動機付けアプローチ
コンピュータビジョンタスクへの一般的に受け入れられているアプローチは、画像を3Dアレイ(高さ、幅、チャネル数)として使用し、それらに畳み込みを適用することです。このアプローチにはいくつかの欠点があります。
- すべてのピクセルが同じように作成されるわけではありません。たとえば、分類タスクがある場合、オブジェクト自体は背景よりも重要です。興味深いことに、コンピューターの視覚の問題で注意がすでに使用されていると著者が言っていない。
- 畳み込みは、離れたピクセルでは十分に機能しません。拡張された畳み込みとグローバル平均プーリングを使用するアプローチがありますが、それらは問題自体を解決しません。
- コンボリューションは、非常に深いニューラルネットワークでは十分に効率的ではありません。
その結果、著者は次のことを提案しています。画像をある種のビジュアルトークンに変換し、トランスフォーマーに送信します。

- まず、通常のバックボーンを使用して機能マップを取得します
- 次に、機能マップがビジュアルトークンに変換されます
- トークンはトランスフォーマーに供給されます
- トランス出力は分類問題に使用できます
- また、トランスフォーマーの出力を機能マップと組み合わせると、セグメンテーションタスクの予測を取得できます。
同様の方向の作品の中で、著者はまだアテンションに言及していますが、通常アテンションはピクセルに適用されるため、計算の複雑さが大幅に増加することに注意してください。彼らはまた、ニューラルネットワークの効率を改善するための作業について話しますが、近年、彼らはますます改善を提供していないと信じているので、他のアプローチを模索する必要があります。
ビジュアルトランスフォーマー
それでは、モデルがどのように機能するかを詳しく見てみましょう。
上記のように、バックボーンは機能マップを取得し、それらはビジュアルトランスフォーマーレイヤーに渡されます。
各ビジュアルトランスフォーマーは、トークナイザー、トランスフォーマー、およびプロジェクターの3つの部分で構成されています。
トークナイザー

トークナイザーはビジュアルトークンを取得します。実際、フィーチャマップを取得し、(H * W、C)で形状を変更

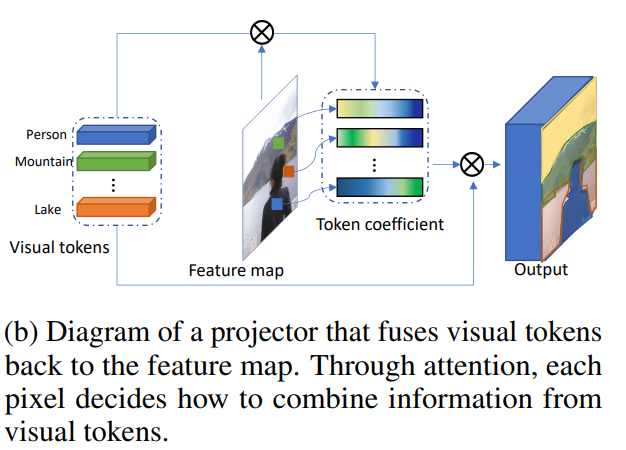
すると、トークンが取得されます。トークンの係数の視覚化は次のようになります。

位置エンコーディング
いつものように、トランスフォーマーにはトークンだけでなく、その位置に関する情報も必要です。

最初にダウンサンプルを実行し、次にトレーニングの重みを掛けてトークンと連結します。チャネル数を調整するには、1Dコンボリューションを追加します。
変成器
最後に、トランス自体。

ビジュアルトークンと機能マップの組み合わせ
これはプロジェクターになります。

動的トークン化
トランスフォーマーの最初のレイヤーの後、新しいビジュアルトークンを抽出できるだけでなく、前の手順で抽出したトークンを使用することもできます。訓練された重みは、それらを組み合わせるために使用されます。

ビジュアルトランスフォーマーを使用してコンピュータービジョンモデルを構築する
さらに、著者は、モデルがコンピューターの視覚問題にどのように適用されるかについて説明します。トランスフォーマーブロックには、機能マップCのチャネル数、ビジュアルトークンCtのチャネル数、ビジュアルトークンLの3つのハイパー
パラメーターがあります。モデルのブロック間の移行中にチャネル数が不適切であることが判明した場合、1Dおよび2Dコンボリューションを使用して必要なチャネル数を取得します。
計算を高速化し、モデルのサイズを小さくするには、グループ畳み込みを使用します。
著者は、記事に**疑似コード**ブロックを添付します。本格的なコードは、将来的に投稿されることが約束されています。
画像分類
ResNetを使用して、それに基づいてvisual-transformer-ResNets(VT-ResNet)を作成します。
ステージ1〜4を離れますが、最後のステージの代わりにビジュアルトランスフォーマーを配置します。
バックボーン出口-14x 14の機能マップ、VT-ResNetの深さに応じてチャネル数512または1024。機能マップから、1024チャネルの8つのビジュアルトークンが作成されます。変圧器の出力は分類のためにヘッドに送られます。

