように管理するか、Pythonの型システムがどのように機能するか、辞書、ジェネレーター、および例外を見てみましょう。1時間くらいかかると思います。
なぜPythonなのか?
* Insights.stackoverflow.com/survey/2019**
非常に主観的な
***研究の
解釈****研究の解釈
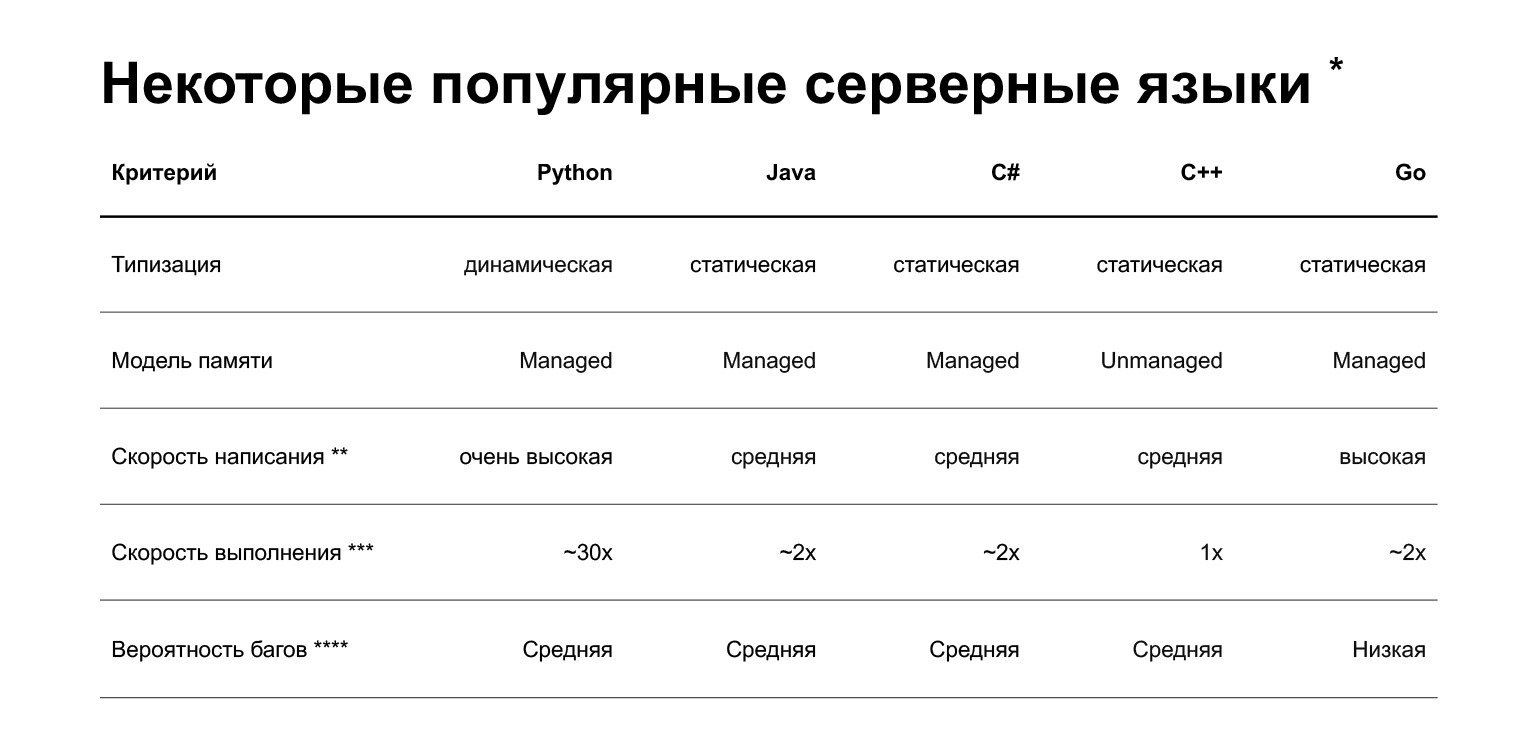
始めましょう。なぜPythonなのか?スライドは、バックエンド開発で現在使用されているいくつかの言語の比較を示しています。しかし、要するに、Pythonの利点は何ですか?あなたはすぐにそれにコードを書くことができます。もちろん、これは非常に主観的なものです。クールなC ++またはGoを作成する人は、これについて議論することができます。しかし、平均して、Pythonでの書き込みは高速です。
欠点は何ですか?最初の、そしておそらく主な欠点は、Pythonが遅いことです。他の言語よりも30倍遅くなる可能性があります。これは、このトピックに関する調査です。しかし、その速度はタスクによって異なります。タスクには2つのクラスがあります。
-CPUバウンド、CPUバウンドタスク、CPUバウンド。
--I / Oバインド、タスクは入出力によって制限されます:ネットワーク経由またはデータベース内。
CPUにバインドされた問題を解決している場合は、はい、Pythonは遅くなります。 I / Oがバインドされていて、これが大きなクラスのタスクである場合、実行速度を理解するには、ベンチマークを実行する必要があります。そして、おそらくPythonを他の言語と比較しても、パフォーマンスの違いに気付くことさえありません。
さらに、Pythonは動的に型付けされます。インタープリターは、コンパイル時に型をチェックしません。バージョン3.5では、タイプヒントが表示され、タイプを静的に指定できますが、それほど厳密ではありません。つまり、コンパイル段階ではなく、すでに本番環境でエラーが発生する可能性があります。バックエンド用の他の一般的な言語(Java、C#、C ++、Go)には静的型付けがあります:コードで間違ったオブジェクトを渡すと、コンパイラーがそのことを通知します。
もっと現実的に言えば、Pythonはタクシー製品開発でどのように使用されていますか?私たちはマイクロサービスアーキテクチャに向かっています。私たちはすでに160のマイクロサービス、つまり食料品を持っています-35、Pythonで15、プラスで20。つまり、現在、Pythonのみ、またはプラスで記述しています。
どのように言語を選択しますか?1つ目は負荷要件です。つまり、Pythonがそれを処理できるかどうかを確認します。彼が引っ張った場合、私たちはチーム開発者の能力を見ます。
それでは通訳についてお話したいと思います。CPythonはどのように機能しますか?
通訳装置
疑問が生じるかもしれません:なぜ通訳がどのように機能するかを知る必要があるのですか。質問は有効です。内部に何があるかを知らなくても、簡単にサービスを作成できます。答えは次のとおりです
。1。高負荷の最適化。Pythonサービスがあると想像してください。それは動作し、負荷は低いです。しかし、ある日、仕事があなたにやって来ます-重い負荷に備えてペンを書くことです。これから逃れることはできません。C++でサービス全体を書き直すことはできません。したがって、高負荷用にサービスを最適化する必要があります。インタプリタがどのように機能するかを理解すると、これに役立ちます。
2.複雑なケースのデバッグ。サービスは実行されているが、メモリが「リーク」し始めたとします。 Yandex.Taxiでは、つい最近そのようなケースが発生しました。このサービスは1時間ごとに8GBのメモリを消費し、クラッシュしました。私たちはそれを理解する必要があります。それは言語、Pythonについてです。 Pythonでメモリ管理がどのように機能するかについての知識が必要です。
3.これは、複雑なライブラリや複雑なコードを作成する場合に役立ちます。
4.そして一般的に-ユーザーとしてだけでなく、より深いレベルで作業しているツールを知ることは良い形であると考えられています。これはYandexで高く評価されています。
5.彼らはインタビューでそれについて質問しますが、それは重要ではありませんが、あなたの一般的なITの見通しです。

翻訳者の種類を簡単に思い出してみましょう。コンパイラーとインタープリターがあります。ご存知かもしれませんが、コンパイラは、ソースコードを直接マシンコードに変換するものです。むしろ、インタプリタは最初にバイトコードに変換し、次にそれを実行します。 Pythonは解釈された言語です。
Bytecodeは、オリジナルから取得される一種の中間コードです。プラットフォームに関連付けられておらず、仮想マシン上で実行されます。なぜ仮想なのか?これは本物の車ではありませんが、ある種の抽象化です。

どのような種類の仮想マシンがありますか?登録してスタックします。しかし、ここでは、これではなく、Pythonがスタックマシンであるという事実を覚えておく必要があります。次に、スタックがどのように機能するかを確認します。
そしてもう1つの注意点:ここではCPythonについてのみ説明します。 CPythonは、ご想像のとおり、Cで記述されたリファレンスPython実装です。同義語として使用されます。Pythonについて話すときは、通常、CPythonについて話します。
しかし、他の通訳もいます。 JITコンパイルを使用して約5倍高速化するPyPyがあります。めったに使用されません。私は正直に会ったことがありません。 JPythonがあり、Java仮想マシンとDotnetマシンのバイトコードを変換するIronPythonがあります。これは今日の講義の範囲外です-正直なところ、私はそれに遭遇していません。それでは、CPythonを見てみましょう。

しばらく様子を見てみましょう。ソース、行があり、それを実行したい。通訳は何をしますか?文字列は単なる文字の集まりです。それで何か意味のあることをするために、あなたは最初にコードをトークンに翻訳します。トークンは、文字のグループ化されたセット、識別子、数字、またはある種の反復です。実際、インタプリタはコードをトークンに変換します。

さらに、抽象構文ツリーASTは、これらのトークンから構築されます。また、まだ気にしないでください。これらは、操作を行うノード内の一部のツリーです。この場合、バイナリ操作であるBinOpがあるとしましょう。操作-指数、オペランド:上げる数、上げる力。
さらに、これらのツリーを使用して、すでにいくつかのコードを作成できます。私は多くのステップを逃します、最適化ステップ、他のステップがあります。次に、これらの構文ツリーがバイトコードに変換されます。
ここでもっと詳しく見てみましょう。 Bytecodeは、その名前が示すように、バイトで構成されるコードです。また、Pythonでは、3.6以降、バイトコードは2バイトです。

最初のバイトは、opcodeと呼ばれる演算子自体です。 2番目のバイトはoparg引数です。上から見たようです。つまり、一連のバイトです。しかし、PythonにはDisassemblerのdisというモジュールがあり、これを使用すると、より人間が読みやすい表現を見ることができます。
それはどのように見えますか?ソースの行番号があります-左端の番号です。 2番目の列はアドレスです。私が言ったように、Python 3.6のバイトコードは2バイトを取るので、すべてのアドレスは偶数であり
、0、2、4が表示されます... Load.name、Load.constはすでにコードオプション自体です。 Pythonが実行されます。 0、0、1、1はoparg、つまりこれらの操作の引数です。次に、それらがどのように実行されるかを見てみましょう。
(...)バイトコードがPythonでどのように実行されるか、このためにどのような構造があるかを見てみましょう。

Cがわからなくても大丈夫です。脚注は一般的な理解のためのものです。
Pythonには、バイトコードの実行に役立つ2つの構造があります。 1つ目はCodeObjectで、その概要を確認できます。実際、構造はより大きくなっています。これはコンテキストのないコードです。これは、この構造に実際に今見たバイトコードが含まれていることを意味します。関数に定数への参照、定数の名前などが含まれている場合は、この関数で使用される変数の名前が含まれます。

次の構造はFrameObjectです。これはすでに実行コンテキストであり、変数の値がすでに含まれている構造です。グローバル変数への参照。実行スタック(これについては後で説明します)、およびその他の多くの情報。命令の実行回数を考えてみましょう。
例として、関数を複数回呼び出したい場合は、同じCodeObjectがあり、呼び出しごとに新しいFrameObjectが作成されます。独自の引数、独自のスタックがあります。したがって、それらは相互接続されています。

メインのインタープリターループとは何ですか?バイトコードはどのように実行されますか?あなたは私たちがopargでこれらのopcodeのリストを持っているのを見ました。これはどのように行われますか? Pythonには、他のインタープリターと同様に、このバイトコードを実行するループがあります。つまり、フレームがフレームに入り、Pythonはバイトコードを順番に調べ、それがどのような種類のopargであるかを調べ、巨大なスイッチを使用してハンドラーに移動します。たとえば、ここでは1つのopcodeのみが示されています。たとえば、ここにバイナリ減算、バイナリ減算があります。たとえば、この場所で「AB」が実行されるとします。
バイナリ減算がどのように機能するかを説明しましょう。非常に単純で、これは最も単純なコードの1つです。 TOP関数は、スタックから最上位の値を取得し、最上位の値から取得し、スタックからポップするだけでなく、PyNumber_Subtract関数が呼び出されます。結果:スラッシュSET_TOP関数がスタックにプッシュバックされます。スタックについて明確でない場合は、例を次に示します。

GILについて簡単に説明します。 GILは、Pythonのプロセスレベルのミューテックスであり、このミューテックスをメインのインタープリターループに取り込みます。その後、バイトコードの実行が開始されます。これは、インタープリターの内部構造を保護するために、一度に1つのスレッドのみがバイトコードを実行するように行われます。
もう少し進んで、Pythonのすべてのオブジェクトにそれらへの参照がいくつかあるとしましょう。また、2つのスレッドがこのリンク数を変更すると、インタープリターが機能しなくなります。したがって、GILがあります。
これについては、非同期プログラミングに関する講義で説明します。これはあなたにとってどのように重要ですか?マルチスレッドは使用されません。複数のスレッドを作成した場合でも、通常はそのうちの1つだけが実行され、バイトコードはスレッドの1つで実行されるためです。したがって、マルチプロセッシング、sish拡張、または他の何かを使用してください。

