
今日は、リレーショナルデータや関連データのような一見単純なトピックについて説明します。
その単純さにもかかわらず、時々人々が本当にそれらについて混乱することに気づきます-私はそれらが何であるか、そしてなぜそれらが必要であるかについての短くて非公式な説明を書くことによってこれを修正することに決めました。
リレーショナルモデルとは何か、および関連するSQLとリレーショナル代数について説明します。次に、Wikidatからの関連データの例に移り、次にRDF、SPARQL、そしてデータログと論理データ表現について少し話します。結局のところ、結論-リレーショナルモデルをいつ適用するか、そしていつコヒーレント論理的であるか。
投稿の主な目的は、何を適用するのが理にかなっているのか、その理由を説明することです。一箇所に集まった難しい概念がたくさんあるので、もちろんそれぞれに本を書くことは可能です-しかし、今日の私たちの仕事はトピックのアイデアを与えることであり、簡単な例を使用して非公式に分析します。
1つが2つ目とどのように異なるのか、リンクされたデータ(LinkedData)が必要な理由について疑問がある場合は、catの下で歓迎します。

関係データ
標準の定義から始めましょう。
リレーショナルデータベースは、それらの間に事前定義された関係を持つデータのコレクションです。このデータは、列と行で構成されるテーブルのセットとして編成されています。テーブルには、データベースで表されるオブジェクトに関する情報が格納されます。
適用時:
- 固定ドメインモデリング
- データスキーマはほとんど変更されないか、変更がすぐに重要なレコードグループに影響します
- 基本的なクエリ-レコードの主要フィールドによるカテゴリのフィルタリング、集計、レポートの生成、統計指標に基づく分析など
このような状況では、モデリングの単位はテーブルとテーブル間の関係(外部キーなど)です。実際、テーブルは固定属性を持つ述語です。私たちは常に表形式の述語の多様性を知ってい ます。
制約関係の例として外部キーを取り上げましょう。キー「p(_、X、_)→q(_、Y、_)」は、X \サブセットYの形式で制約を設定します 。Xはp関係の属性であり、 Y関係属性q。

さらに重要なことに、リレーショナルデータの世界では、すべてがテーブルになっています。また、操作はテーブルを入力として受け取り、テーブルを返します。次に例を示します。

リレーショナルデータ言語:SQLおよびリレーショナル代数
リレーショナル代数(Codd代数)は、基本的に、テーブルを返すテーブルに対する一連の操作です。つまり、モデリングの中心的な要素は、正確には固定テーブルとその変換です。
SQL言語は、関係代数の概念の宣言的な上位構造および具体的な実装です。
単純なクエリとそれに対応する代数のリレーショナル演算子の例。