セマンティックセグメンテーション
このタスクでは、パノラマ機能ピラミッドネットワーク(FPN)が基本モデルとして採用されます。
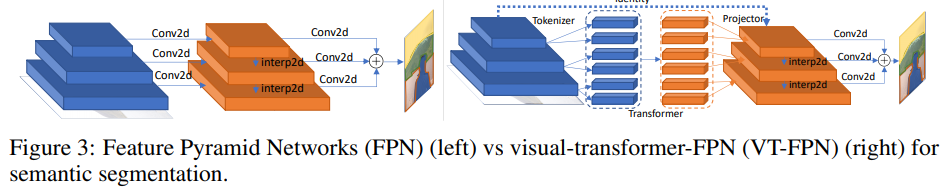
FPNでは、畳み込みは高解像度の画像で機能するため、モデルは重くなります。著者は、これらの操作をビジュアルトランスフォーマーに置き換えます。繰り返しますが、8つのトークンと1024のチャネル。
実験
ImageNet分類RMSPropを使用して
400エポックをトレーニングします。それらは0.01の学習率で始まり、5つのウォームアップエポックの間に0.16に増加し、次に各エポックに0.9875を掛けます。バッチ正規化とバッチサイズ2048が使用されます。ラベルスムージング、AutoAugment、確率的深度生存確率0.9、ドロップアウト0.2、EMA0.99985。
これは、これらすべてを見つけるために実行しなければならなかった実験の数です...
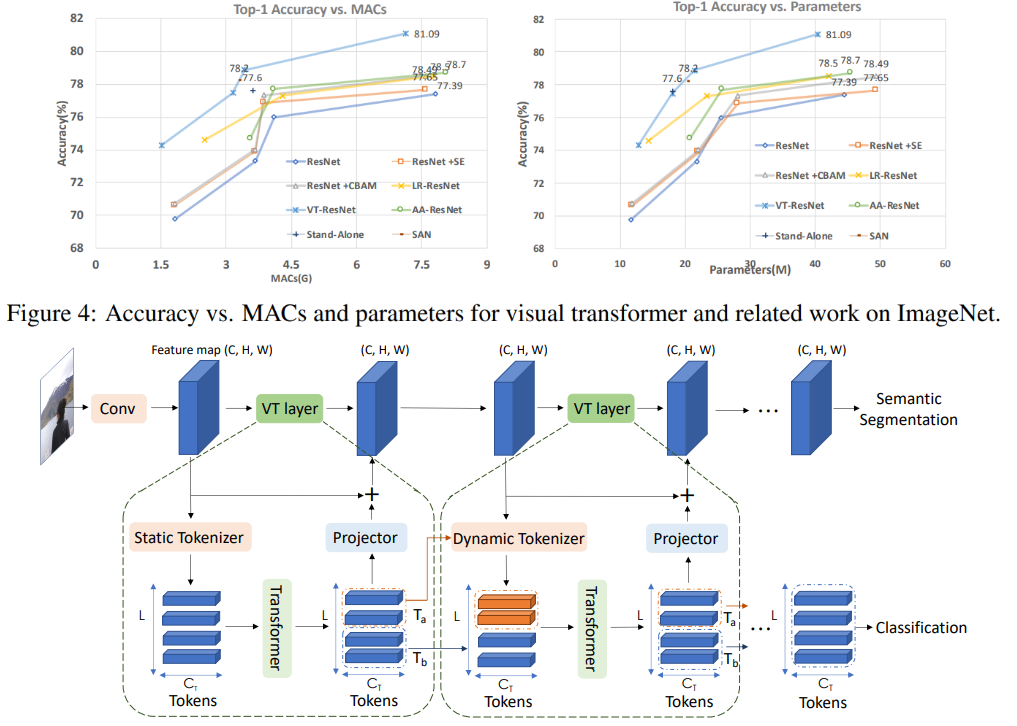
このグラフでは、このアプローチにより、計算回数とモデルのサイズを減らして、より高い品質が得られることがわかります。
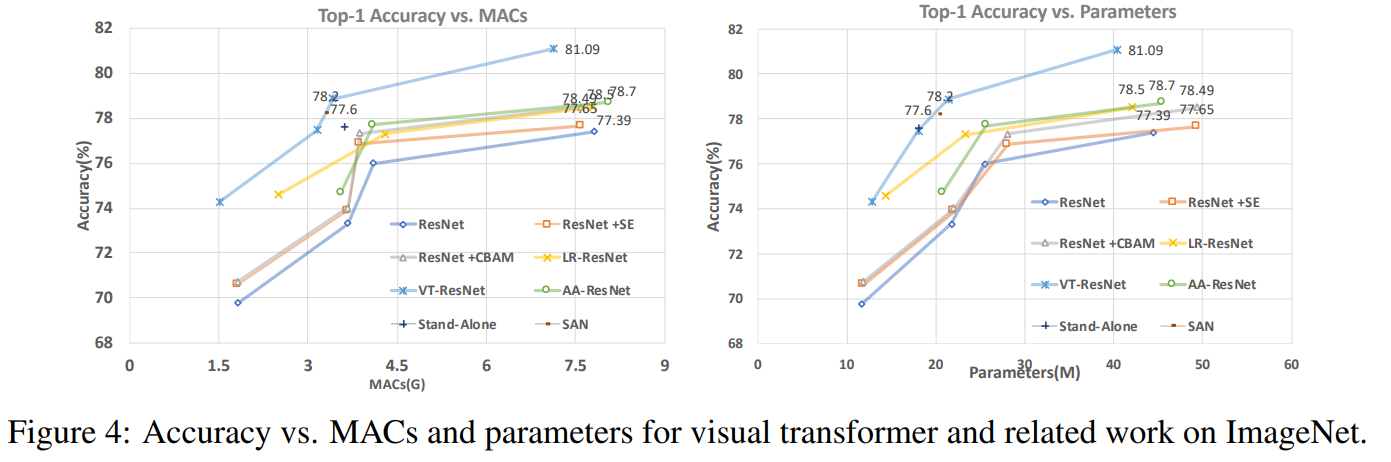
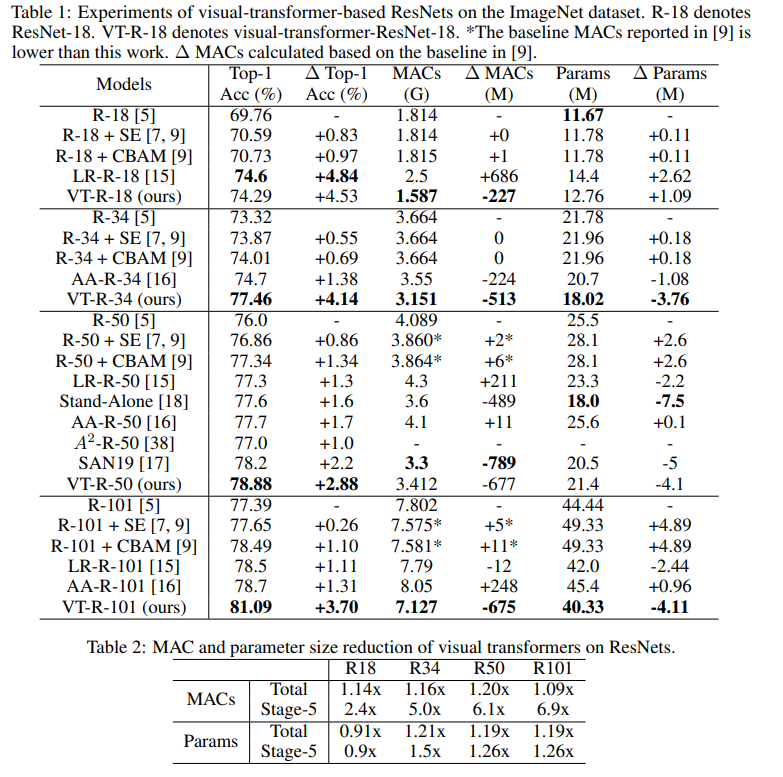
比較モデルの記事タイトル:
ResNet + CBAM-畳み込みブロックアテンションモジュール