簡単な例。このフレームはPythonから安全に探索できます。アンダースコア関数get_frameを持つsysモジュールがあります。フレームを取得して、そこにある変数を確認できます。指示があります。これは教えるためのもので、実際には使用しませんでした。
理解するために、Python仮想マシンスタックがどのように機能するかを見てみましょう。何をするのか理解できない非常に単純なコードがいくつかあります。
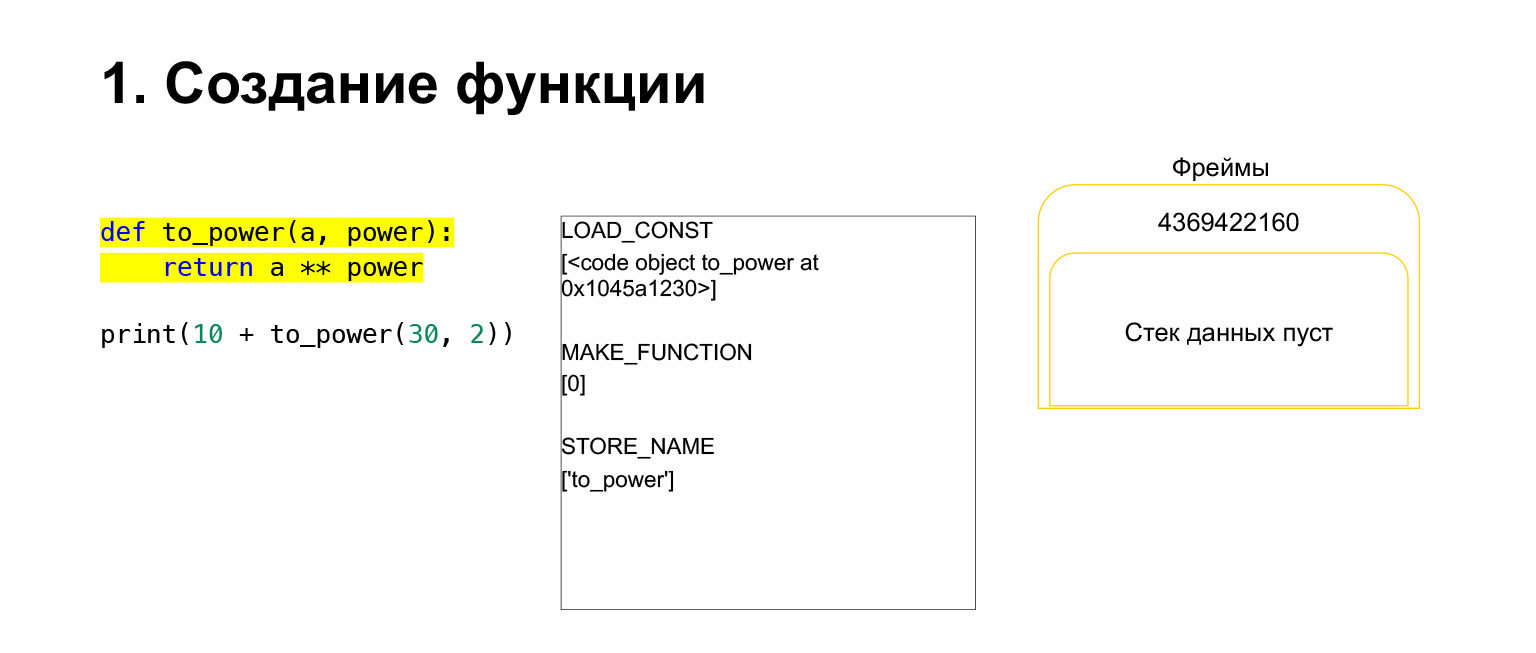
左側はコードです。現在調査中の部分は黄色で強調表示されています。 2番目の列には、この部分のバイトコードがあります。 3番目の列には、スタックのあるフレームが含まれています。つまり、各FrameObjectには独自の実行スタックがあります。
Pythonは何をしますか?それは順番に進み、中央の列のバイトコードが実行され、スタックで機能します。
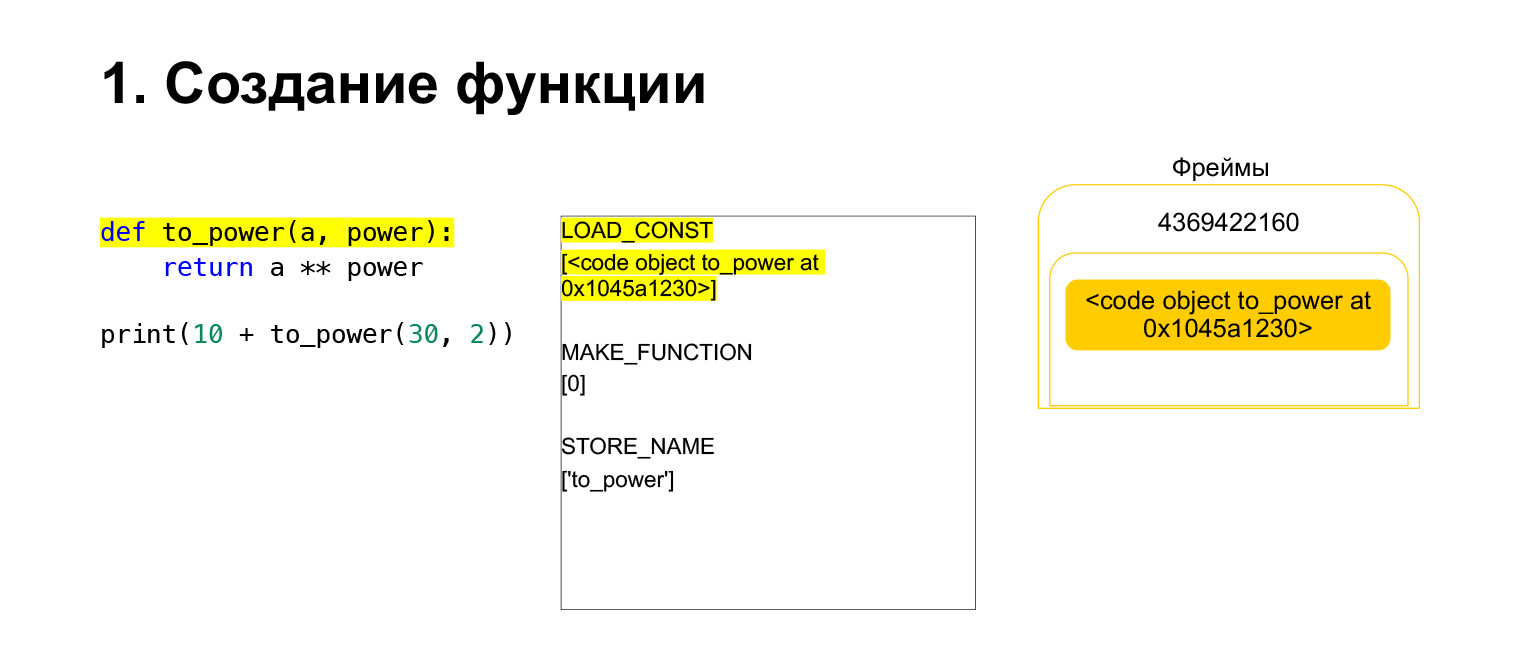
LOAD_CONSTと呼ばれる最初のopcodeを実行しました。定数をロードします。この部分をスキップし、そこにCodeObjectが作成され、定数のどこかにCodeObjectがありました。 Pythonは、LOAD_CONSTを使用してスタックにロードしました。これで、このフレームのスタックにCodeObjectができました。先に進むことができます。
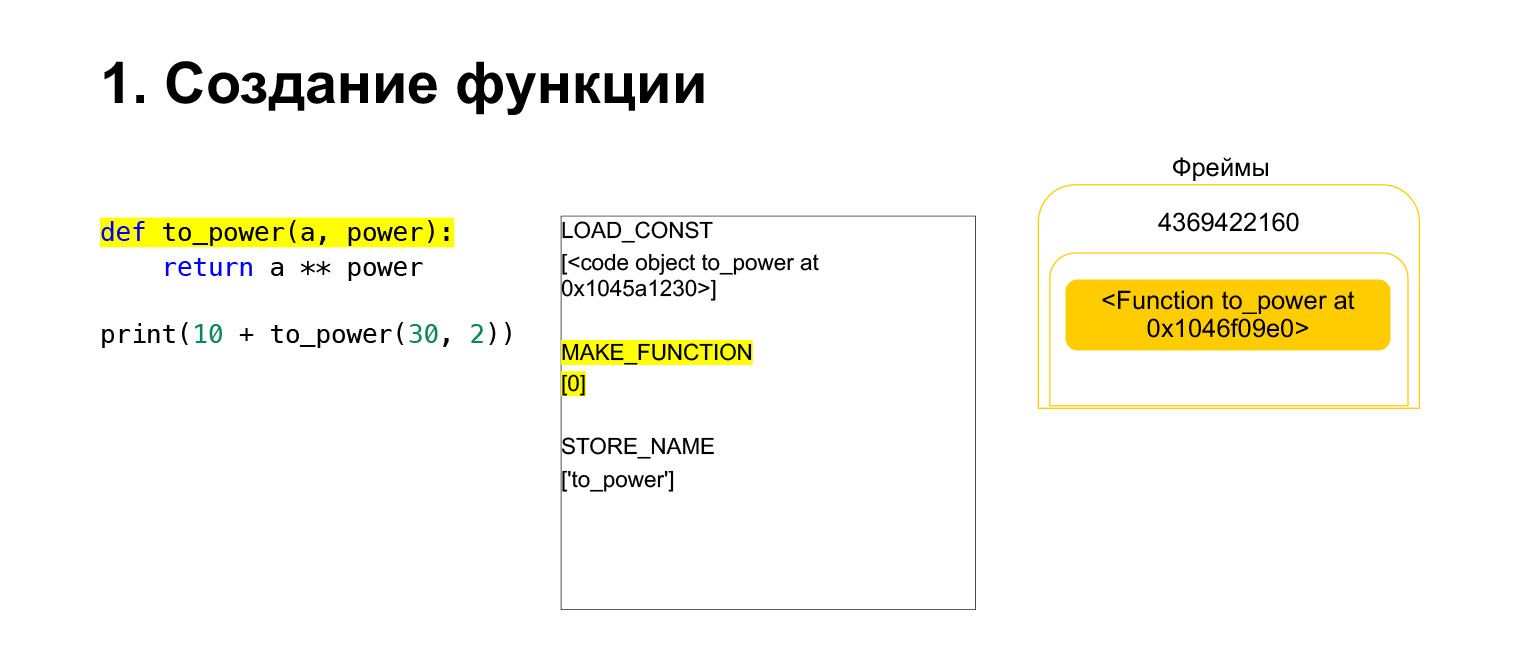
次に、PythonはopcodeMAKE_FUNCTIONを実行します。 MAKE_FUNCTIONは明らかに関数を作成します。スタックにCodeObjectがあることを前提としています。何らかのアクションを実行し、関数を作成して、関数をスタックにプッシュします。これで、フレームスタックにあったCodeObjectの代わりにFUNCTIONができました。そして、この関数を参照できるように、to_power変数に配置する必要があります。
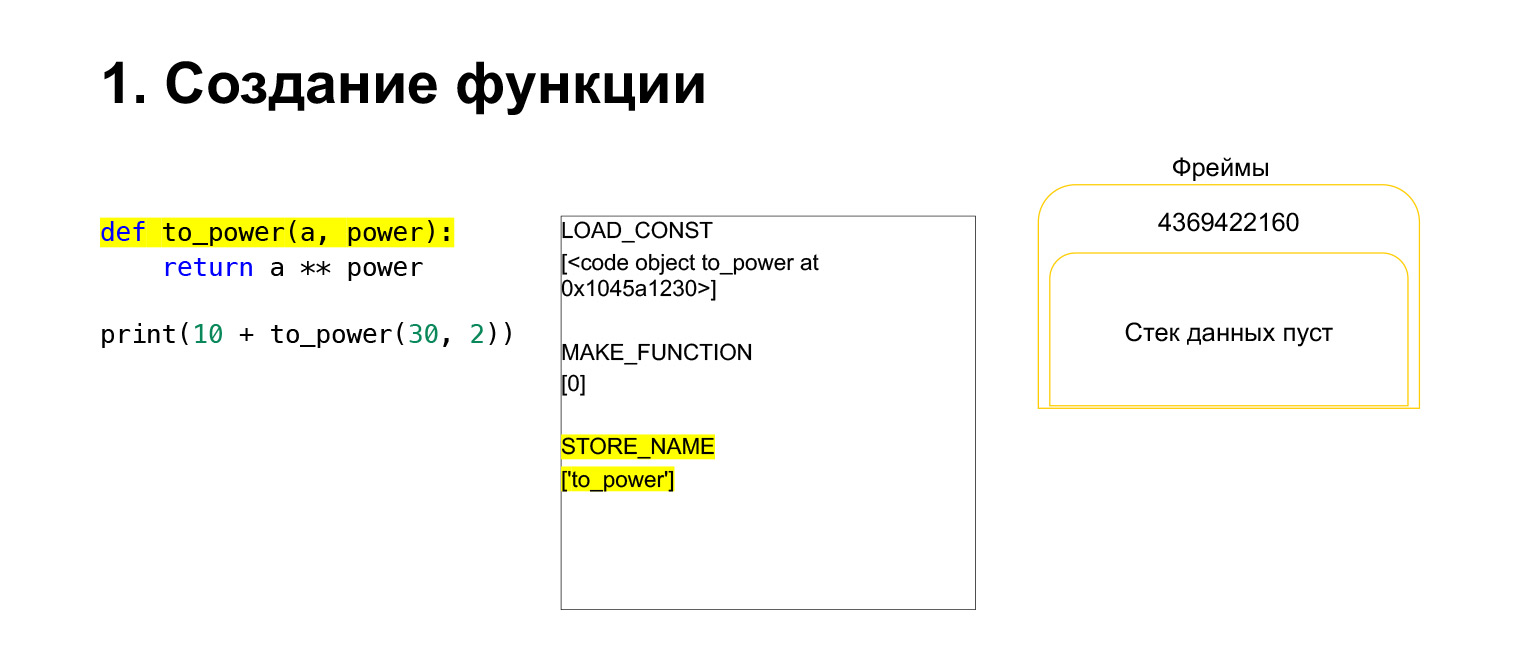
Opcode STORE_NAMEが実行され、to_power変数に配置されます。スタックに関数がありましたが、これはto_power変数であり、参照できます。
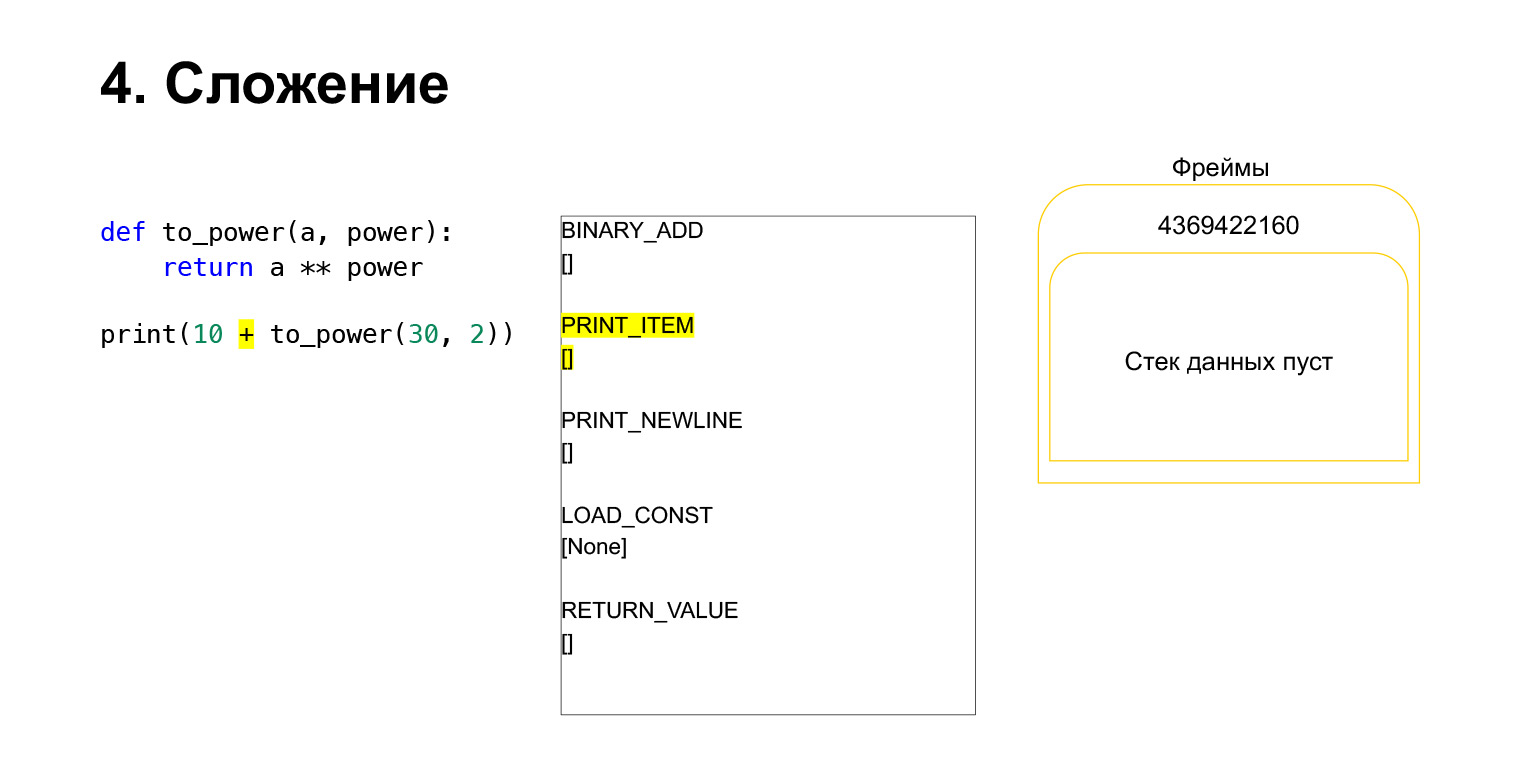
次に、10 +この関数の値を出力します。
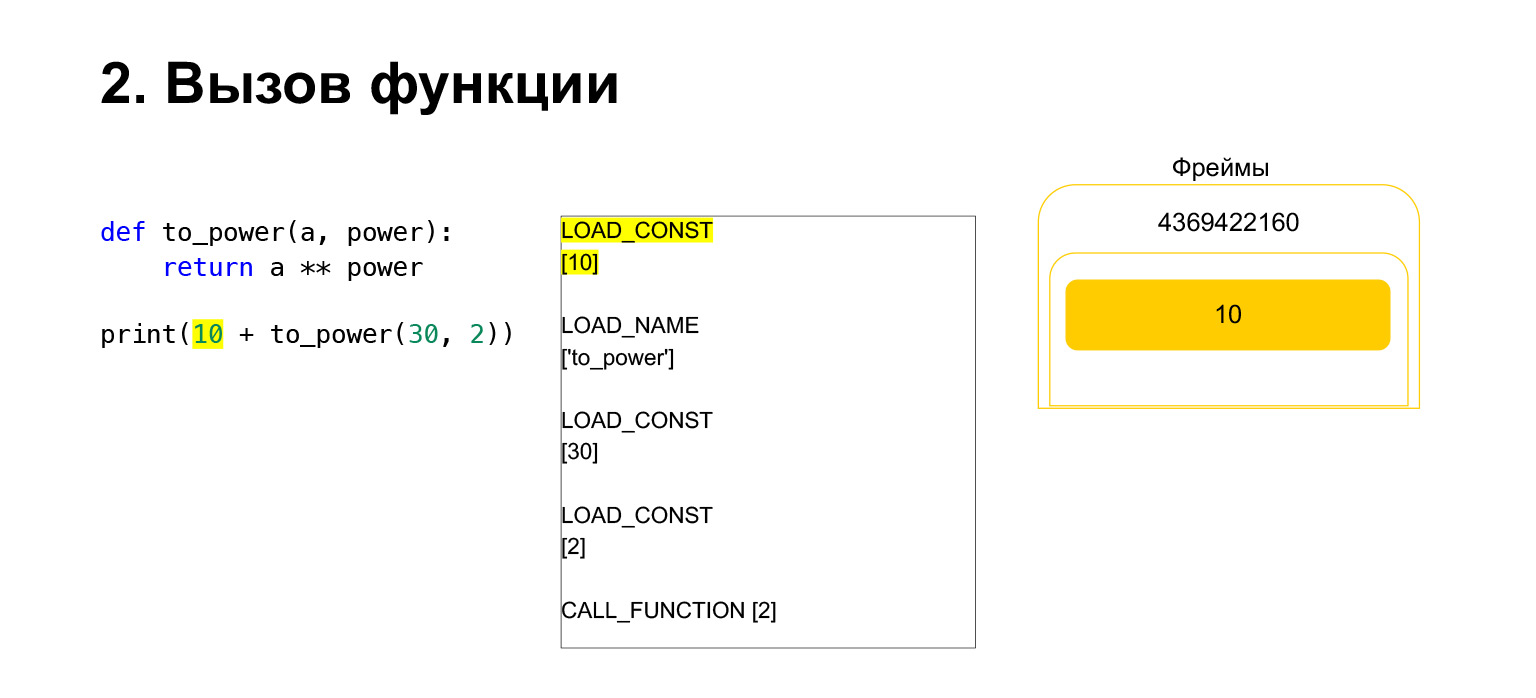
Pythonは何をしますか?これはバイトコードに変換されました。私たちが持っている最初のopcodeはLOAD_CONSTです。トップ10をスタックにロードします。スタックに12個登場しました。次に、to_powerを実行する必要があります。

