
- 何がそんなに多くのメモリを消費しているのでしょうか?
- これを回避する方法はありますか?
ここでは、これらの質問に対する答えをどのように探していたかについてお話したいと思います。Pythonコードのプロファイルを作成する必要があるときはいつでも、この資料を参照として使用する予定です。
プログラムのエントリポイント(
pylint/__main__.py)から始めて、Pylintの分析を開始し、for多くのファイルをチェックするプログラムで期待される「基本的な」ループに到達しました。
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
まず、このループ
print(«HI»)にステートメントを入れて、コマンドを実行したときに開始されるループであることを確認しpylint my_codeます。この実験は順調に進みました。
次に、Pylintの作業中にメモリに正確に何が保存されているかを調べることにしました。そこで、私はそれを使用して
heapy単純な「ヒープダンプ」を作成し、このダンプを分析して異常がないかどうかを確認しました。
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
ヒーププロファイルは、ほぼ完全にコールスタックフレームで構成されていました(
types.FrameType)。どういうわけか、こんなことを期待していました。ダンプ内の非常に多くの同様のオブジェクトにより、必要以上に多くのオブジェクトがあるように思われました。
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
このようなデータを簡単に操作できるプロファイルブラウザツールを見つけたのはこのときでした。
10ループの繰り返しごとにデータがファイルに書き込まれるようにダンプエンジンを構成しました。次に、操作中のプログラムの動作を示す図を作成しました。
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
私は以下に示すものに行き着きました。この図は、調査対象のPylintの実行中に、オブジェクト
type.FrameTypeとtype.TracebackType(トレース情報)が大量のメモリを消費したことを確認しています。

データ分析研究
の次の段階は、オブジェクトの分析でした
types.FrameType。 Pythonのメモリ管理メカニズムは、オブジェクトへの参照の数をカウントすることに基づいているため、データは、何かがそれを参照している限り、メモリに保持されます。私は、データをメモリに正確に「保持」するものを見つけることにしました。
ここで
objgraphは、Pythonメモリマネージャの機能を使用して、メモリ内にあるオブジェクトに関する情報を提供し、これらのオブジェクトを正確に参照しているものを見つけることができる優れたライブラリを使用しました。
実際、この種のソフトウェア研究を行うことができるのは素晴らしいことです。つまり、オブジェクトへの参照がある場合、このオブジェクトを参照するすべてのものを見つけることができます(C拡張子の場合、すべてがそれほどスムーズではありませんが、一般に、
objgraph適度に正確な情報を提供します)。私たちの前には、コードをデバッグするための優れたツールがあり、CPythonの内部メカニズムに関する多くの情報にアクセスできます。私にとって、これはPythonを使いやすい言語と考えるもう1つの理由です。
チーム
objgraph.by_type('types.TracebackType')が何も見つけられなかったので、最初、私はオブジェクトを探すことにつまずきました。そして、これは私がそのようなオブジェクトが膨大な数あることを知っていたという事実にもかかわらずです。タイプ名として文字列を使用する必要があることが判明しましたtraceback。この理由は私には完全には明らかではありませんが、それは何ですか。正しいコマンドは、最終的には次のようになります。
random.choice(objgraph.by_type('traceback'))
この構成は、オブジェクトをランダムに選択します
traceback。そして、助けobjgraph.show_backrefsを借りて、これらのオブジェクトを参照するものの図を作成できます。
結局、例外をスローするのではなく、100回繰り返した後にループ
for(import pdb; pdb.set_trace())で何が起こるかを調査することにしました。ランダムに選んだオブジェクトの勉強を始めましたtraceback。
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
最初はオブジェクトのチェーンしか見えなかった
tracebackので、100個のオブジェクトの深さまで登ることにしました...

