仕事
与えられたもの:OpenWRTに基づく(そしてBuildRootに基づく)プロジェクトで、フィードとして接続された1つの追加リポジトリがあります。目的:追加のリポジトリをメインのリポジトリとマージします。
バックグラウンド
私たちはルーターを製造しており、ある日、お客様のアプリケーションをファームウェアに含めることができるようにしたいと考えていました。SDKの割り当て、ツールチェーン、およびそれに伴う問題に悩まされないようにするために、プロジェクト全体をプライベートリポジトリのgithubに配置することにしました。リポジトリ構造:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
誰もスパイしないように、私たち自身の開発のアプリケーションのいくつかをメインリポジトリから追加のリポジトリに転送することが決定されました。私たちはそれをすべてやり、それをgithubに置いて、それは良くなりました。
それ以来、橋の下にはたくさんの水が流れてきました…
クライアントは長い間なくなっており、リポジトリはgithubから削除されており、クライアントにリポジトリへのアクセスを許可するという考え自体が腐っています。ただし、プロジェクトには2つのリポジトリが残っていました。そして、gitに関連するすべてのスクリプト/アプリケーションは、そのような構造での作業を複雑にすることを余儀なくされています。簡単に言えば、それは技術的な負債です。たとえば、リリースの再現性を確保するには、2番目のリポジトリからのハッシュを使用してファイルsecondary.versionをプライマリリポジトリにコミットする必要があります。もちろん、スクリプトはそれを行います、そしてそれはそれにとってそれほど難しいことではありません。しかし、そのようなスクリプトは12個あり、それらはすべて、考えられるよりも複雑です。一般的に、私はセカンダリリポジトリをプライマリにマージすることを意図的に決定しました。同時に、リリースの再現性を維持するために、主な条件が設定されました。
このような条件が設定されると、セカンダリからすべてを個別にコミットしてから、上から2つの独立したツリーのマージコミットを行うなどの簡単なマージ方法は機能しません。フードを開けて手を汚さなければなりません。
Gitデータ構造
