
私はすぐに言っておく必要があります。私はITの専門家ではありませんが、統計の分野の熱狂者です。さらに、私は長年にわたってさまざまなフォーミュラ1予測コンテストに参加しています。したがって、私のモデルが直面したタスク:「目で」作成されたものよりも悪くない予測を発行すること。そして理想的には、モデルはもちろん人間の対戦相手を倒す必要があります。
資格はレースよりも予測可能であり、モデル化が容易であるため、このモデルは資格の結果の予測にのみ焦点を当てています。しかしもちろん、将来的にはレースの結果を十分に正確に予測できるモデルを作成する予定です。
モデルを作成するために、2018年と2019年のシーズンの練習と資格のすべての結果を1つの表にまとめました.2018年はトレーニングサンプルとして、2019年はテストサンプルとして機能しました。このデータに基づいて、線形回帰を作成しました。できるだけ簡単に回帰を行うために、データは座標平面上の点のコレクションです。これらの点の全体から最も逸脱しない直線を描画しました。そして、関数、そのグラフはこの線です-これは私たちの線形回帰です。
学校のカリキュラムから知られている式から私たちの機能は、2つの変数があるという事実によってのみ区別されます。最初の変数(X1)は3番目の練習のラグであり、2番目の変数(X2)は以前の資格の平均ラグです。これらの変数は同等ではなく、私たちの目標の1つは、0から1の範囲で各変数の重みを決定することです。変数がゼロから離れるほど、従属変数の説明で重要になります。私たちの場合、従属変数はラップタイムであり、リーダー(またはより正確には、この値はすべてのパイロットで正であったため、特定の「理想的なサークル」からの遅れ)で表されます。
Moneyballブック(映画では説明されていません)のファンは、線形回帰を使用して、基本パーセンテージ(別名OBP(オンベースパーセンテージ))が他の統計よりも傷とより密接に関連していると判断したことを思い出すかもしれません。私たちの目標はほぼ同じです。資格の結果に最も密接に関連している要因を理解することです。回帰の大きな利点の1つは、数学の高度な知識を必要としないことです。データを入力するだけで、Excelまたは別のスプレッドシートエディターで既製の係数が得られます。
基本的に、線形回帰に関して2つのことを知りたいと思います。まず、選択した独立変数が機能の変化を説明する程度。次に、これらの独立変数のそれぞれがいかに重要であるか。言い換えれば、予選の結果をよりよく説明するもの:以前のトラックでのレースの結果または同じトラックでのトレーニングセッションの結果。
ここで重要な点に注意してください。最終結果は、2つの独立した回帰の結果である2つの独立したパラメーターの合計でした。最初のパラメーターは、この段階でのチームの強さ、より正確には、リーダーからのチームの最高のパイロットの遅れです。 2番目のパラメーターは、チーム内の力の分布です。
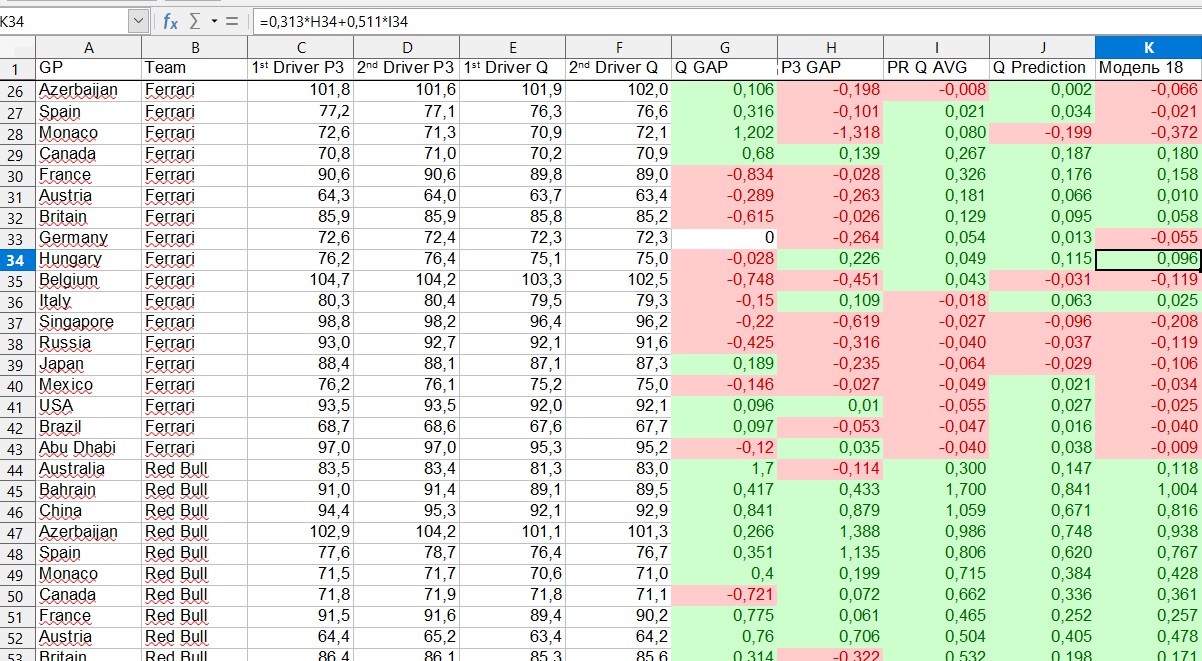
