この記事はいくつかの理由で登場しました。
まず、圧倒的多数の本、インターネットリソース、およびデータサイエンスに関するレッスンでは、さまざまな種類のデータ正規化のニュアンス、欠陥、およびそれらの理由がまったく考慮されていないか、本質を開示せずに通過するだけで言及されています。
第二に、たとえば、多数の機能を備えたセットの標準化の「ブラインド」使用があります。「すべての人が同じになるように」です。特に初心者向け(彼自身も同じ)。一見、それは大丈夫です。しかし、詳しく調べてみると、いくつかの兆候が無意識のうちに特権的な位置に置かれ、本来よりもはるかに強く結果に影響を及ぼし始めたことが判明する可能性があります。
そして第三に、私は常に問題領域を考慮に入れた普遍的な方法を手に入れたいと思っていました。
繰り返しは学習の母です
正規化とは、データを特定の無次元単位に変換することです。[0..1]や[-1..1]など、特定の範囲内の場合もあります。場合によっては、たとえば標準偏差1など、特定のプロパティがあります。
正規化の主な目標は、さまざまな単位と値の範囲のさまざまなデータを1つの形式にまとめて、それらを相互に比較したり、オブジェクトの類似性を計算したりできるようにすることです。実際には、これは、たとえば、クラスタリングや一部のマシン学習アルゴリズムで必要です。
分析的に、正規化は次の式に還元されます
どこ -現在の価値、
-オフセット値の値、
-「1」に変換される間隔のサイズ
実際、それはすべて、元の値のセットが最初にシフトされ、次にスケーリングされるという事実に要約されます。
例:
ミニマックス(MinMax)。目標は、元のセットを範囲[0..1]に変換することです。彼のために:
= 、初期データの最小値。
= - 、つまり 「単位」間隔は、元の値の範囲から取得されます。
. — 0 1.
= , .
— .
, .
, , “” . .
, - . , . , , . , . , — . , , , , *
* — , , ( ), , .
, — .
1 —
— .. , , 0 “” .
? « » . .
№ 1 — , .
, “ ” , , — , . ( ). ( ) .
, , .
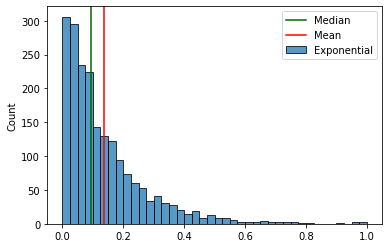
:
. “” .
, , , . .
2 —
. .
. , , [-1..1], . [-1..1], — [-1..100], , . .
. . , “”.
( ):

( ) , .
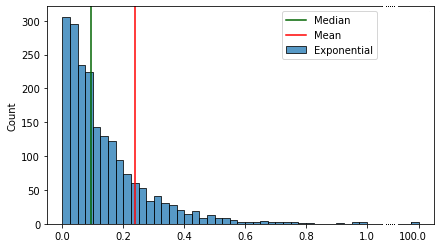
, () “”, .

— ( ). , “” .
75- 25- — . .. , “” 50% . “” / .
— “”, “” .
№ 2 — “” .
— .
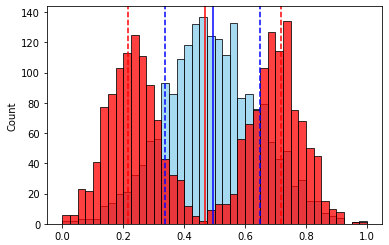
( ).