ResNet + SE-スクイーズアンド
エキサイティングネットワークLR-ResNet-画像認識のためのローカルリレーションネットワーク
StandAlone-ビジョンモデルでのスタンドアロンの自己注意
AA-ResNet-拡張された畳み込みネットワークの注意SAN-
画像認識のための自己注意の調査
アブレーション研究
実験をスピードアップするために、VT-ResNet- {18、34}を使用して、90エポックをトレーニングしました。
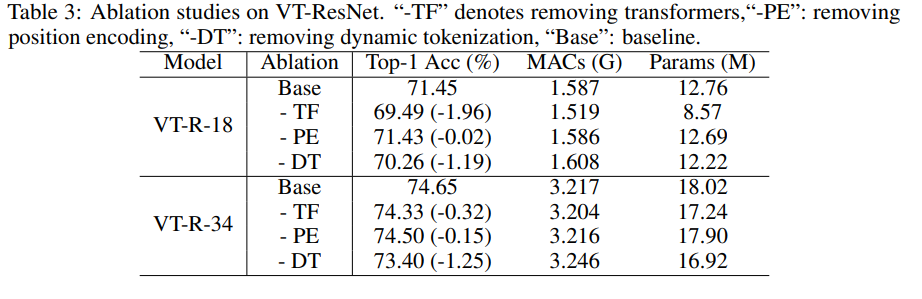
畳み込みの代わりに変圧器を使用すると、最大の利益が得られます。静的なトークン化ではなく動的なトークン化も大きな後押しとなります。位置エンコーディングでは、わずかな改善しかありません。
セグメンテーション結果

ご覧のとおり、メトリックはわずかに増加しましたが、モデルは6.5分の1のMACを消費します。
アプローチの潜在的な将来
実験によれば、提案されたアプローチにより、(計算コストの観点から)より効率的なモデルを作成でき、同時により良い品質を実現できます。提案されたアーキテクチャは、コンピュータビジョンのさまざまなタスクで正常に機能し、そのアプリケーションが、コンピュータビジョン(AR / VR、自律型自動車など)を使用するシステムの改善に役立つことが期待されています。
このレビューは、MTSの主要な開発者であるAndreyLukyanenkoによって作成されました。