この機能は次のように実行されます。位置引数がある場合(残りは今のところ調べません)、最初のPythonは関数自体をスタックに配置します。次に、すべての引数を入力し、関数引数の引数番号を使用してCALL_FUNCTIONを呼び出します。
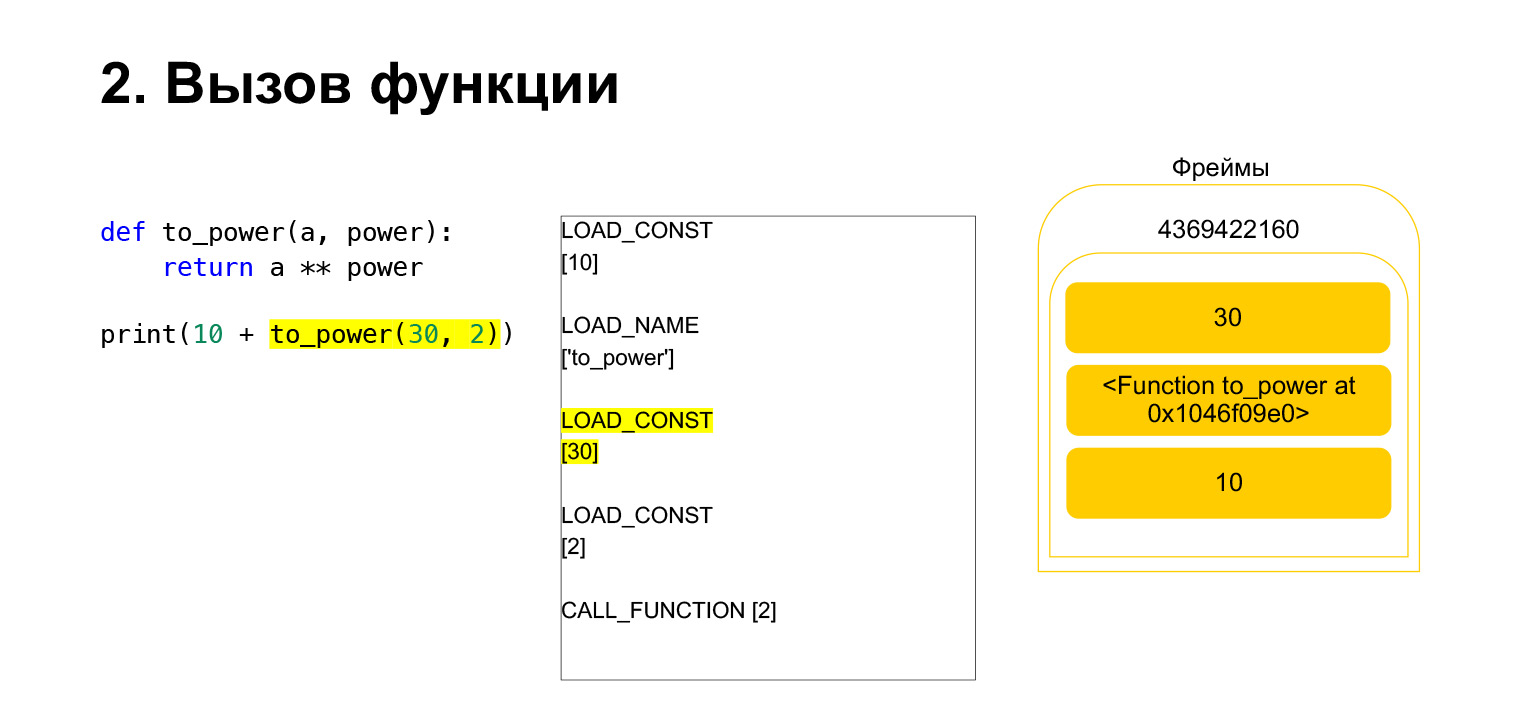
最初の引数をスタックにロードしました。これは関数です。
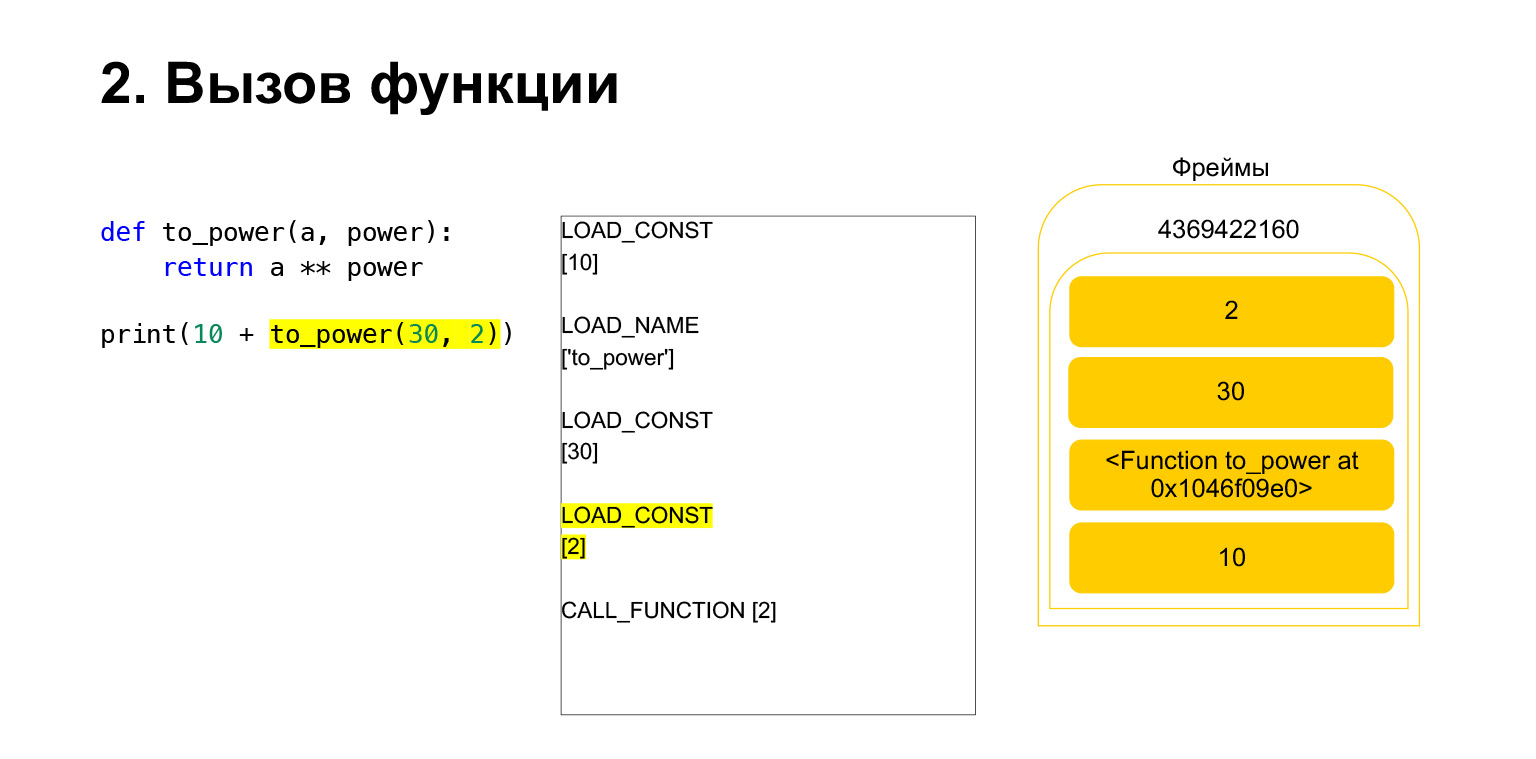
さらに2つの引数(30と2)をスタックにロードしました。これで、スタックに関数と2つの引数ができました。スタックの一番上が一番上にあります。 CALL_FUNCTIONが私たちを待っています。 CALL_FUNCTION(2)と言います。つまり、2つの引数を持つ関数があります。 CALL_FUNCTIONは、スタック上に2つの引数があり、その後に関数が続くことを想定しています。 2、30、およびFUNCTIONがあります。
進行中のOpcode。
