記事の最後で、このトピックに関する最も興味深い資料のリストを共有します。

新しいアプローチ
強化されたマルチエージェント学習は、研究の成長している豊富な分野です。それにもかかわらず、マルチエージェントコンテキストでシングルエージェントアルゴリズムを常に使用すると、困難な立場に置かれます。特に次の理由により、学習は多くの理由で複雑になります。
- 独立したエージェント間の非定常性;
- アクションと状態の空間の指数関数的成長。
研究者たちは、これらの要因の影響を軽減する多くの方法を発見しました。これらの方法のほとんどは、「分散型実行による集中計画」の概念に該当します。
中央計画
各エージェントは、ローカルの観測に直接アクセスできます。これらの観察は非常に多様である可能性があります:環境の画像、特定のランドマークに対する位置、または他のエージェントに対する位置ですらあります。さらに、トレーニング中、すべてのエージェントは中央モジュールまたは批評家によって管理されます。
各エージェントにはローカル情報とトレーニング用のローカルポリシーしかありませんが、エージェントのシステム全体を監視し、ポリシーの更新方法を伝えるエンティティがあります。したがって、非定常性の影響は減少します。すべてのエージェントは、グローバル情報を持つモジュールを使用してトレーニングされます。
分散実行
テスト中、中央モジュールは削除されますが、ポリシーとローカルデータを持つエージェントは残ります。集約されたポリシーは調査されないため、これにより、アクションと状態のスペースの増加によって引き起こされる損害が軽減されます。代わりに、中央モジュールがローカルラーニングポリシーを管理するのに十分な情報を持っていることを望みます。これは、テストを実施するときが来たらすぐにシステム全体に最適な方法です。
Openai
OpenAI、カリフォルニア大学バークレー校、マギル大学の研究者たちは、マルチエージェントディープデターミニスティックポリシーグラディエントを使用したマルチエージェント設定への新しいアプローチを発表しました。このアプローチは、単一エージェントの対応物であるDDPGに触発され、俳優から批評家へのトレーニングを使用しており、非常に有望な結果を示しています。
建築
この記事は、読者がMADDPGの単一エージェントバージョンに精通していることを前提としています:Deep Deterministic Policy GradientsまたはDDPG。思い出をリフレッシュするには、Chris Yoonによるすばらしい記事を読むことができます。
各エージェントには、観察スペースと連続アクションスペースがあります。また、各エージェントには3つのコンポーネントがあります。
- , ;
- ;
- , - Q-.
批評家は、関数の共同Q値を時間の経過とともに学習するので、Q値の対応する近似値を俳優に送信して、学習を支援します。この相互作用については、次のセクションで詳しく見ていきます。
批評家はN人のすべてのエージェント間の共通のネットワークになる可能性があることを覚えておいてください。つまり、同じ値を評価するN個のネットワークをトレーニングする代わりに、1つのネットワークをトレーニングし、それを使用して他のすべてのエージェントのトレーニングを支援します。エージェントが同種の場合、同じことがアクターネットワークにも当てはまります。
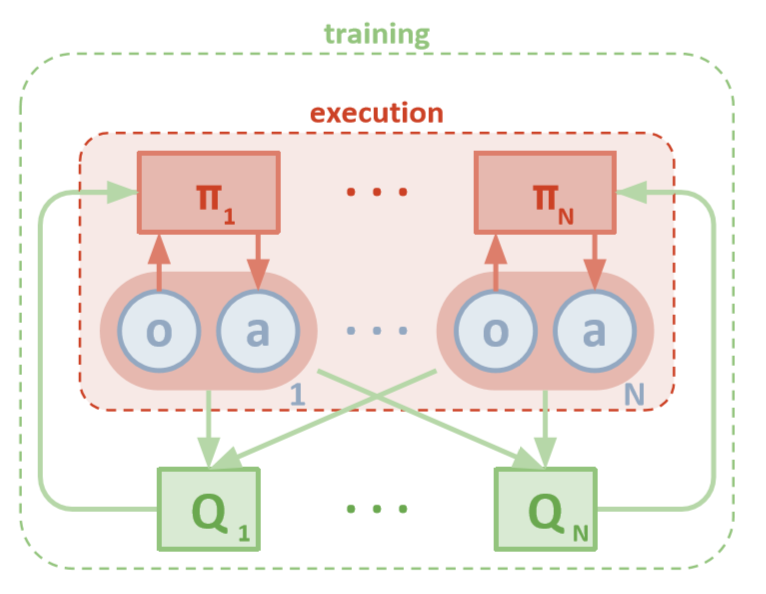
MADDPGアーキテクチャー(ロウ、2018)
トレーニング
まず、MADDPGは効果的なポリシー外学習のためにエクスペリエンスリプレイを使用します。各時間間隔で、エージェントは次の遷移
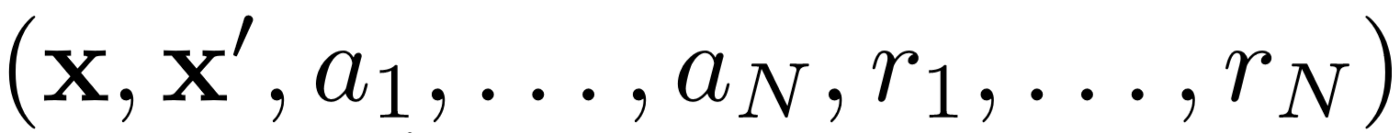