これまでのところ、データベースコースで知っている古典的なことだけを取り上げてきました。
リンクされたデータと知識のグラフ
新しいプロパティがあり、これがおそらくリアルタイムで発生した場合に何が起こるかを想像してみましょう。つまり、ドメインは 固定されていませんが、柔軟で拡張可能ですか?
もちろん、このような状況では、NULLまたはデフォルト値を挿入することにより、テーブルと列をテーブルに追加できます。しかし、技術的に不便であることに加えて、モデリングの観点からも不適切なツールです。
考えられるすべての側面で人々の生活をモデル化していると想像してみてください。 2人の異なる人でさえ、かなり異なるキープロパティのセットを持っているでしょう、そしてこれは絶対に正常です!
特定のキャラクターがどのように記述されるかについての固定リストはありません。ライターとフットボール選手-これらは多くの重要な、しかしそれにもかかわらず異なる特性を持っている2人の人々です。
ライターのダグラス・アダムスから始めましょう-トップのプロパティは誰にとってもかなり典型的です-ここと以下では、LinkedDataの例としてWikidataを使用します。
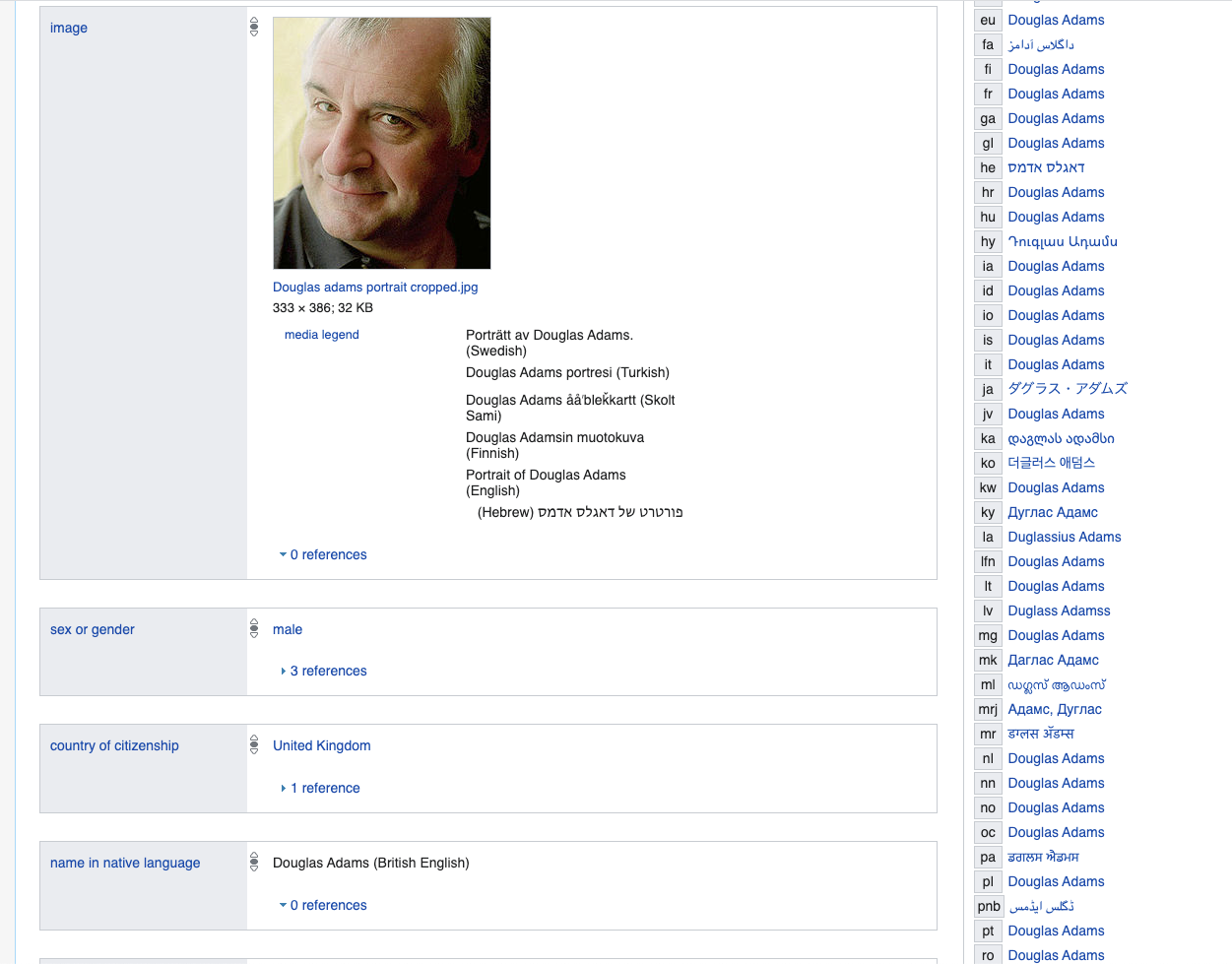
www.wikidata.org/wiki/Q42
しかし、もう少し深く掘り下げて、
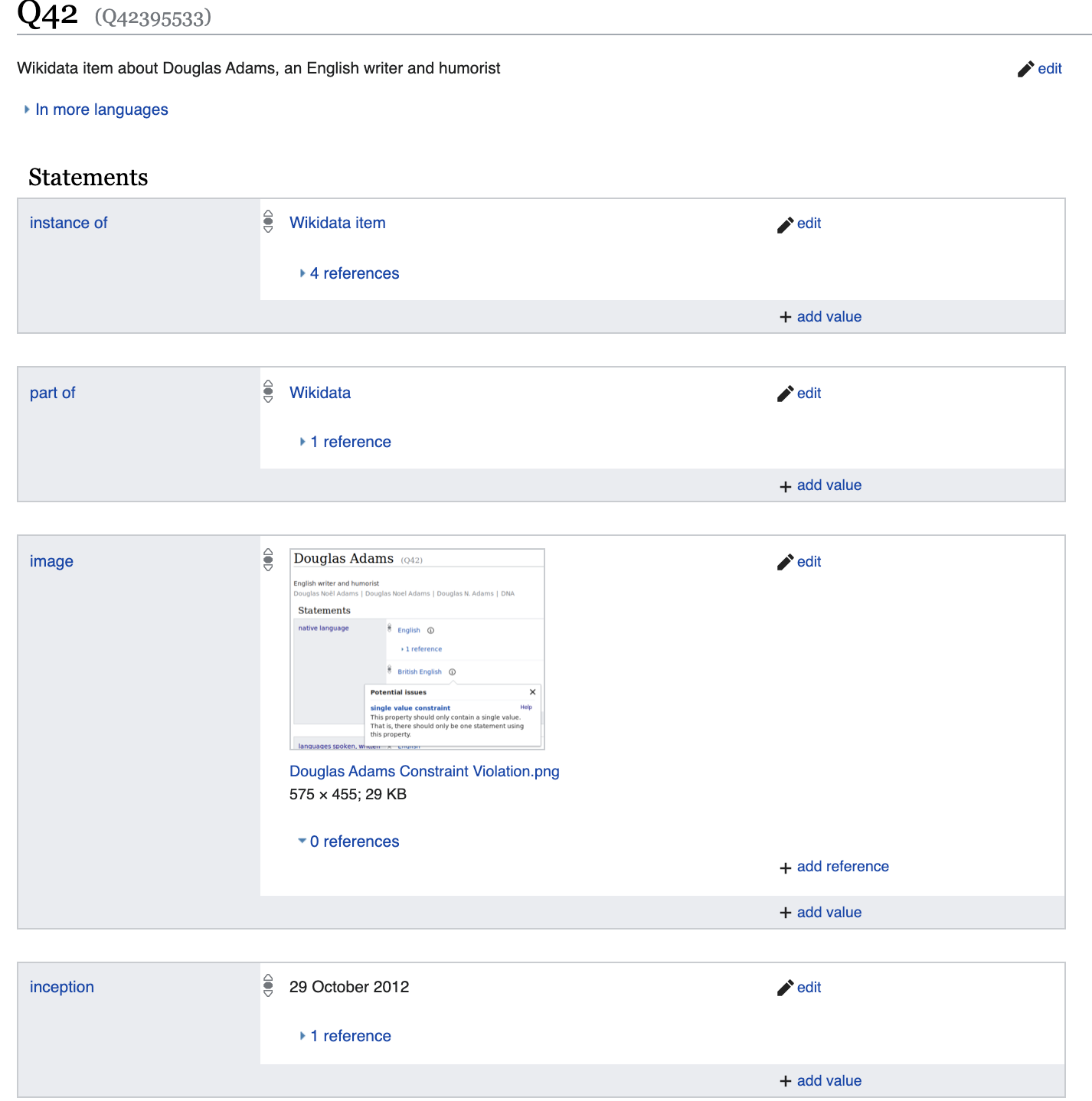
たとえば、DiegoMaradonna とは大幅に異なる一連のプロパティを見て
みましょう。ここで指定されているプロパティについてもう少し話しましょう。たとえば、性別:男性のプロパティ