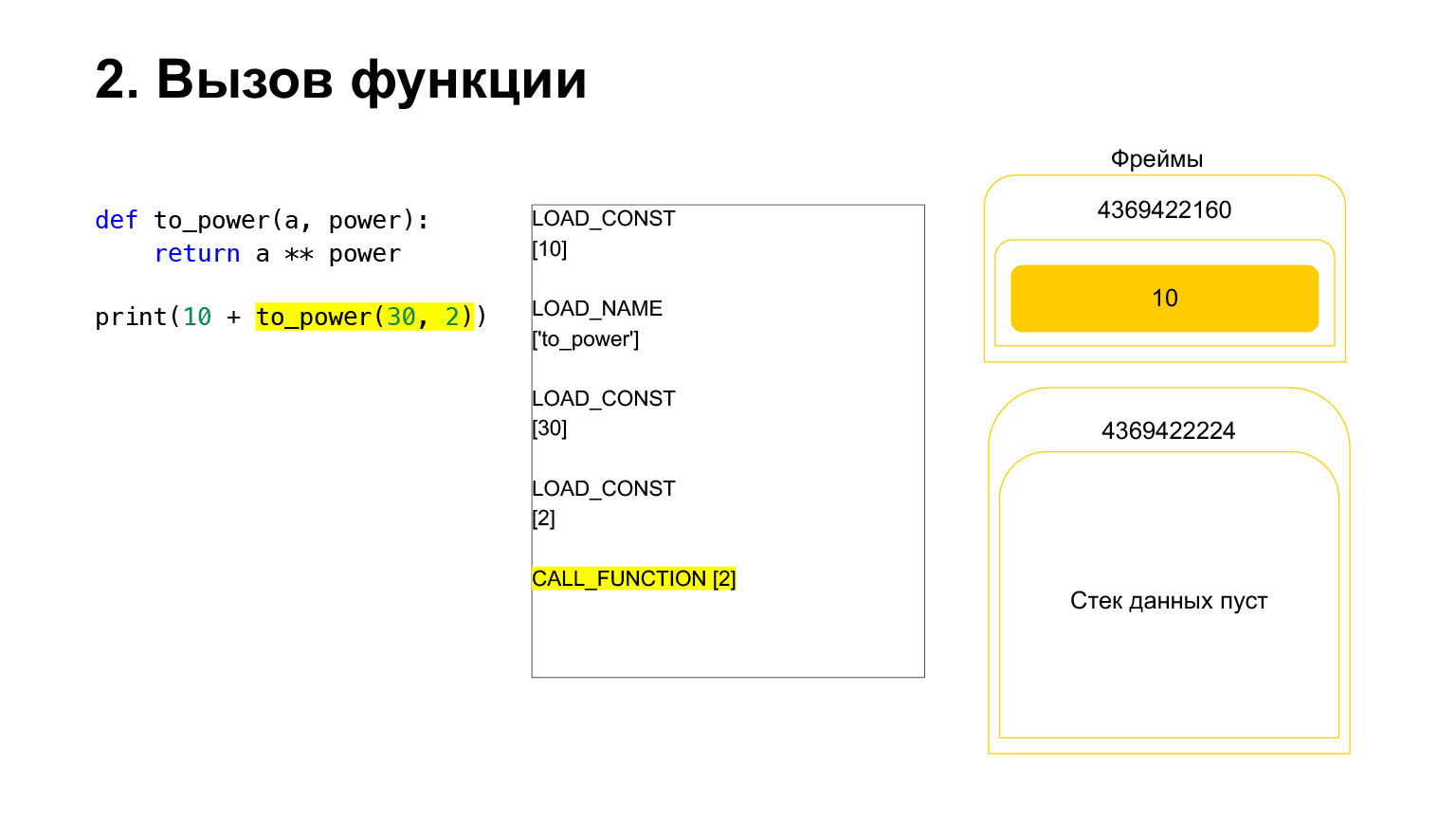
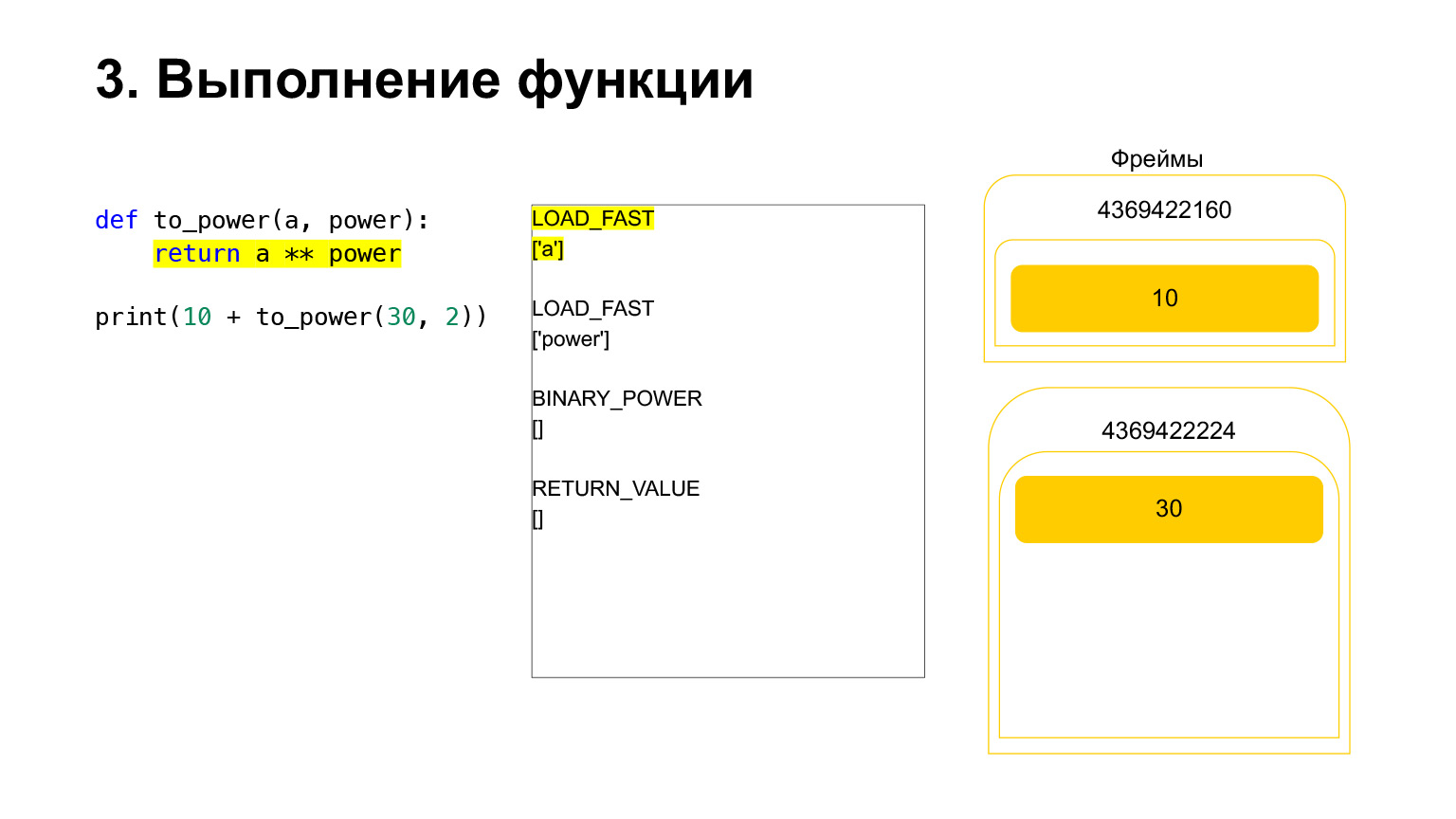
したがって、私たちにとっては、そのスタックが離れると、新しい関数が作成され、そこで実行が行われます。
フレームには独自のスタックがあります。その機能のために新しいフレームが作成されました。それはまだ空です。
さらに実行が行われます。ここではすでに簡単です。 Aをパワーアップする必要があります。変数A-30の値をスタックにロードし、変数power-2の値をロードします。
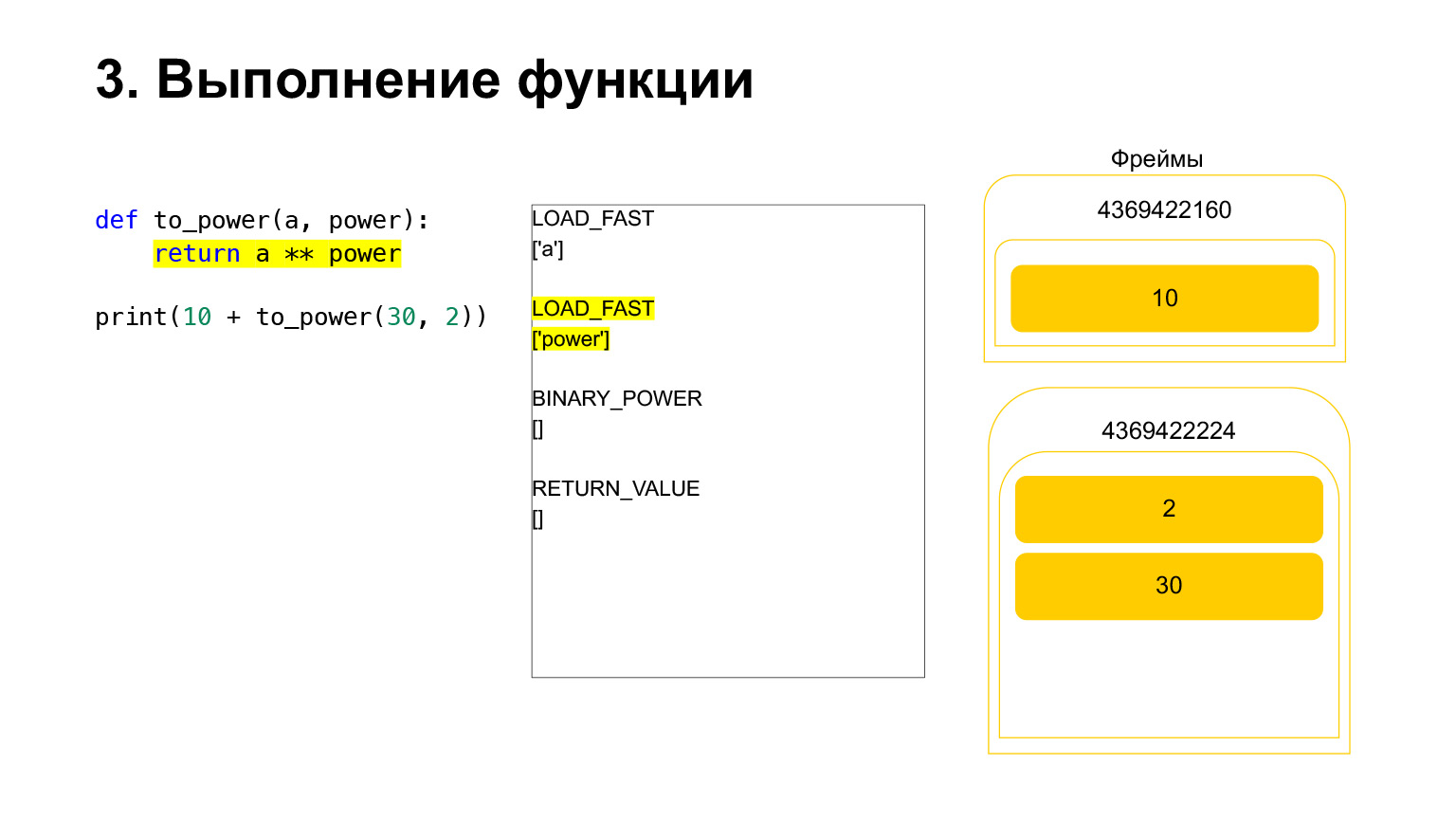
そしてopcodeBINARY_POWERが実行されます。
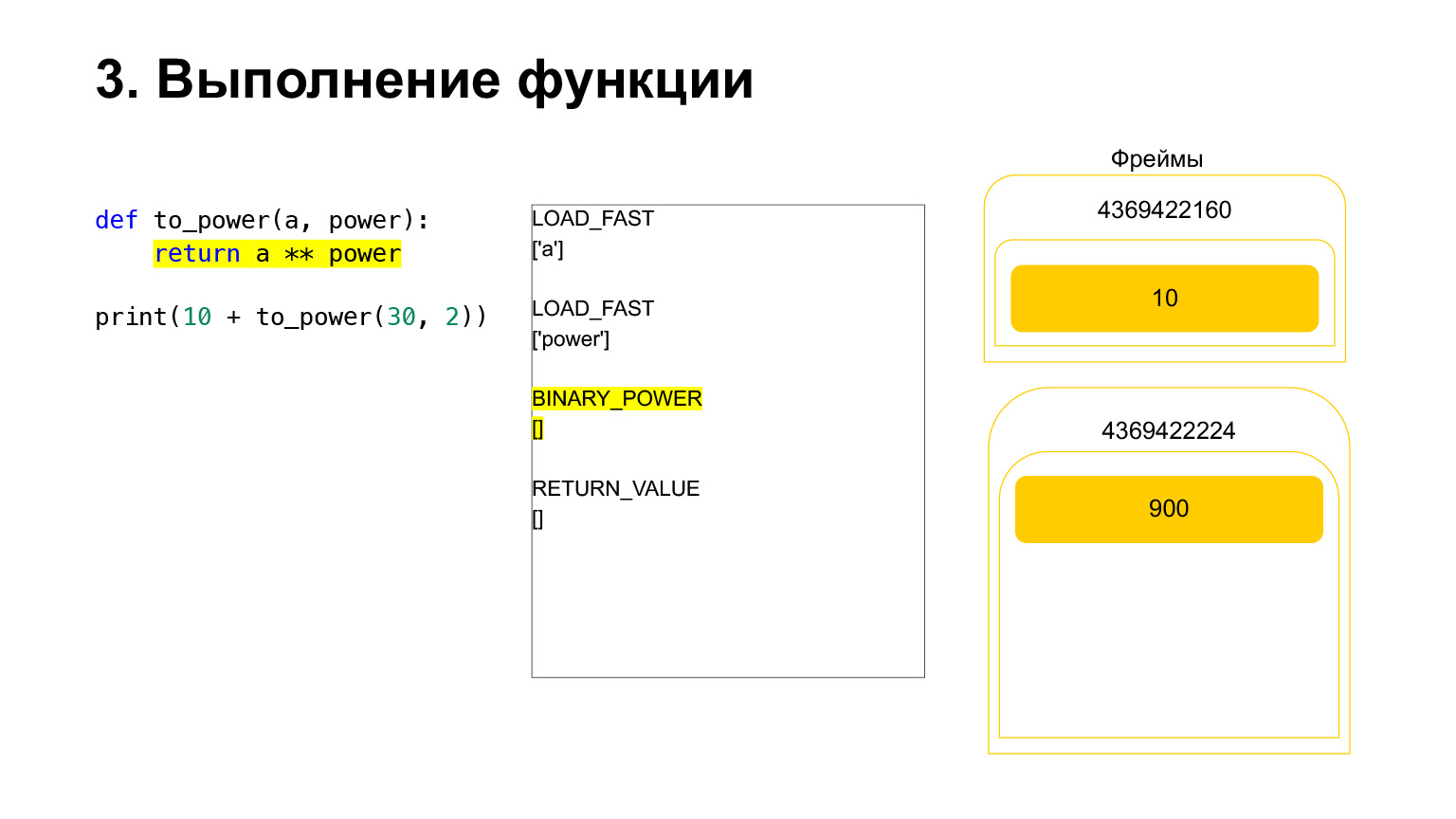
ある数値を別の数値の累乗にして、スタックに戻します。関数スタックで900になりました。
次のopcodeRETURN_VALUEは、スタックから前のフレームに値を返します。