を保存します。ジョイント状態、次のジョイント状態、ジョイントアクション、およびエージェントが受け取った各報酬を保存します。次に、エクスペリエンスのリプレイからそのような遷移のセットを取得して、エージェントをトレーニングします。
批評の更新
エージェントの中心的な批評家を更新するには、先読みTDバグを使用します。
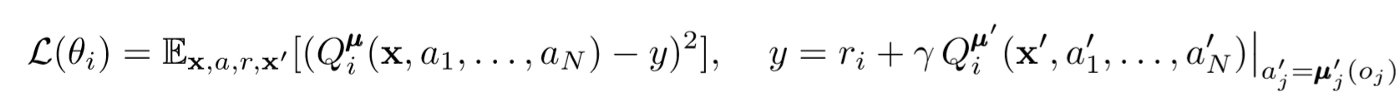
ここで、μはアクターです。これは中心的な批評家であることを忘れないでください。つまり、彼は一般的な情報を使用してパラメーターを更新します。基本的な考え方は、すべてのエージェントが実行しているアクションを知っていれば、ポリシーが変更されても環境は静止しているということです。
Q値の計算では、式の右側に注意してください。次の相乗効果を保存することはありませんが、エージェントの各ターゲットアクターを使用して、更新中の次のアクションを計算し、学習をより安定させます。ターゲットアクターのパラメーターは、エージェントのアクターのパラメーターと一致するように定期的に更新されます。
俳優の更新
単一エージェントDDPGと同様に、決定論的なポリシーグラディエントを使用して、各エージェントアクターパラメーターを更新します。
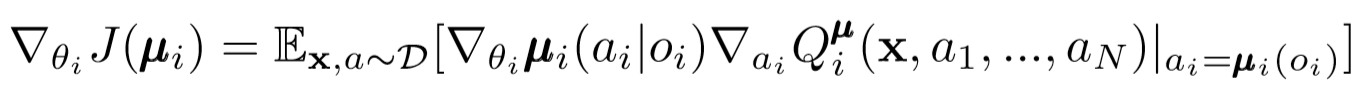
ここで、μはエージェントアクターです。
この更新の表現をもう少し詳しく見てみましょう。中心の評論家を使用して、俳優のパラメーターに関連する勾配を取得します。注意すべき最も重要なことは、俳優が局所的な観察と行動しか持っていない場合でも、トレーニング中に中央の評論家を使用して、システム全体における彼の行動の最適性に関する情報を取得することです。したがって、非定常性の影響は減少し、学習方針は州のより低い空間に留まります!
政治家と政治家集団による結論
地方分権の問題について、もう一歩踏み出すことができます。以前の更新では、各エージェントが他のエージェントのアクションを自動的に認識すると想定していました。ただし、MADDPGは、トレーニングをさらに独立させるために、他のエージェントのポリシーから結論を引き出すことを提案しています。実際、各エージェントはN-1ネットワークを追加して、他のすべてのエージェントのポリシーの有効性を評価します。確率的ネットワークを使用して、別のエージェントの観測されたアクションを推論する対数確率を最大化します。
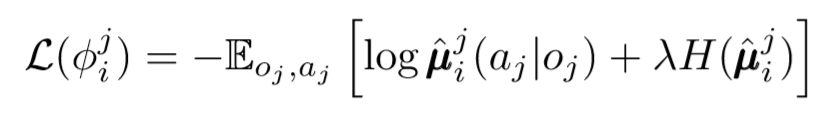
エントロピー正則化機能を使用してj番目のエージェントのポリシーを評価するi番目のエージェントの損失関数を確認します。その結果、エージェントのアクションを予測可能なアクションに置き換えると、目標のQ値がわずかに異なります。
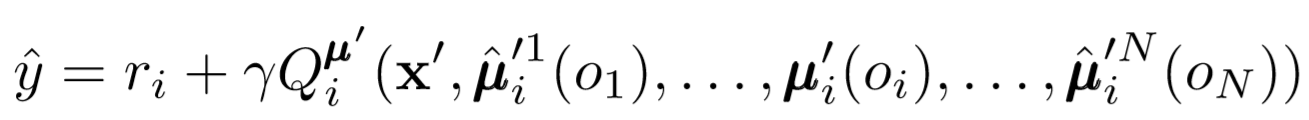
それで、あなたは何で終わったのですか?エージェントがお互いのポリシーを知っているという仮定を削除しました。代わりに、一連の観察に基づいて他のエージェントのポリシーを予測するようにエージェントをトレーニングしようとします。実際、各エージェントはデフォルトで手元にあるのではなく、環境からグローバル情報を受け取り、独立して学習します。
政治アンサンブル
上記のアプローチには1つの大きな問題があります。多くのマルチエージェント設定、特に競争の激しい設定では、エージェントは他のエージェントの動作を再トレーニングできるポリシーを作成できます。これは、政治をもろく、不安定にし、原則として最適ではなくなります。この欠点を補うために、MADDPGは各エージェントのKサブポリシーのコレクションをトレーニングします。各タイムステップで、エージェントはサブポリシーの1つをランダムに選択して、アクションを選択します。そして彼はそれをします。