トレースバックオブジェクトの分析結局のところ
、一部のオブジェクト
tracebackは同じタイプの他のオブジェクトを参照しています。よく良いです。そして、そのようなチェーンがたくさんありました。
しばらくの間、ビジネスであまり成功しなかったので、私はそれらを研究し、次に私が興味を持っている2番目のタイプのオブジェクトの研究に移りました-
FrameType(frame)。彼らはまた疑わしいように見えた。それらを分析すると、次のような図になりました。

フレームオブジェクトの解析オブジェクト
はオブジェクトを
traceback保持していることがわかりますframe(したがって、そのようなオブジェクトの数は同じです)。もちろん、これらすべては非常に紛らわしいように見えますが、オブジェクトframeは少なくとも特定のコード行を指しています。これらすべてが、私が1つの途方もなく単純なことを実現することにつながりました。私は、このような大量のメモリを使用してデータを見るのを気にしませんでした。私は間違いなくオブジェクト自体を見る必要がありますtraceback。
私はこの目標に向かって歩きました、それは、すべての可能な道の中で最も曲がりくねっているようです。つまり、によって作成されたダンプ内のアドレスを認識しました。
objgraph、次にメモリ内のアドレスを調べ、インターネットで「Pythonオブジェクトを取得する方法、そのアドレスを知っている」を検索しました。これらすべての実験の後、私は次の行動計画を思いつきました。
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
実際、Pythonに次のように言うことができます。「このメモリを見てください。ここには間違いなく少なくとも通常のPythonオブジェクトがあります。」
後で、のおかげで興味のあるオブジェクトへのリンクがすでにあることに気付きました
objgraph。つまり、私はそれらを使用することができました。Pylintで使用されているASTパーサーで
あるライブラリが
astroid、traceback例外処理コードを介してあらゆる場所でオブジェクトを作成しているように感じました。 「おもしろいトリック」と呼べるようなものがどこかで使われると、途中で同じことがどうやって簡単にできるのか忘れてしまうのではないかと思います。だから私はそれについて本当に文句を言いません。
オブジェクトに
tracebackは、に関連する多くのデータがありますastroid。私の研究にはいくらかの進歩がありました!図書館astroidファイルを解析するため、メモリに大量のデータを保持できるプログラムと非常によく似ています。
私はコードを調べて、ファイルに次の行を見つけました
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
「これだ」と思った。「まさにこれが私が探しているものだ!」これは、オブジェクトのチェーンが最も長くなる一連の例外です
traceback。そして、ここでは、とりわけ、ファイルが解析されるため、再帰的なメカニズムもここで発生する可能性があります。そして、構造に似た何かがraise thing from other_thingそれをすべて結びつけます。
私は削除
from exしました...何も起こりませんでした。プログラムによって消費されるメモリの量は実質的に同じままであり、オブジェクトtracebackもどこにも行きません。
例外がローカルバインディングをオブジェクトに格納することを知っていた
tracebackので、にアクセスできますex。その結果、それらのメモリをクリアすることはできません。
基本的にブロックを取り除くために、コードの大規模なリファクタリングを行いました
except、または少なくともへのリンクからex。しかし、繰り返しになりますが、何も得られませんでした。
私は破裂し
tracebackていましたが、これらのオブジェクトへの参照がないことを考慮しても、オブジェクトのガベージコレクターを「刺激」することはできませんでした。その理由は、どこかに他のリンクがあったからだと思いました。
実際、私は当時、誤った道を歩みました。これがメモリリークの原因であるかどうかはわかりませんでした。ある時点で、自分の「例外チェーンの理論」を裏付ける証拠がないことに気づき始めたからです。私はたくさんの推測と何百万ものオブジェクトしか持っていませんでした
traceback。
それから私はいくつかの追加の手がかりを探してこれらのオブジェクトをランダムに見始めました。リンクのチェーンを手動で「登る」ことを試みましたが、結局は空しか見つかりませんでした。
それからそれは私に夜明けしました:これらのオブジェクト
tracebackはすべて「上下に」配置されていますが、他のすべての「上」にあるオブジェクトが存在する必要があります。他のそのようなオブジェクトのいずれによっても参照されていないもの。
リンクはプロパティを介して作成され
tb_next、そのようなリンクのシーケンスは単純なチェーンでした。そこでtraceback、それぞれのチェーンの最後にあるオブジェクトを見てみることにしました。
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
1つのライナーで50万個のオブジェクトを突き抜けて、必要なものを見つけることには、魔法のようなものがあります。
一般的に、私は探していたものを見つけました。Pythonがこれらすべてのオブジェクトをメモリに保持しなければならなかった理由を見つけました。

問題の原因を見つける
それはすべてファイルキャッシュに関するものでした!