これが実行の方法です。関数が完了しました。参照がなく、前の関数のフレームに2つの数字がある場合、フレームはおそらくクリアされます。

その後、すべてがほぼ同じです。追加が発生します。
(...)型とPyObjectについて話しましょう。
タイピング

オブジェクトは、2つの主要なフィールドがあるsish構造です。最初のフィールドはこのオブジェクトへの参照の数であり、2番目はオブジェクトのタイプです。もちろん、オブジェクトのタイプへの参照です。
他のオブジェクトは、PyObjectを囲むことによって継承します。つまり、float、浮動小数点数、PyFloatObjectがある構造を見ると、PyObject構造であるHEADがあり、さらに、このfloat自体の値が格納されているデータ(double ob_fval)があります。

そして、これはオブジェクトのタイプです。 PyObjectで型を確認しました。これは、型を示す構造です。実際、これは、このオブジェクトの動作を実装する関数へのポインターを含むC構造でもあります。つまり、そこには非常に大きな構造があります。たとえば、このタイプの2つのオブジェクトを追加する場合に呼び出される関数が指定されています。または、減算するか、このオブジェクトを呼び出すか、作成します。タイプでできることはすべて、この構造で指定する必要があります。

たとえば、Pythonのint、integersを見てみましょう。また、非常に簡略化されたバージョン。私たちは何に興味があるでしょうか? Intにはtp_nameがあります。 tp_hashがあることがわかります。ハッシュintを取得できます。 intでhashを呼び出すと、この関数が呼び出されます。 tp_callゼロがあり、定義されていません。これは、intを呼び出せないことを意味します。 tp_str-文字列キャストが定義されていません。 Pythonには、文字列にキャストできるstr関数があります。
スライドには載っていませんが、intを印刷できることはご存知でしょう。なぜここでゼロなのですか? tp_reprもあるため、Pythonにはstrとreprの2つの文字列受け渡し関数があります。文字列へのより詳細なキャスト。それは実際に定義されており、スライドに載っていなかっただけで、実際に文字列につながると呼び出されます。
最後に、tp_new(このオブジェクトの作成時に呼び出される関数)が表示されます。 tp_initはゼロです。 intは可変型ではなく、不変であることは誰もが知っています。作成後は、変更して初期化しても意味がないので、ゼロになります。

たとえば、Boolも見てみましょう。ご存知かもしれませんが、PythonのBoolは実際にはintから継承しています。つまり、Boolを追加して、互いに共有することができます。もちろん、これはできませんが、可能です。
tp_base(ベースオブジェクトへのポインタ)があることがわかります。オーバーライドされたのは、tp_base以外のすべてです。つまり、独自の名前、独自の表示機能があり、書き込まれるのは数字ではなく、真または偽です。数値としての表現では、いくつかの論理関数がそこでオーバーライドされます。 Docstringはそれ自身とその創造物です。他のすべてはintから来ています。

リストについて簡単に説明します。 Pythonでは、リストは動的配列です。動的配列は、次のように機能する配列です。事前にメモリ領域をある次元で初期化します。そこに要素を追加します。要素の数がこのサイズを超えるとすぐに、一定のマージンで、つまり1つではなく、複数の値で拡張するので、適切な点があります。
Pythonでは、サイズは0、4、8、16、25のように大きくなります。つまり、定数に対して漸近的に挿入を実行できるある種の式に従います。そして、リストに挿入機能からの抜粋があることがわかります。つまり、サイズ変更を行っています。サイズ変更がない場合は、エラーをスローして要素を割り当てます。Pythonでは、これはCで実装された通常の動的配列
です。(...)辞書について簡単に説明しましょう。それらはPythonのいたるところにあります。
辞書
オブジェクトでは、クラスの構成全体が辞書に含まれていることは誰もが知っています。多くのものがそれらに基づいています。ハッシュテーブル内のPythonの辞書。
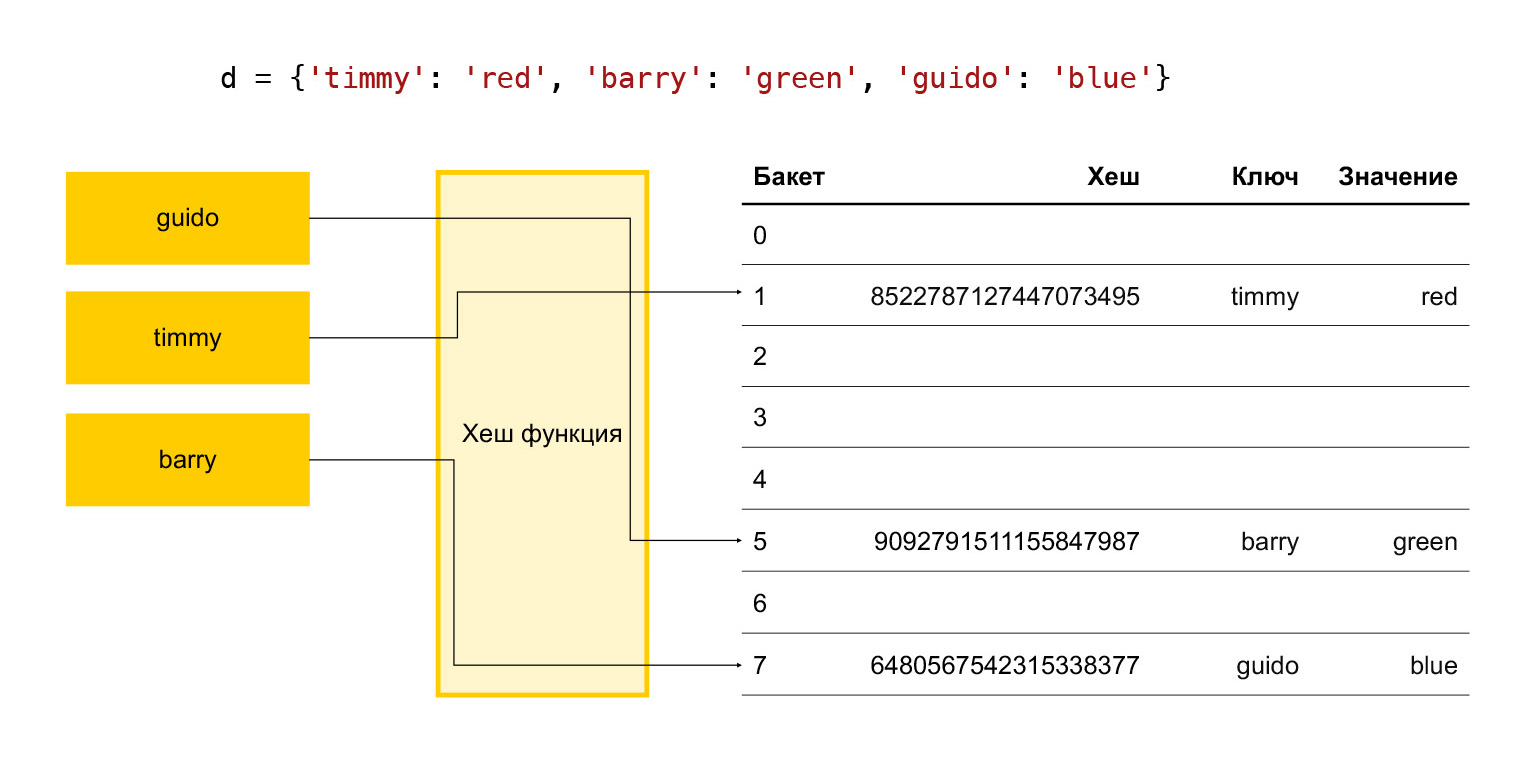
要するに、ハッシュテーブルはどのように機能しますか?いくつかの鍵があります:ティミー、バリー、ギド。それらを辞書に入れたいので、各キーをハッシュ関数で実行します。ハッシュになります。このハッシュを使用してバケットを検索します。バケットは、要素の配列内の単なる数値です。最終的なモジュロ分割が発生します。バケットが空の場合は、目的のアイテムをバケットに入れるだけです。空ではなく、すでにいくつかの要素が存在する場合、これは衝突であり、次のバケットを選択して、それが空いているかどうかを確認します。そして、無料のバケットが見つかるまで続けます。
したがって、追加操作を適切な時間内に実行するには、一定数のバケットを常に空けておく必要があります。そうしないと、この配列のサイズに近づくと、非常に長い間空きバケットを検索し、すべてが遅くなります。
したがって、Pythonでは、配列要素の3分の1が常にフリーであることが経験的に認められています。それらの数が3分の2を超える場合、配列は拡張されます。要素の3分の1が無駄になり、有用なものが何も保存されないため、これは良くありません。