まず、gitリポジトリはどのようなものですか?これはオブジェクトのデータベースです。オブジェクトには、blob、tree、commitの3つのタイプがあります。すべてのオブジェクトは、コンテンツのsha1ハッシュによってアドレス指定されます。ブロブは、愚かなことに、追加の属性のないデータです。ツリーは、「<right> <type> <hash> <name>」(<type>はblobまたはtreeのいずれか)の形式のツリーおよびblobへのリンクのソートされたリストです。したがって、ツリーはファイルシステム内のディレクトリのようなものであり、blobはファイルのようなものです。コミットには、作成者とコミット者の名前、作成と追加の日付、コメント、ツリーのハッシュ、および親コミットへの任意の数(通常は1つまたは2つ)のリンクが含まれます。親コミットへのこれらのリンクは、オブジェクトベースを非周期的なダイグラフに変えます(外国人の間では、DAGとして知られています)。詳細を読むここで:
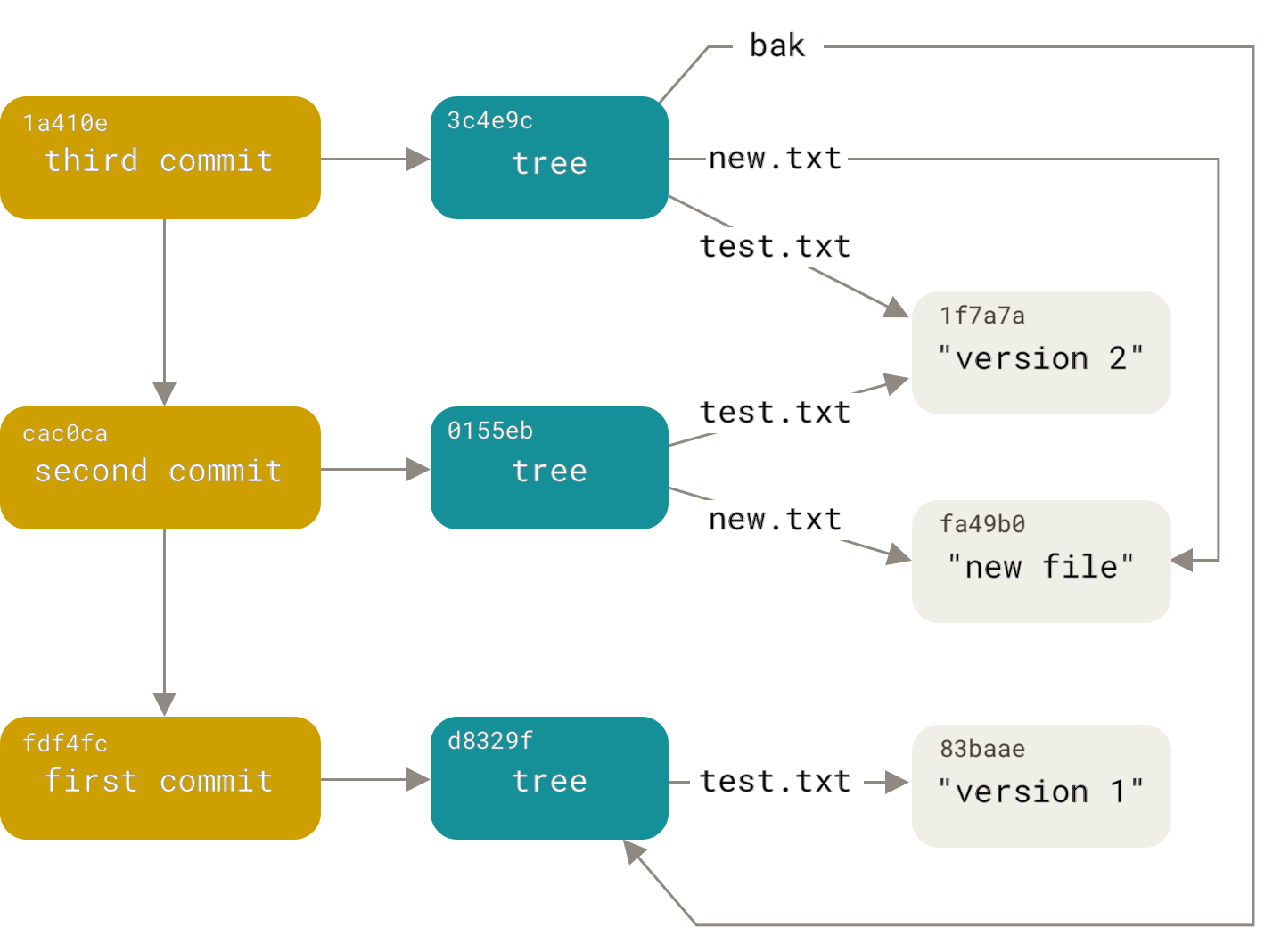
このように、私たちのタスクは、古いダイグラフの構造を繰り返して、新しいダイグラフを作成するタスクに変換されました。しかし、secondary.versionファイルのコミットを追加のリポジトリからのコミットに置き換えることで、

開発プロセスは従来のgitflowからはほど遠いものになります。私たちはすべてをマスターに託し、同時にそれを壊さないようにします。そこからビルドを行います。必要に応じて、安定化ブランチを作成し、それをマスターにマージして戻します。したがって、リポジトリグラフは、ブドウの木で編まれたセコイアの裸のトランクのように見えます。
分析
タスクは当然、分析と合成の2つの段階に分けられます。合成の場合、セカンダリリポジトリをすべてのタグとブランチに割り当て、2番目のリポジトリからコミットを挿入する瞬間から実行する必要があることは明らかです。次に、分析段階で、セカンダリコミットとこれらのコミットを挿入する場所を見つける必要があります。したがって、ノードは、secondary.versionファイルを変更するメイングラフのコミット(キーコミット)になる縮小グラフを作成する必要があります。さらに、このgitaのノードが親を参照している場合、新しいグラフでは、子孫への参照が必要です。名前付きタプルを作成します。
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
必要な予約
, . , .