政治の勾配は少し変化します。K個のサブポリシーの平均を取り、期待値の線形性を使用し、Q値関数を使用して更新を配布します。
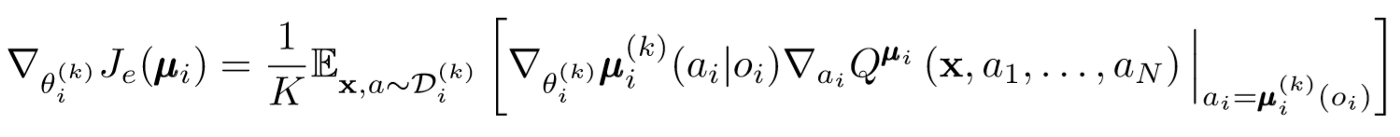
一歩下がろう
これは、アルゴリズム全体の一般的な見方です。さて、前に戻って、私たちが正確に何をしたかを理解し、それが機能する理由を直感的に理解する必要があります。基本的に、次のことを行いました。
- ローカルの観測のみを使用するエージェントの定義されたアクター。このようにして、状態とアクションの空間が指数関数的に増加するという悪影響を制御できます。
- 共有情報を使用する各エージェントの中心的な批評家を特定しました。したがって、非定常性の影響を減らすことができ、俳優がグローバルシステムに最適になるのを支援しました。
- 他のエージェントのポリシーを評価するためのポリシーからの結論の特定されたネットワーク。そのため、エージェントの相互依存を制限し、エージェントが完全な情報を持つ必要をなくすことができました。
- 他のエージェントのポリシーへの影響と再トレーニングの可能性を減らすために、ポリシーの定義された集合。
アルゴリズムの各コンポーネントは、特定の異なる目的を果たします。MADDPGアルゴリズムの強力な点は次のとおりです。そのコンポーネントは、マルチエージェントシステムが通常直面する主要なハードルを克服するように特別に設計されています。次に、アルゴリズムのパフォーマンスについて説明します。
結果
MADDPGは多くの環境でテストされています。彼の仕事の完全な概要は記事[1]にあります。ここでは、協調的コミュニケーションの問題についてのみ話します。
環境の概要
エージェントには、スピーカーとリスナーの2つがあります。各反復で、リスナーはマップ上の色付きのポイントを受け取り、そのポイントまでの距離に比例する報酬を受け取ります。しかし、ここに問題があります。リスナーは自分の位置と終点の色だけを知っています。彼はどこに移動すべきかわからない。ただし、話し手は現在の反復の正しいポイントの色を知っています。その結果、このタスクを実行するには、2つのエージェントが相互作用する必要があります。
比較
この問題を解決するために、この記事ではMADDPGと最新の単一エージェント方式を対比しています。MADDPGの使用により、大幅な改善が見られます。
政治家からの結論は、政治家が完全に訓練されていなくても、真の観察を使用して達成できるのと同じ成功を達成したことも示された。さらに、収束の大幅な減速はありませんでした。
最後に、政治家の集団が非常に有望な結果を示しました。論文[1]は、競争の激しい環境におけるアンサンブルの影響を調査し、単一ポリシーエージェントに比べてパフォーマンスが大幅に改善されていることを示しています。
結論
それで全部です。ここでは、マルチエージェント学習を強化するための新しいアプローチを検討しました。もちろん、MARLに関連するメソッドは無数にありますが、MADDPGはマルチエージェントシステムの最もグローバルな問題を解決するメソッドの強固な基盤を提供します。
出典
[1] R. Lowe、Y。Wu、A。Tamar、J。Harb、P。Abbeel、I。Mordatch、混合協調競争環境のマルチエージェント俳優批評家(2018)。
お役立ち記事一覧
- 意欲的なデータサイエンティストのための3つの落とし穴
- AdaBoostアルゴリズム
- 数学とコンピューターサイエンスの2019年はいかがでしたか
- 機械学習は未解決の数学の問題に直面しています
- ベイズの定理を理解する
- 回帰木のアンサンブルを使用して1ミリ秒で顔の輪郭を見つける
, , , . .