スライドからのリンク
したがって、バージョン3.6以降、Pythonはそのようなことを行ってきました。左側には、以前の状態が表示されます。これらの3つの要素が格納されているスパース配列があります。 3.6以降、彼らはそのようなまばらな配列を通常の配列にすることを決定しましたが、同時にバケット要素のインデックスを別のインデックス配列に格納します。
インデックスの配列を見ると、最初のバケットにはNoneがあり、2番目のバケットにはこの配列のインデックス1の要素があります。
これにより、最初にメモリ使用量を削減でき、次に無料で箱から出してすぐに使用できます。順序付けられた配列。つまり、通常のsish appendを使用して、条件付きでこの配列に要素を追加すると、配列は自動的に順序付けられます。
Pythonが使用するいくつかの興味深い最適化があります。これらのハッシュテーブルを機能させるには、要素比較操作が必要です。ハッシュテーブルに要素を配置してから、要素を取得するとします。ハッシュを取得し、バケットに移動します。わかります:バケットがいっぱいです、そこに何かがあります。しかし、これは私たちが必要とする要素ですか?配置されたときに衝突が発生し、アイテムが実際に別のバケットに収まった可能性があります。したがって、キーを比較する必要があります。キーが間違っている場合は、衝突解決に使用されるのと同じ次のバケット検索メカニズムを使用します。そして次に進みましょう。

スライドからのリンク
したがって、キー比較機能が必要です。一般に、オブジェクトを比較する機能は非常に高価になる可能性があります。したがって、このような最適化が使用されます。まず、アイテムIDを比較します。ご存知のように、CPythonのIDはメモリ内の位置です。
IDが同じである場合、それらは同じオブジェクトであり、もちろん、それらは同じです。次に、Trueを返します。そうでない場合は、ハッシュを見てください。なんらかの方法で再定義していない場合、ハッシュはかなり高速な操作になるはずです。これら2つのオブジェクトからハッシュを取得して比較します。それらのハッシュが等しくない場合、オブジェクトは間違いなく等しくないため、Falseを返します。
そして、ごくまれなケースでのみ-ハッシュが等しいが、それが同じオブジェクトであるかどうかわからない場合-オブジェクト自体を比較する場合のみです。
興味深いことに、反復中にキーに何も挿入することはできません。これは間違いです。

内部的には、辞書にはversionという変数があり、辞書のバージョンを格納します。辞書を変更すると、バージョンが変更され、Pythonはこれを理解して、エラーをスローします。

より実用的な例では、辞書は何に使用できますか?タクシーには注文があり、注文のステータスは変更される可能性があります。ステータスを変更するときは、SMSの送信、注文の記録などの特定のアクションを実行する必要があります。
このロジックはPythonで記述されています。 「注文状況がそういうものなら、こうする」という形の巨大なifを書かないために、キーが注文状況であるという口述があります。また、VALUEへのタプルがあり、このステータスに移行するときに実行する必要のあるすべてのハンドラーが含まれています。これは一般的な方法であり、実際、スイッチの代わりになります。

タイプ別のいくつかの事柄。不変についてお話します。これらは不変のデータタイプであり、可変はそれぞれ可変タイプです:ディクテーション、クラス、クラスインスタンス、シート、そして多分何か他のもの。他のほとんどすべては文字列であり、数字だけです-それらは不変です。可変タイプとは何ですか?まず、コードを理解しやすくします。つまり、コードで何かがタプルであることがわかった場合、それ以上変更されないことを理解していますか。これにより、コードが読みやすくなります。次に何が起こるかを理解します。 tuple dsでは、アイテムを入力できません。あなたはこれを理解するでしょう、そしてそれはあなたとあなたのためにコードを読むすべての人々を読むのを助けるでしょう。
したがって、ルールがあります。何かを変更しない場合は、不変の型を使用することをお勧めします。それはまたより速い仕事につながります。 tupleが使用する定数は、pit_tuple、tap_tuple、max、およびCCの2つです。ポイントは何ですか?サイズが20までのすべてのタプルに対して、特定の割り当て方法が使用されます。これにより、この割り当てが高速になります。そして、それぞれのタイプのそのようなオブジェクトは、最大で2,000個まで存在する可能性があります。これはシートよりもはるかに高速なので、タプルを使用すると高速になります。
ランタイムチェックもあります。明らかに、何かをオブジェクトに接続しようとしていて、それがこの機能をサポートしていない場合は、エラーが発生します。これは、何か間違ったことをしたという何らかの理解です。 dictのキーは、存続期間中に変更されないハッシュを持つオブジェクトのみにすることができます。不変のオブジェクトのみがこの定義を満たします。それらだけがdictキーになることができます。

Cではどのように見えますか?例。左側はタプル、右側は通常のリストです。もちろん、ここではすべての違いが見えるわけではなく、私が見せたかったものだけが見えます。 tp_hashフィールドのリストにはNotImplementedがあります。つまり、リストにはハッシュがありません。タプルには、実際にハッシュを返す関数がいくつかあります。これが、とりわけタプルがdictキーになることができ、listができない理由です。
次に強調表示されるのは、アイテム割り当て関数sq_ass_itemです。リストでは、タプルではゼロです。つまり、タプルには当然何も割り当てることができません。

もう一つ。 Pythonは、要求するまで何もコピーしません。これも覚えておく必要があります。何かをコピーしたい場合は、たとえば、copy.deepcopy関数を持つcopyモジュールを使用します。違いはなんですか? copyは、兄弟リストなどのコンテナオブジェクトの場合、オブジェクトをコピーします。このオブジェクトにあったすべての参照は、新しいオブジェクトに挿入されます。また、deepcopyは、このコンテナー内およびそれ以降のすべてのオブジェクトを再帰的にコピーします。
または、リストをすばやくコピーする場合は、単一のコロンスライスを使用できます。あなたはコピーを手に入れるでしょう、そのようなショートカットは簡単です。
(...)次に、メモリ管理について説明します。
メモリ管理

sysモジュールを見てみましょう。メモリを使用しているかどうかを確認できる機能があります。インタープリターを起動してメモリ変更の統計を見ると、小さなオブジェクトを含む多くのオブジェクトが作成されていることがわかります。そして、これらは現在作成されているオブジェクトのみです。
実際、Pythonは実行時に多くの小さなオブジェクトを作成します。また、標準のmalloc関数を使用してそれらを割り当てると、メモリが断片化されているため、メモリの割り当てが遅いことにすぐに気付くでしょう。

これは、独自のメモリマネージャを使用する必要があることを意味します。要するに、それはどのように機能しますか? Pythonは、アリーナと呼ばれるメモリのブロックをそれぞれ256キロバイトずつ割り当てます。内部では、彼は自分自身を4キロバイトのプールにスライスします。これは、メモリページのサイズです。プール内には、16〜512バイトのさまざまなサイズのブロックがあります。
512バイト未満をオブジェクトに割り当てようとすると、Pythonは独自の方法でこのオブジェクトに適したブロックを選択し、そのオブジェクトをこのブロックに配置します。
オブジェクトの割り当てが解除され、削除された場合、このブロックは空きとしてマークされます。ただし、オペレーティングシステムには渡されないため、次の場所でこのオブジェクトを同じブロックに書き込むことができます。これにより、メモリ割り当てが大幅に高速化されます。

メモリを解放します。以前、PyObject構造を見ました。彼女はこのrefcnt-参照カウントを持っています。それは非常に簡単に機能します。このオブジェクトを参照すると、Pythonは参照カウントをインクリメントします。オブジェクトを取得するとすぐに、そのオブジェクトへの参照が消え、参照カウントの割り当てが解除されます。
黄色で強調表示されているもの。 refcntがゼロでない場合は、そこで何かを行っています。 refcntがゼロの場合、すぐにオブジェクトの割り当てを解除します。ガベージコレクターを待っているわけではありませんが、現時点でメモリをクリアしています。
delメソッドに出くわした場合、それは単に変数のオブジェクトへのバインドを削除します。また、クラスで定義できる__del__メソッドは、オブジェクトが実際にメモリから削除されたときに呼び出されます。オブジェクトに対してdelを呼び出しますが、それでも参照がある場合、オブジェクトはどこにも削除されません。そして、そのファイナライザー__del__は呼び出されません。それらは非常に似ていると呼ばれていますが。
リンクの数を確認する方法についての短いデモ。 getrefcount関数を持つお気に入りのsysモジュールがあります。オブジェクトへのリンクの数を確認できます。

もっとお話しします。オブジェクトが作成されます。リンクの数はそこから取得されます。興味深い詳細:変数AはTaxiOrderを指します。リンクの数を取ると、「2」が印刷されます。なぜだろうか?オブジェクト参照が1つあります。ただし、getrefcountを呼び出すと、このオブジェクトは関数内の引数に対してバンデージされます。したがって、このオブジェクトへの参照はすでに2つあります。1つ目は変数、2つ目は関数引数です。したがって、「2」が出力されます。
残りは些細なことです。オブジェクトに別の変数を割り当てると、3が得られます。次に、このバインディングを削除し、2を取得します。次に、このオブジェクトへのすべての参照を削除し、同時にファイナライザーが呼び出され、行が出力されます。