私はそれを辞書に入れました:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}そこにsecondary.versionを変更するすべてのコミットを配置します。
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])そして、私は単純な再帰的アルゴリズムを構築します:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)つまり、いわば、キーノットを過去に伸ばして、新しい親に接続します。
私はそれを実行し、... RuntimeError最大再帰深度を超えました
どのように発生しましたか?コミットが多すぎませんか?gitlogとwcは答えを知っています。分割以降の合計コミット数は約20,000で、secondary.versionに影響するコミット数は約700です。レシピは既知であり、非再帰バージョンが必要です。
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(そして、これらのアルゴリズムはすべて、インタビューが通過するためにのみ必要であるとあなたは言いました!)私は
それを起動し、そして...それは機能します。1分、5、20 ...いいえ、それほど長くはかかりません。私は止める。どうやら、各コミットと各パスは何度も処理されます。ツリーにはいくつの枝がありますか?ツリーには40のブランチがあることが判明したため、マスターからのみ異なるパス。そして、キーコミットのかなりの部分につながる多くのパスがあります。何千年も保管していないので、各コミットが1回だけ処理されるようにアルゴリズムを変更する必要があります。これを行うには、処理された各コミットをマークするセットを追加します。ただし、小さな問題があります。このアプローチでは、異なるキーコミットを持つ異なるパスが同じコミットを通過でき、最初のパスのみがさらに進むため、一部のリンクが失われます。この問題を回避するために、セットを辞書に置き換えます。ここで、キーはコミットであり、値は到達可能なキーコミットのリストです:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)しばらくの間、この芸術的なメモリ交換の結果として、グラフは30秒で作成されます。
合成
これで、子リンクを介してグラフにリンクされたキーノードを持つcommit_mapができました。便宜上、これを一連のペア(祖先、子孫)に変換します。シーケンスは、ノードが子として発生するすべてのペアが、ノードが祖先として発生するペアの前に配置されることを保証する必要があります。次に、このリストを確認して、最初にメインリポジトリからコミットし、次に追加のリポジトリからコミットする必要があります。ここで、コミットには、ファイルシステムの状態であるツリーへのリンクが含まれていることを覚えておく必要があります。追加のリポジトリには、パッケージ/ディレクトリに追加のサブディレクトリが含まれているため、次に、すべてのコミットに対して新しいツリーを作成する必要があります。最初のバージョンでは、ファイルにblobを書き込み、gitに作業ディレクトリにインデックスを作成するように依頼しました。ただし、この方法はあまり生産的ではありませんでした。まだ20,000のコミットがあり、それぞれを再度コミットする必要があります。したがって、パフォーマンスは非常に重要です。GitPythonの内部を少し調べたところ、gitリポジトリオブジェクトに直接アクセスできるgitdb.LooseObjectDBクラスが見つかりました。これを使用すると、あるリポジトリのブロブとツリー(およびその他のオブジェクト)を別のリポジトリに直接書き込むことができます。gitオブジェクトデータベースのすばらしい特性は、任意のオブジェクトのアドレスがそのデータのハッシュであるということです。したがって、異なるリポジトリであっても、同じblobは同じアドレスを持ちます。
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)コミットはそれ自体で機能します。
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
ご覧のとおり、セカンダリリポジトリからのコミットは一括で追加されます。最初は、個々のコミットが追加されていることを確認しましたが、(突然!)新しいキーコミットに以前のバージョンのセカンダリリポジトリが含まれている場合があります(つまり、バージョンがロールバックされます)。このような状況では、iter_commitメソッドは空のリストを渡し、返します。その結果、リポジトリが正しくありません。したがって、現在のバージョンをコミットする必要がありました。
all_but_lastジェネレーターの出現の歴史は興味深いものです。説明は省略しましたが、期待どおりの動作をします。最初はただの挑戦がありました
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)