
Webサイトからの写真。Sasha著•ストーリー Scikit-learnは、最も広く使用されているPythonマシン学習ライブラリの1つです。そのシンプルな標準インターフェースにより、データの前処理、トレーニング、最適化、およびモデル評価が可能になります。 このプロジェクトは、DavidCournapeauによって設計されました
は、Google Summer of Codeプログラムの一部として生まれ、2010年にリリースされました。設立以来、ライブラリは機械学習モデルを構築するための豊富なインフラストラクチャに進化してきました。新機能により、さらに多くのタスクを解決し、使いやすさを向上させることができます。この記事では、あなたが知らないかもしれない最も興味深い10の機能を紹介します。
1.組み込みデータセット
scikit-learnライブラリAPIには、生成されたデータと実際のデータの両方を含む組み込みデータセットがあります。1行のコードでそれらを使用できます。このデータは、学習しているだけの場合や、何かをすばやくテストしたい場合に非常に役立ちます。
また、特別なツールを使用して、回帰
make_regression()、クラスタリングmake_blobs()、および分類タスク用の合成データを自分で生成できますmake_classification()。
各メソッドは、モデルのトレーニングに直接使用できるように、X(機能)とY(ターゲット変数)にすでに分解されたデータを生成します。
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2.サードパーティの公開データセットへのアクセス
scikit-learnを介してさまざまな公開データセットに直接アクセスする場合は、openml.orgから直接データをインポートできる便利な機能を確認してください。このサイトには、機械学習プロジェクトで使用できる21,000を超えるさまざまなデータセットが含まれています。
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3.ベースラインモデルをトレーニングするためのすぐに使える分類子
プロジェクトの機械学習モデルを作成するときは、最初にベースラインモデルを作成することをお勧めします。これは、最も一般的なクラスを常に予測するダミーモデルです。これにより、より複雑なモデルをベンチマークするためのベンチマークが提供されます。さらに、たとえば、ランダムに選択されたデータのセット以上のものを生成するなど、その作業の品質を確認できます。
scikit-learnライブラリには
DummyClassifier()、分類の問題とDummyRegressor()回帰の操作用のライブラリがあります。
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4.視覚化のための独自のAPI
Scikit-learnには、他のライブラリをインポートせずにモデルがどのように機能するかを視覚化できる視覚化APIが組み込まれています。次のオプションが提供されます:依存関係プロット、エラーマトリックス、ROC曲線、Precision-Recall。
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()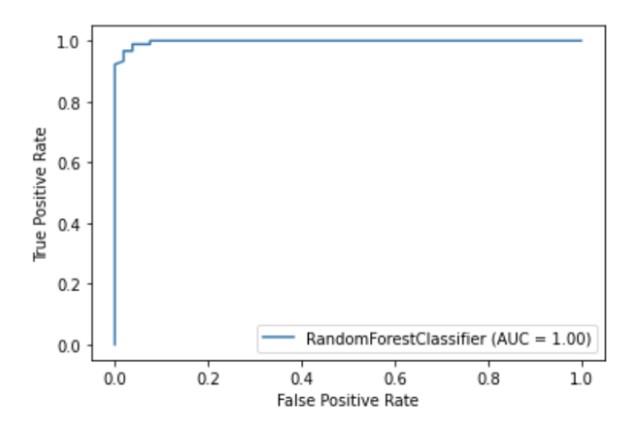
著者のイラスト
5.機能選択の組み込みメソッド
モデルの品質を向上させる方法の1つは、トレーニングで最も有用な機能のみを使用するか、最も情報量の少ない機能を削除することです。このプロセスは機能選択と呼ばれます。
Scikit-learnには、機能の選択を実行するためのいくつかの方法があり、そのうちの1つはです
SelectPercentile()。この方法では、指定された統計的推定方法に基づいて、最も有益な特徴のXパーセントを選択します。
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6.機械学習の過程でステージを接続するためのパイプライン
scikit-learnは、膨大な数の機械学習アルゴリズムを使用できることに加えて、前処理とデータ変換のための多くの機能も提供します。scikit-learnでの機械学習の過程で再現性とアクセス可能性を確保するために、トレーニングモデルのさまざまなステップと前処理段階をまとめたパイプラインが作成されました。
パイプラインは、ワークフローのすべてのステージを、fitメソッドとpredictメソッドで呼び出すことができる単一のオブジェクトとして格納します。パイプラインオブジェクトでfitメソッドを実行すると、前処理とモデルトレーニングの手順が自動的に実行されます。
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7.さまざまな機能の前処理方法を変更するColumnTransformer
多くのデータセットにはさまざまなタイプの機能が含まれており、前処理にはいくつかの異なる段階が必要です。たとえば、カテゴリデータと数値データが混在している場合、数値列をスケーリングし、ワンホットエンコーディングを使用してカテゴリ機能を数値に変換したい場合があります。
scikit-learnパイプラインにはColumnTransformer関数が装備されており、インデックスを作成するか、列名を指定することで、特定の列に最も適切な前処理方法を簡単に指定できます。
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8.パイプラインのHTML画像を簡単に取得できます
パイプラインは、特に実際のデータを操作する場合、非常に複雑になることがよくあります。したがって、scikit-learnを使用してパイプラインステップのHTML図を表示できると非常に便利です。
from sklearn import set_config
set_config(display='diagram')
lr
著者のイラスト
9.意思決定ツリーを視覚化するためのプロット機能
この関数を
plot_tree()使用すると、意思決定ツリーモデルに存在するステップの概要を作成できます。
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10.scikit-learn関数を拡張する多くのサードパーティライブラリ
scikit-learnと互換性があり、scikit-learnを拡張するサードパーティのライブラリは多数あります。
たとえば、カテゴリフィーチャの前処理方法の幅広い選択肢を提供するCategory Encodersライブラリ、またはより詳細なモデル解釈のためのELI5ライブラリ。
両方のリソースには、scikit-learnパイプラインを介して直接アクセスすることもできます。
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))清聴ありがとうございました!