重要なのは、ライブラリが
astroidモジュールのロード結果をキャッシュすることです。コードにすでに使用されているモジュールが必要な場合、ライブラリは、すでに使用されているこのモジュールをロードした結果をコードに提供するだけです。これは、スローされた例外を保存することによってエラーの再現にもつながります。
この時点で、私は次のように大胆な決定を下しました。「エラーを含まないものをキャッシュすることは理にかなっています。しかし、私の意見では
traceback、コードによって生成されたオブジェクトを保存しても意味がありません。」
私は例外を取り除き、自分のクラスを保持し、
Error必要に応じて例外を再構築することにしました。詳細はこちらにありますPRですが、特に面白くはありませんでした。
その結果、コードベースで作業するときのメモリ消費量を500MBから100MBに減らすことができました。
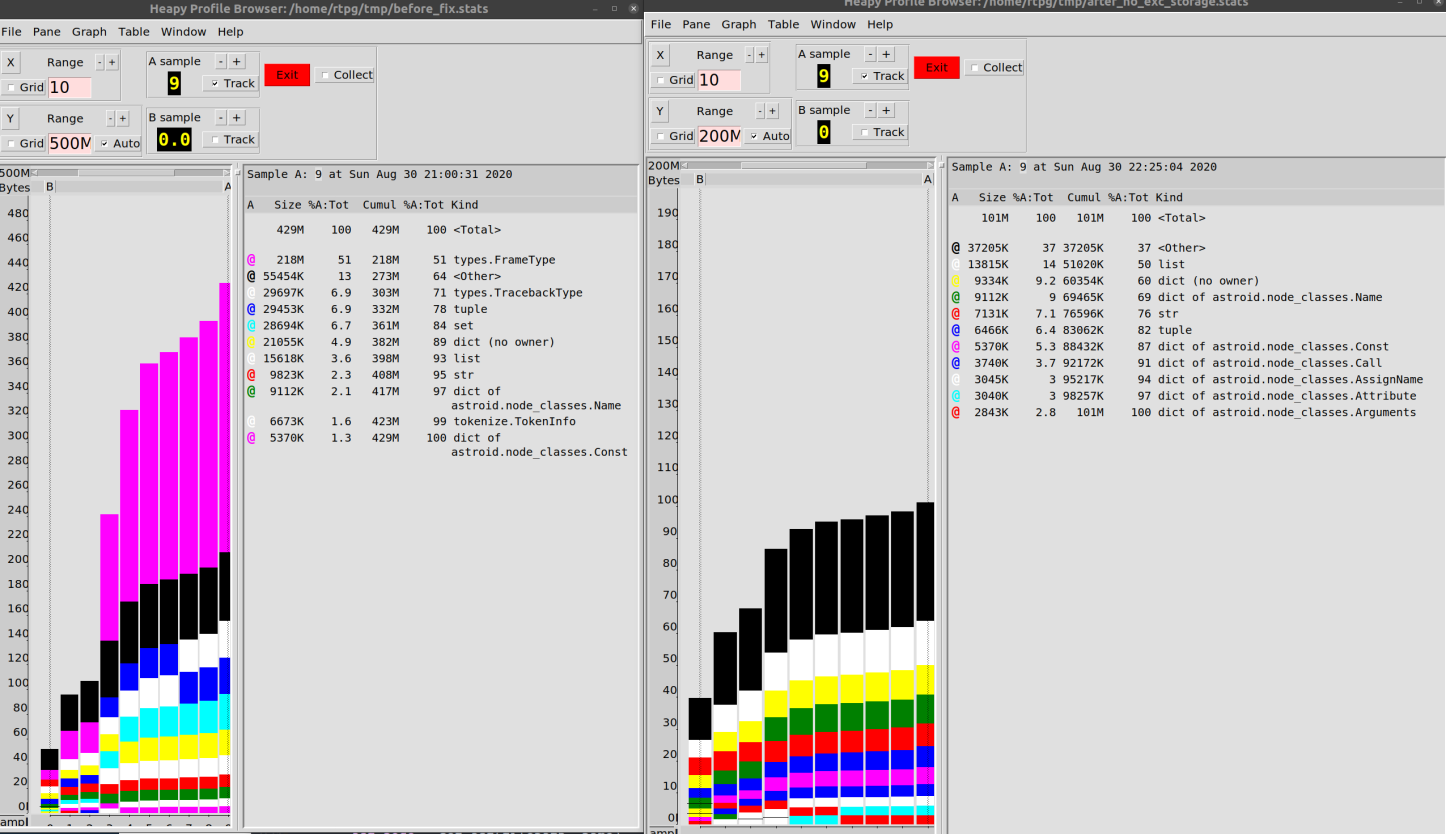
80%の改善はそれほど悪くはない
と思いますが、PRと言えば、プロジェクトに含まれるかどうかはわかりません。それ自体がもたらす変化は、パフォーマンスだけに関係しているのではありません。それが機能する方法は、状況によっては、スタックトレースデータの値を減らすことができると思います。これは、このソリューションがすべてのテストに合格したとしても、すべての詳細を考慮すると、かなり大まかな変更です。
その結果、私は自分自身のために次の結論を出しました。
- Pythonは、優れたメモリ分析機能を提供します。コードをデバッグするときは、これらの機能をより頻繁に使用する必要があります。
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
これを書いている間、私は私が特定の結論に達することを可能にしたものの多くをすでに忘れていたことに気づきました。そのため、コードスニペットのいくつかをもう一度チェックすることになりました。次に、別のコードベースで測定を実行したところ、メモリの奇数が1つのプロジェクトにのみ固有であることがわかりました。私はこの厄介な問題を探して修正するのに多くの時間を費やしましたが、これは私たちが使用するツールの動作の特徴にすぎない可能性が高く、これらのツールを使用する少数の人にしか現れません。
このような測定を行った後でも、パフォーマンスについて明確なことを言うことは非常に困難です。
私が説明した実験から得られた経験を他のプロジェクトに移すことを試みます。オープンソースのPythonプロジェクトには、修正がかなり簡単なこのようなパフォーマンスの問題がたくさんあると思います。事実、Python開発者コミュニティは通常この問題にほとんど注意を払っていません(これは、Cで記述されたPythonの拡張機能であるプロジェクトについて話さない場合です)。
Pythonコードのパフォーマンスを最適化する必要があったことはありますか?