(...)CPythonには、構築できない興味深い機能がもう1つあり、ドキュメントのどこにも記載されていないようです。整数がよく使用されます。毎回再作成するのはもったいないでしょう。したがって、最も一般的に使用される数値であるPython開発者は、-5から255の範囲を選択しました。これらはシングルトンです。つまり、それらは一度作成され、インタープリターのどこかにあり、それらを取得しようとすると、同じオブジェクトへの参照を取得します。私たちはAとBを取り、それらを印刷し、それらのアドレスを比較しました。真実になった。そして、たとえば、このオブジェクトへの参照が105あります。これは、現在、非常に多くの参照があるためです。
たとえば1408のように、さらに大きな数をとると、これらのオブジェクトは等しくなく、それぞれ2つの参照があります。実際、1つ。
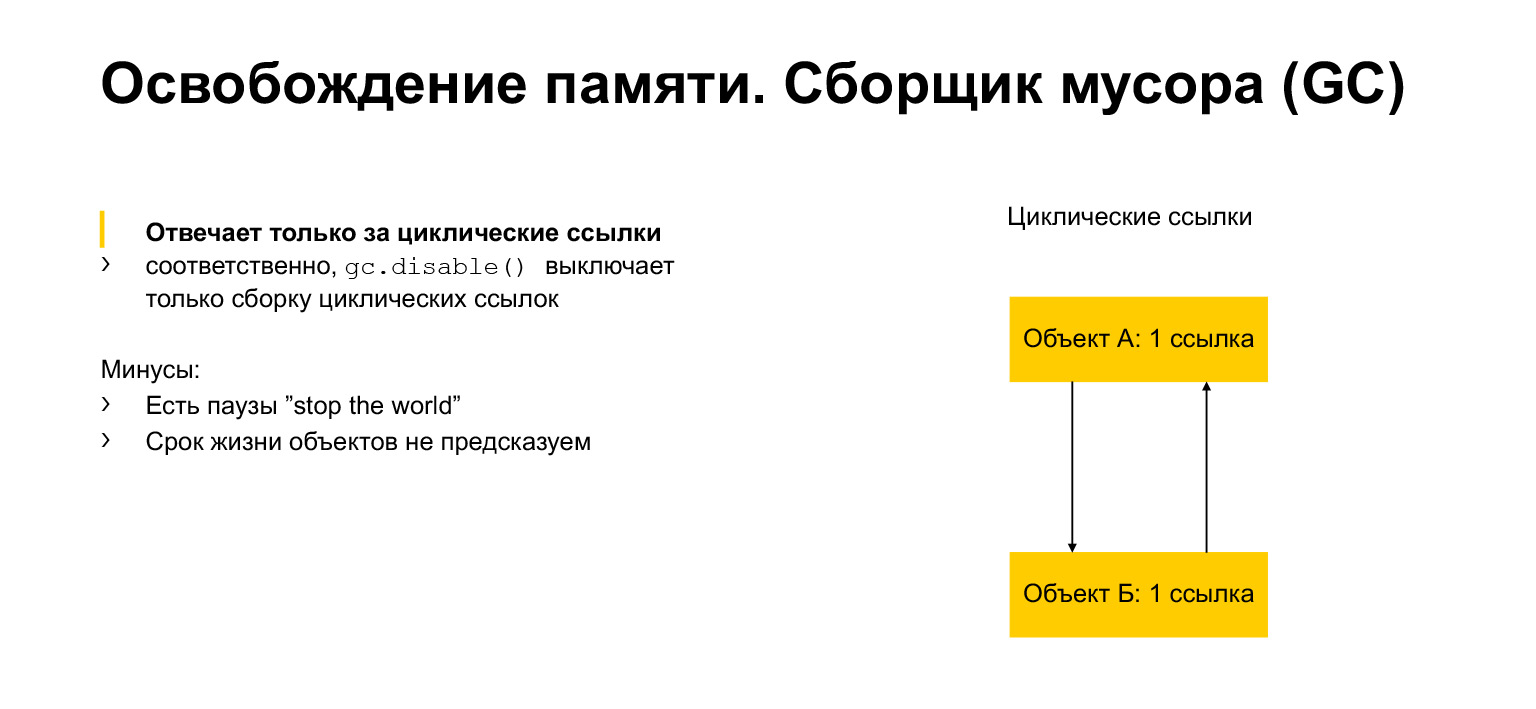
メモリの割り当てと解放について少し話しました。それでは、ガベージコレクターについて話しましょう。それは何のため?たくさんのリンクがあるようです。誰もオブジェクトを参照しなくなったら、それを削除できます。しかし、循環リンクを持つことができます。たとえば、オブジェクトはそれ自体を参照できます。または、例のように、それぞれがネイバーを参照する2つのオブジェクトが存在する場合があります。これはサイクルと呼ばれます。そして、これらのオブジェクトが別のオブジェクトへの参照を与えることはできません。しかし同時に、たとえば、プログラムの別の部分からは達成できません。アクセスできず、役に立たないため、削除する必要がありますが、リンクがあります。これはまさにガベージコレクターモジュールの目的です。サイクルを検出し、これらのオブジェクトを削除します。
彼はどのように働いていますか?まず、世代について簡単に説明し、次にアルゴリズムについて説明します。
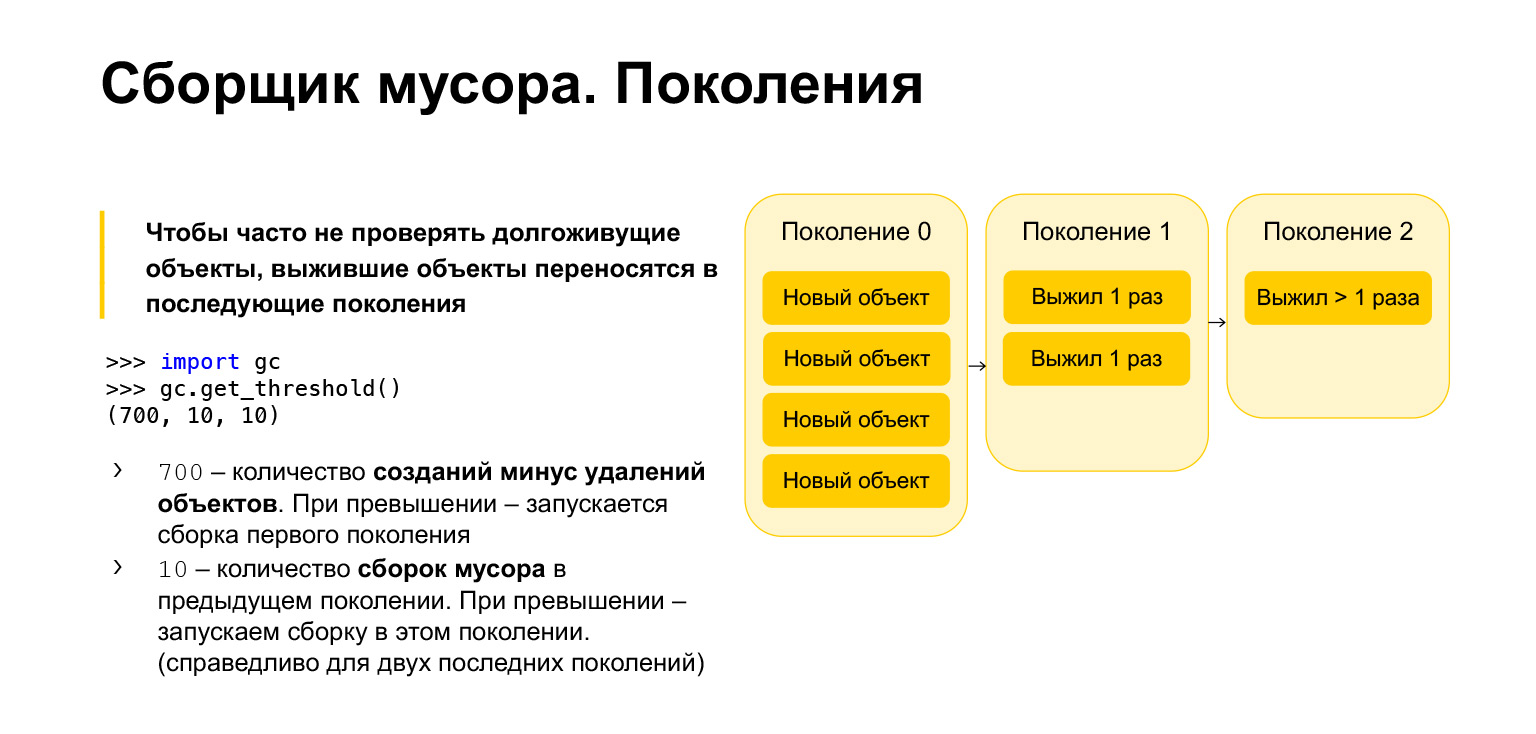
Pythonでガベージコレクターの速度を最適化するために、世代別です。つまり、世代を使用して機能します。 3世代あります。彼らは何のために必要ですか?ごく最近作成されたオブジェクトは、寿命の長いオブジェクトよりも不要である可能性が高いことは明らかです。関数の過程で何かを作成するとします。ほとんどの場合、関数を終了するときに必要ありません。一時変数を使用したループでも同じです。これらのオブジェクトはすべて、長い間存在していたオブジェクトよりも頻繁にクリーニングする必要があります。
したがって、すべての新しいオブジェクトはゼロ世代に配置されます。この世代は定期的に清掃されます。 Pythonには3つのパラメータがあります。各世代には独自のパラメータがあります。それらを取得し、ガベージコレクターをインポートし、get_threshold関数を呼び出して、これらのしきい値を取得できます。
デフォルトでは700、10、10があります。700とは何ですか?これは、オブジェクトの作成数から削除数を引いた数です。 700を超えるとすぐに、新世代のガベージコレクションが始まります。また、10、10は前世代のガベージコレクションの数であり、その後、現在の世代でガベージコレクションを開始する必要があります。
つまり、ゼロ世代を10回クリアすると、第1世代からビルドを開始します。第1世代を10回クリーニングした後、第2世代でビルドを開始します。したがって、オブジェクトは世代から世代へと移動します。彼らが生き残るならば、彼らは第一世代に移ります。彼らが第一世代のゴミ収集を生き残った場合、彼らは第二世代に移されます。第二世代から、彼らはもはやどこにも移動せず、永遠にそこにとどまります。
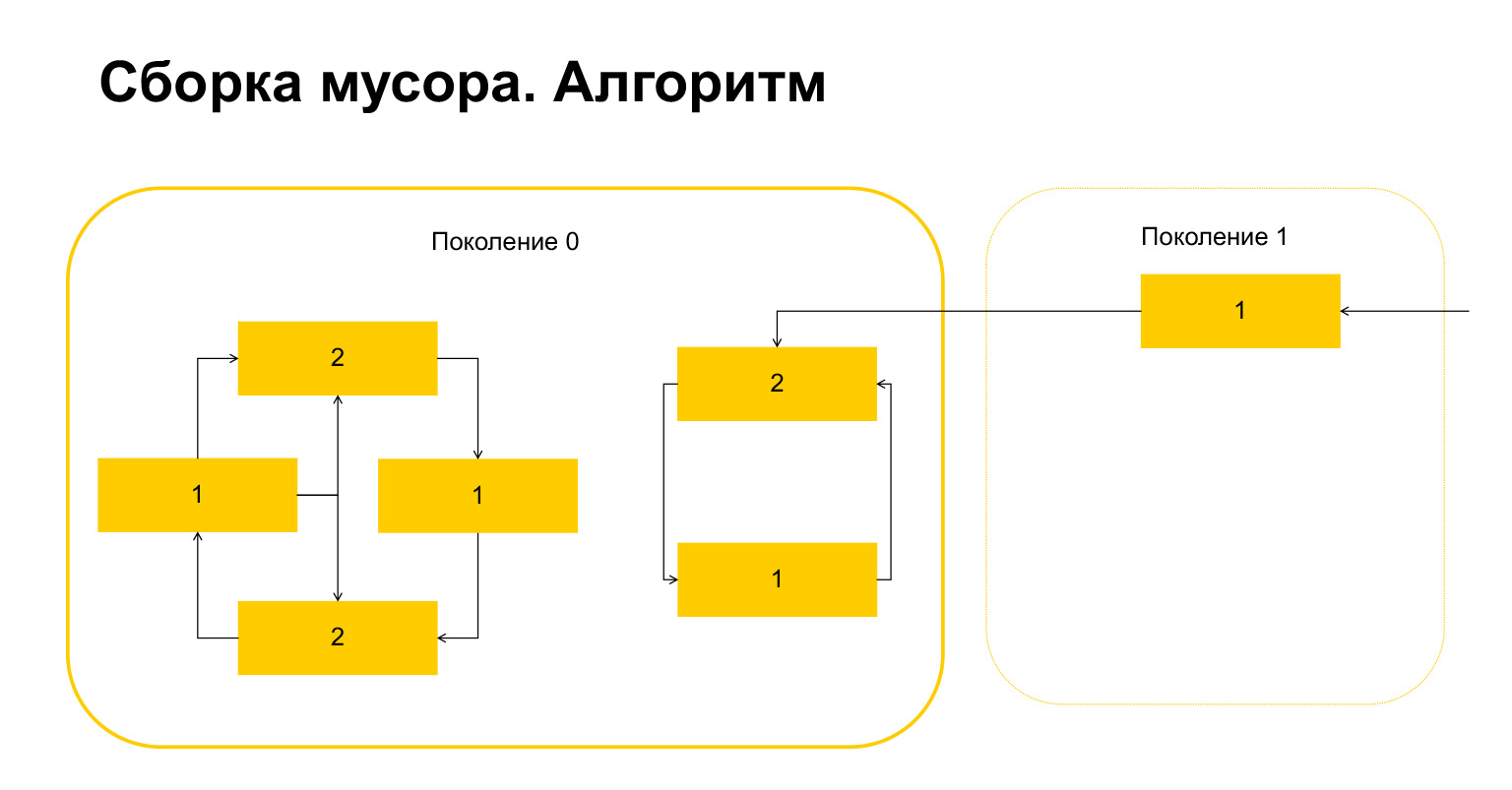
ガベージコレクションはPythonでどのように機能しますか?第0世代でガベージコレクションを開始するとします。いくつかのオブジェクトがあり、それらにはサイクルがあります。左側には相互に参照するオブジェクトのグループがあり、右側のグループも相互に参照しています。重要な詳細-それらは第1世代からも参照されます。Pythonはどのようにループを検出しますか?まず、オブジェクトごとに一時変数が作成され、このオブジェクトへの参照数が書き込まれます。これはスライドに反映されています。上のオブジェクトへのリンクが2つあります。ただし、第1世代のオブジェクトは、外部から参照されています。 Pythonはこれを覚えています。次に(重要です!)世代内の各オブジェクトを調べ、この世代内の参照の数だけカウンターを削除、デクリメントします。
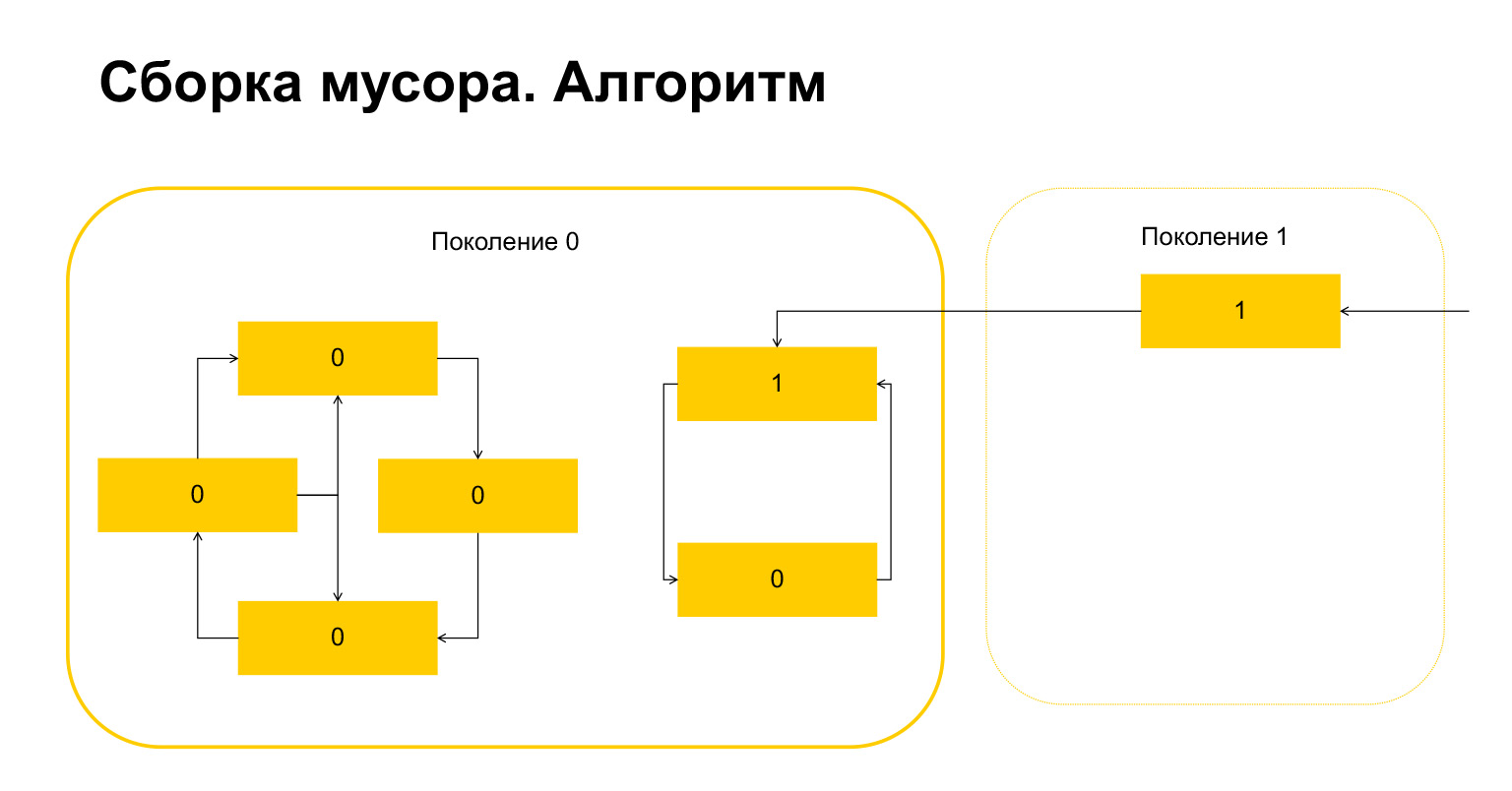
これが起こったことです。世代内で相互に参照するだけのオブジェクトの場合、この変数は構造上自動的にゼロになります。外部から参照されるオブジェクトのみが1つです。
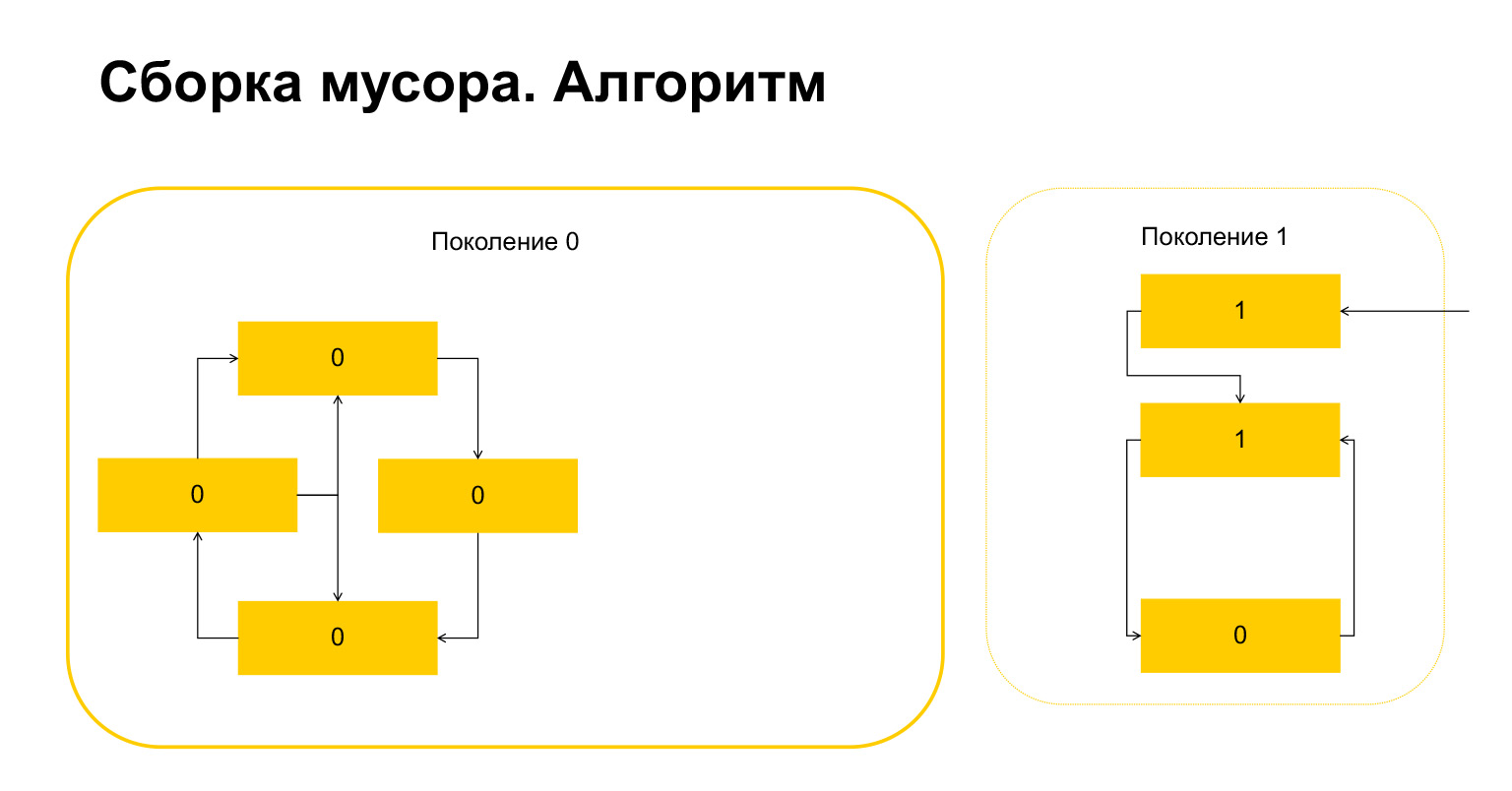
Pythonは次に何をしますか?彼は、ここに1つあるので、これらのオブジェクトが外部から参照されていることを理解しています。また、このオブジェクトまたはこのオブジェクトのいずれかを削除することはできません。そうしないと、無効な状況が発生するためです。したがって、Pythonはこれらのオブジェクトを第1世代に転送し、第0世代に残っているものはすべて削除し、クリーンアップします。ガベージコレクターについてのすべて。
(...) 進め。ジェネレータについて簡単に説明します。
ジェネレーター