これは例によって何を意味しますか? 2019年のハンガリーグランプリを取るとしましょう。モデルは、フェラーリがリーダーより0.218秒遅れることを示しています。しかし、これは最初のパイロットの遅れであり、彼らが誰になるか-ベッテルまたはレクレア-とそれらの間のギャップは、別のパラメーターによって決まります。この例では、モデルはベッテルが先行し、レクレアが彼に0.096秒を失うことを示しました。
なぜそのような困難なのでしょうか?チームのラグとチーム内の2番目のパイロットからの最初のパイロットのラグへのこの内訳の代わりに、各パイロットを個別に検討する方が簡単ではないですか?おそらくそうなのかもしれませんが、私の個人的な観察によると、各パイロットの結果よりもチームの結果を見る方がはるかに信頼できることがわかります。 1人のパイロットがミスをしたり、コースを外れたりする可能性があります。そうしないと技術的な問題が発生します。すべての不可抗力の状況を手動で追跡しなければ、時間がかかりすぎて混乱が生じます。チームの結果に対する不可抗力の影響ははるかに少ないです。
しかし、選択した説明変数が機能の変化をどの程度説明できるかを評価したかったところに戻ります。これは決定係数を使用して行うことができます...それは、資格の結果がインターンシップと以前の資格の結果によって説明される程度を示します。
2つの回帰を作成したので、決定係数も2つあります。最初の回帰は、ステージでのチームのレベルを担当し、2番目の回帰は、同じチームのパイロット間の対立を担当します。最初のケースでは、決定係数は0.82です。つまり、適格性の結果の82%は、選択した要因によって説明され、さらに18%-考慮しなかった他のいくつかの要因によって説明されています。これはかなり良い結果です。 2番目のケースでは、決定係数は0.13でした。
これらのメトリクスは、本質的に、モデルはチームレベルをかなり適切に予測しますが、チームメイト間のギャップを決定するのに問題があることを意味します。ただし、最終的な目標については、ギャップを知る必要はなく、2つのパイロットのどちらが高くなるかを知るだけでよく、モデルは基本的にこれに対処します。62%のケースで、モデルは実際に資格が高いパイロットよりも上位にランクされました。
同時に、チームの強さを評価するとき、前回のトレーニングの結果は以前の資格の結果よりも1.5倍重要でしたが、チーム内の決闘ではそれが逆でした。この傾向は、2018年と2019年の両方のデータで明らかになりました。
最終的な式は次のようになります。
最初のパイロット:
2番目のパイロット:
X1は3番目の練習のラグであり、X2は以前の資格の平均ラグであることを思い出してください。
これらの数値はどういう意味ですか。彼らは、資格のチームのレベルが3番目の練習の結果によって60%、前の段階での資格の結果によって40%決定されることを意味します。したがって、3番目の練習の結果は、以前の資格の結果よりも1.5倍重要な要素です。
F1のファンはおそらくこの質問に対する答えを知っていますが、残りの部分については、なぜ私が3番目の練習の結果を取ったのかについてコメントする必要があります。フォーミュラ1には3つのプラクティスがあります。しかし、チームが伝統的に資格を訓練するのは彼らの後者です。ただし、3回目の練習が雨などの不可抗力により失敗した場合は、2回目の練習の結果を取った。私が覚えている限りでは、2019年にはそのようなケースは1つだけでした-日本のグランプリでは、台風のためにステージが短い形式で開催されました。