は、本質的に論理的な事実を反映しています:p21(Q42、Q6581097)。
ここで、p21→これはgender_identity / 2-バイナリ述語
Q42→ダグラスアダムス
Q6581097→男性です。
したがって、すべてのデータは、is_dead(Q42)などの単一述語またはバイナリp21(Q42、Q6581097)として表示されます。
実際、これはモデリングパラダイムの別のパラダイムです。1次ロジックですが、単元およびバイナリの述語に基づいています。
そして、ここで新しいデータを追加するのは非常に簡単です。オブジェクトの述語の形で示されていないものはすべて誤りです。文献では、これはクローズドワールドの仮定として知られてい ます。
さらに、この形式では、完全に自然なメタモデリングが可能です
https://www.wikidata.org/wiki/Q42395533
そのようなデータへのいくつかの基本的なストレージと書き込みクエリがあります-人気のあるオプションを見てみましょう。
RDFとSPARQLクエリ言語
RDFは、後続のクエリ処理のために関連データを記述するための正式な言語です。つまり、マシンで読み取り可能な形式です。
実際、彼にとって重要なのはトリプレットの概念です。

これがこのモデルでのデータ記録の例です(接頭辞はこれらの述語の「説明」がどこにあるかを決定します)

この記録形式を使用すると、オブジェクトに関するデータをグラフィカルに表すことができます。たとえば、これはベルリン市に関する情報を書き込む方法です。

RDF形式の場合、彼らはSPARQLクエリ言語を作成しました。これは基本的に論理述語の制約を記述し、論理式からどの変数を抽出する必要があるかを示します。

実際に見つけたいのは、変数?Countryの値です。member_ofはmember_of(?Country、q458)に対して正しく、q458はEUIDです。
実際のコードでは、次のようになります。
合計:RDFはデータをトリプル(バイナリ述語)の形式で表すための形式であり、SPARQLはトリプルのロジックベースのクエリ言語です。
データログクエリ言語と派生物
また、RDFにクエリを書き込むために(それだけでなく、後で詳しく説明します)、Datalogを使用できます。Datalogは、Prologのサブセットを構文的に表す宣言的な(多くの場合)言語です(ほとんどの場合)。
その中で、クエリは次のように
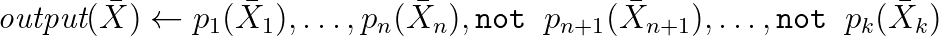
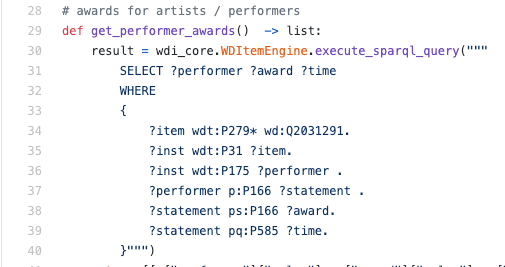
なります。 多くの場合、構文は集計やその他の実用的に重要なものの助けを借りて拡張されます。実際、これらはロジックから取得した推論ルールであり、それらの助けを借りて、新しいプロパティの推論をモデル化し、RDFにクエリを書き込むことができます。以下は、方言の1つに基づいてWikiDataを操作する実際の例です。

データログベースの論理クエリ言語のもう1つの重要な利点は、RDFがバイナリロジックのファクト(ステートメント)を記録するためのフォーマットにすぎないことです。他の論理アサーションも同様に処理できます。必ずしもバイナリである必要はありません。
結論
まず、リレーショナルデータは、スキーマが頻繁に変更されないか、変更が単一のレコードだけでなくセグメント全体に影響を与える固定ドメインのモデリングに適しています。
第二に、リレーショナル言語は、サブテーブルを抽出し、既存のものを変換して結合する必要があるタスクのモデリングに適しています-これは、作業の大部分が特定のレコードの変更や推論のレベルで行われる場合、理想的なツールではありません。
第3に、モデリングドメインがすべてを網羅する領域であり、同じクラスのレコードでさえ著しく異なる場合でも、一貫性のあるデータが適しています。
第4に、標準表現はRDFであり、最初に試すのが理にかなっています。必要なデータベースをそれにねじ込み、SPARQのような言語を使用することにより、必要なデータを抽出できます。
第5に、トリプレットを使用したモデリングが面倒で不便になる場合は、データとデータログの論理表現をクエリ言語と見なすことができます。