ここでは、残念ながらジェネレーターの紹介はありませんが、ジェネレーターとは何かを説明してみましょう。これは、比較的言えば、yieldという単語を使用して実行のコンテキストを記憶する一種の関数です。この時点で、値を返し、コンテキストを記憶します。その後、もう一度参照して、その値を取得できます。
ジェネレーターで何ができますか?あなたはジェネレーターを生み出すことができます、それはあなたに値を返します、文脈を覚えておいてください。ジェネレーターを返却できます。この場合、StopIteration実行がスローされ、その中に値(この場合はY)が含まれます。
あまり知られていない事実:いくつかの値をジェネレーターに送信できます。つまり、ジェネレーターでsendメソッドを呼び出すと、Z(例を参照)がジェネレーターが呼び出すyield式の値になります。ジェネレーターを制御したい場合は、そこに値を渡すことができます。
そこで例外をスローすることもできます。同じこと:ジェネレータオブジェクトを取得してスローします。あなたはそこに間違いを投げます。最後の歩留まりの代わりにエラーが発生します。そして閉じる-ジェネレータを閉じることができます。次に、GeneratorExitの実行が発生し、ジェネレータは他に何も生成しないことが期待されます。

ここでは、CPythonでどのように機能するかについてお話ししたいと思います。実際には、ジェネレーターに実行フレームがあります。そして覚えているように、FrameObjectにはすべてのコンテキストが含まれています。このことから、コンテキストがどのように保持されるかは明らかです。つまり、ジェネレーターにフレームがあるだけです。

ジェネレーター関数を実行するとき、Pythonはどのようにしてそれを実行する必要がないことを認識しますが、ジェネレーターを作成しますか?調べたCodeObjectにはフラグがあります。また、関数を呼び出すと、Pythonはそのフラグをチェックします。 CO_GENERATORフラグが存在する場合、関数を実行する必要はなく、ジェネレーターを作成するだけでよいことを理解します。そして彼はそれを作成します。 PyGen_NewWithQualName関数。

実行はどうですか?GENERATOR_FUNCTIONから、ジェネレーターは最初にGENERATOR_Objectを呼び出します。次に、nextを使用してGENERATOR_Objectを呼び出し、次の値を取得できます。次の呼び出しはどのように行われますか?そのフレームはジェネレーターから取得され、変数Fに格納され、EvalFrameExインタープリターのメインループに送信されます。通常の機能と同様に実行されます。YIELD_VALUEマップコードは、ジェネレーターの実行を返し、一時停止するために使用されます。フレーム内のすべてのコンテキストを記憶し、実行を停止します。これは最後から2番目のトピックでした。
(...)例外とは何か、およびそれらがPythonでどのように使用されるかを簡単に要約します。
例外

例外は、エラー状況を処理する方法です。 tryブロックがあります。例外をスローする可能性のあるものを試してみることができます。単語raiseを使用してエラーを発生させることができるとしましょう。ただし、特定の種類の例外(この場合はSomeError)をキャッチできます。ただし、式なしですべての例外をキャッチします。 elseブロックはあまり使用されませんが、存在し、例外がスローされなかった場合にのみ実行されます。とにかくfinallyブロックが実行されます。
CPythonで例外はどのように機能しますか?実行スタックに加えて、各フレームにはブロックのスタックもあります。例を使用することをお勧めします。


ブロックスタックは、ブロックが書き込まれるスタックです。各ブロックには、タイプ、ハンドラー、ハンドラーがあります。ハンドラーは、このブロックを処理するためにジャンプするバイトコードアドレスです。それはどのように機能しますか?コードがあるとしましょう。 tryブロックを作成し、RuntimeError例外をキャッチするexceptブロックと、finallyブロックを作成しました。
これはすべてこのバイトコードに縮退します。 tryブロックのバイトコードの最初に、40と12の引数を持つ2つの2つのopcodeSETUP_FINALLYがあります。これらはハンドラーのアドレスです。 SETUP_FINALLYが実行されると、ブロックがブロックスタックに配置されます。つまり、私を処理するには、一方の場合は40番目のアドレスに、もう一方の場合は12番目のアドレスに移動します。
スタックの下の12は、elseRuntimeErrorを含む行を除いてです。これは、例外がある場合、SETUP_FINALLYタイプのブロックを検索するためにブロックスタックを調べることを意味します。アドレス12への遷移があるブロックを見つけて、そこに移動します。そして、例外とタイプの比較があります。例外のタイプがRuntimeErrorであるかどうかを確認します。等しい場合は実行し、等しくない場合は別の場所にジャンプします。
FINALLYは、ブロックスタックの次のブロックです。他に例外がある場合は、実行されます。次に、このブロックスタックで検索が続行され、次のSETUP_FINALLYブロックに移動します。たとえば、アドレス40を通知するハンドラーがあります。アドレス40にジャンプします。コードから、これがfinallyブロックであることがわかります。

CPythonでは非常に簡単に機能します。例外を発生させることができるすべての関数が値コードを返します。すべて問題がなければ0が返され、エラーの場合は関数の種類に応じて-1またはNULLが返されます。
Cでそのような挿入図を取ります。分割がどのように発生するかを確認します。また、Bがゼロに等しく、ゼロで除算したくない場合は、例外を記憶してNULLを返すというチェックがあります。そのため、エラーが発生しました。したがって、呼び出しスタックの上位にある他のすべての関数もNULLをスローする必要があります。これはインタープリターのメインループで確認し、ここにジャンプします。

これはスタックの巻き戻しです。すべてが私が言ったとおりです。ブロックスタック全体を調べて、そのタイプがSETUP_FINALLYであることを確認します。もしそうなら、非常に簡単なハンドラーを飛び越えます。実際、これがすべてです。
リンク
一般的な通訳:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
メモリ管理:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
例外:
bugs.python.org/issue17611