また、誰かがモデルが以前の資格の平均遅れを使用していることにおそらく気づいたでしょう。しかし、シーズンの最初のステージはどうですか?前年のラグを使用しましたが、そのままにせず、常識に基づいて手動で調整しました。たとえば、2019年、フェラーリはレッドブルより平均0.3秒速かった。しかし、今年はイタリアのチームにはそのようなアドバンテージがないか、完全に遅れているようです。したがって、2020年シーズンの最初のステージ、オーストリアグランプリでは、手動でレッドブルをフェラーリに近づけました。
このようにして、各パイロットのラグを取得し、ラグによってパイロットをランク付けして、資格の最終的な予測を取得しました。最初と2番目のパイロットは純粋な慣習であることを理解することが重要です。ハンガリーグランプリでのベッテルとレクレアの例に戻ると、モデルはセバスチャンを最初のパイロットと見なしましたが、他の多くの段階で彼女はレクレアを好みました。
結果
私が言ったように、タスクは人だけでなく予測も可能にするモデルを作成することでした。私は自分の予測と「目で」作成されたチームメイトの予測を基本として取りましたが、実践と共同ディスカッションの結果を注意深く検討しました。
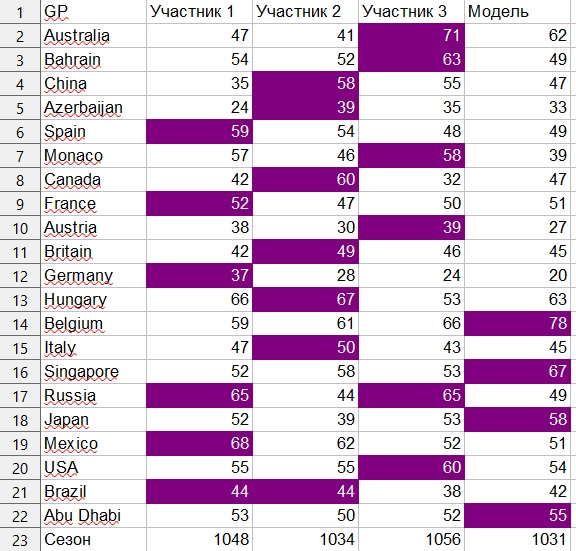
格付け体系は以下の通り。上位10名のパイロットのみが考慮されました。正確なヒットの場合、予測は9ポイント、ポジション1のミス、6ポイント、ポジション2のミス、4ポイント、ポジション3のミス、2ポイント、ポジション4のミス、1ポイントを受け取りました。つまり、予報でパイロットが3位になり、その結果彼がポールポジションを獲得した場合、予報は4ポイントを受け取りました。
このシステムでは、21グランプリの最大ポイント数は1890です。
人間の参加者は、それぞれ1056、1048、1034ポイントを獲得しました。
モデルは1031ポイントを獲得しましたが、係数を軽く操作すると、1045ポイントと1053ポイントも受け取りました。
個人的には、これが回帰を構築する最初の経験であり、それが非常に許容できる結果に導いたので、結果に満足しています。もちろん、私はそれらを改善したいと思います。これは、モデルを構築することの助けを借りて、これほど単純でも、データを「目で」評価するよりも優れた結果を達成できると確信しているからです。このモデルの枠組みの中で、たとえば、一部のチームは実際には弱いが、資格を「撃ち落とす」という要因を考慮に入れることができます。たとえば、メルセデスはトレーニング中に最高のチームではなかったが、資格でははるかに優れていたという観察があります。ただし、これらの人間の観察はモデルに反映されませんでした。したがって、7月に始まる2020年のシーズン(予期しないことが何も起こらない場合)で、このモデルをライブ予報士との競争でテストし、さらに、どのようにそれをより良くすることができます。
さらに、F1ファンコミュニティと共感し、アイデアを交換することで、予選とレースの結果を構成するものをよりよく理解できると信じています。これが、最終的に予測を立てる人の目標です。