- “” . , , “”.
. .. . — 1.
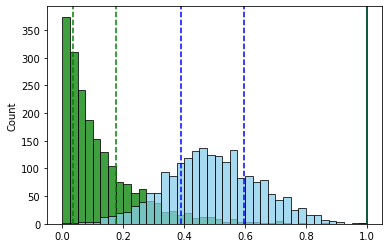
, , , № 3 — . ( ) .
, , . 2-
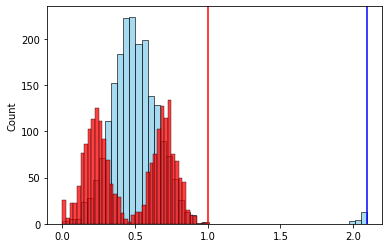
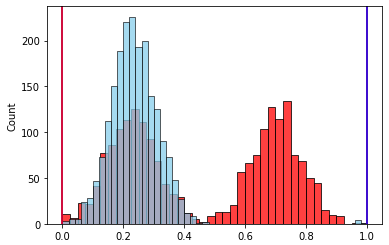
, , . .
, “-”. — .
— , . , . , , , , ? .
, . , “” , 1,5 (IQR) .*
* — ( .) 1,5 3 — .
.
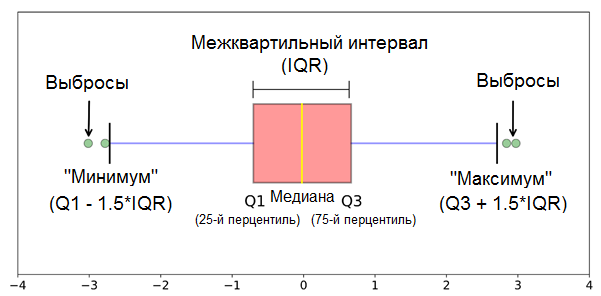
— - , .
. (, , ) “” — 7%. (3 * IQR) — . . .. .
, . “ ” (1,5 * IQR) , . , - “” .
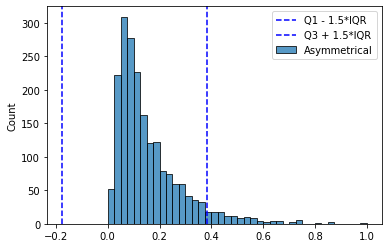
(Mia Hubert and Ellen Vandervieren) 2007 . “An Adjusted Boxplot for Skewed Distributions”.
“ ” , 1,5 * IQR.
“ ” medcouple (MC), :
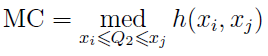
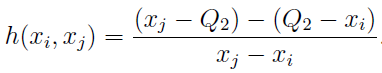
“ ” , , , 1,5 * IQR — 0,7%
:
:

:
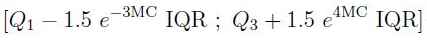
. .
, , :
- , , .
- .
- () — , , [0..1]
… — Mia Hubert Ellen Vandervieren
. .
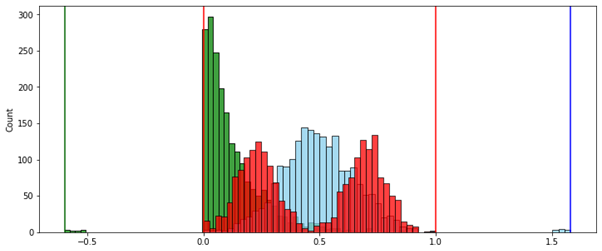
, ( ) (MinMax — ).
№ 1 — . . , “” .
:
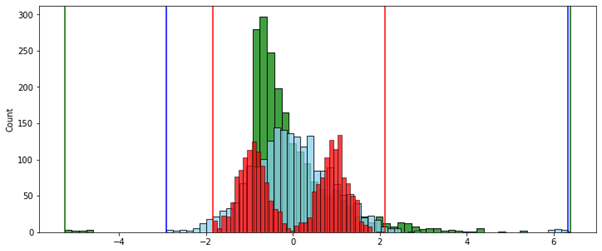
( ):

:

, — , , .
№ 2 — . [0..1]. , , .
MinMax ( ):
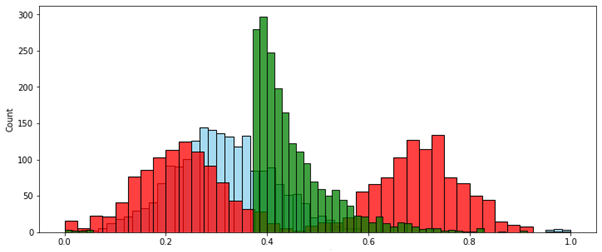
:
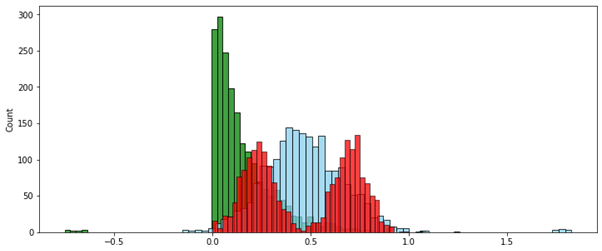
. -, , — .. 0 1.
, “” [0..1], , — , , , . .
* * *
最後に、このメソッドを手で感じる機会として、ここから私のデモクラスAdjustedScalerを試すことができます。
非常に大量のデータを処理するために最適化されておらず、pandas DataFrameでのみ動作しますが、試行、実験、またはより深刻なものの空白でさえ、非常に適しています。それを試してみてください。