
この記事では、2020年5月12日にSlackがクラッシュする原因となった問題の技術的な詳細について説明します。そのインシデントへの対応プロセスの詳細については、Ryan Katkov の年表「Both Hands on the Remote」を参照してください。
2020年5月12日、Slackは久しぶりに大きなクラッシュを経験しました。すぐにインシデントの概要を公開しましたが、これはかなり興味深い話なので、技術的な詳細についてさらに詳しく説明したいと思います。
ユーザーはダウンタイムが午後4時45分に気付いたが、実際には午前8時30分頃に話が始まった。データベース信頼性エンジニアリングチームは、インフラストラクチャの一部の負荷が大幅に増加したという警告を受けました。同時に、トラフィックチームは、一部のAPIリクエストを作成していないという警告を受けました。
データベースの負荷の増加は、新しい構成の展開が原因であり、これにより、長年にわたるパフォーマンスのバグが発生しました。変更はすぐに発見され、ロールバックされました。これは、段階的な展開を行う関数のフラグでした。そのため、問題はすばやく解決されました。このインシデントは顧客にほとんど影響を与えませんでしたが、それは3分しか続かず、ほとんどのユーザーはこの短い朝の不具合の間にメッセージを正常に送信できました。
インシデントの結果の1つは、メインのWebアプリケーションレイヤーの大幅な拡張でした。 CEOのStuart Butterfieldが、Slackの使用に対する隔離と自己分離の影響について書いています。パンデミックの結果、今年2月に比べて、Webアプリケーションレベルで起動するインスタンスが大幅に増加しました。ここで発生したように、ワーカーが読み込まれるとすぐにスケーリングしますが、ワーカーは一部のデータベースクエリが完了するまではるかに長く待機したため、負荷が高くなりました。インシデント中、インスタンスの数を75%増加させた結果、今日までに実行したWebアプリケーションホストの数が最も多くなりました。
次の8時間は、異常に多数のHTTP 503エラーがポップアップ表示されるまで、すべてが正常に機能しているように見えました。新しいインシデント対応チャネルを立ち上げ、当直のWebアプリケーションエンジニアは、初期の緩和策として手動でWebアプリケーションフリートを増やしました。奇妙なことに、それはまったく役に立ちませんでした。すぐに気づいたのは、一部のWebアプリケーションインスタンスに高負荷がかかっていたが、残りにはそうではなかった。 Webアプリケーションのパフォーマンスと負荷分散の両方を調査する多くの研究が始まっています。数分後、問題を特定しました。
レイヤー4ロードバランサーの背後には、リクエストをWebアプリケーション層に分散する一連のHAProxyインスタンスがあります。サービス検出にはConsulを使用し、HAProxyがリクエストをルーティングする正常なWebアプリケーションバックエンドのリストをレンダリングするためにconsul-templateを使用します。
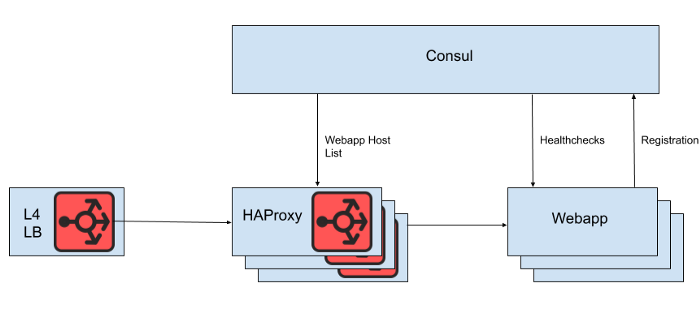
図。 1. Slackロードバランシングアーキテクチャの概要
ただし、この場合、リストを更新するにはHAProxyを再起動する必要があるため、WebアプリケーションホストのリストをHAProxy構成ファイルから直接レンダリングすることはありません。 HAProxyの再起動プロセスでは、現在のリクエストの処理が完了するまで古いプロセスを維持しながら、完全に新しいプロセスを作成します。非常に頻繁に再起動すると、HAProxyプロセスが多すぎてパフォーマンスが低下する可能性があります。この制限は、Webアプリケーション層を自動的にスケーリングするという目標と矛盾します。これは、新しいインスタンスをできるだけ早く本番環境に導入することです。したがって、 HAProxyランタイムAPIを使用していますWeb層サーバーが出入りするたびに再起動せずにHAProxyサーバーの状態を管理するため。 HAProxyがConsul DNSインターフェースと統合できることは注目に値しますが、これによりDNS TTLによるラグが追加され、Consulタグの使用が制限され、非常に大きなDNS応答を管理すると、多くの場合、痛みを伴うエッジ状況とエラーが発生します。

図。 2.単一のSlack HAProxyサーバーで一連のWebアプリケーションバックエンドを管理する方法
HAProxy状態では、 HAProxyサーバーのテンプレートを定義します。実際、これらはWebアプリケーションバックエンドが占有できる「スロット」です。新しいWebアプリケーションのインスタンスがロールアウトされるか、古いWebアプリケーションが失敗し始めると、Consulサービスカタログが更新されます。 Consul-templateは新しいバージョンのホストリストを出力し、Slackで開発された別のhaproxy-server-state-managementプログラムがこのホストリストを読み取り、HAProxyランタイムAPIを使用してHAProxy状態を更新します。
Mの並行HAProxyインスタンスプールとWebアプリケーションプールをそれぞれ別々のAWSアベイラビリティーゾーンで実行します。 HAProxyは、各AZのWebアプリケーションバックエンド用にN個の「スロット」で構成され、すべてのAZに送信できる合計N * M個のバックエンドを提供します。数か月前、その数は十分以上でした。Webアプリケーション層のその多くのインスタンスに近いものでさえ、何も起動したことがありません。ただし、午前中のデータベースインシデントの後、N * Mより少し多いWebアプリケーションインスタンスを起動しました。 HAProxyスロットを椅子の巨大なゲームと考えると、これらのwebappインスタンスのいくつかはスペースなしで残されます。これは問題ではありませんでした-十分なサービス能力があります。
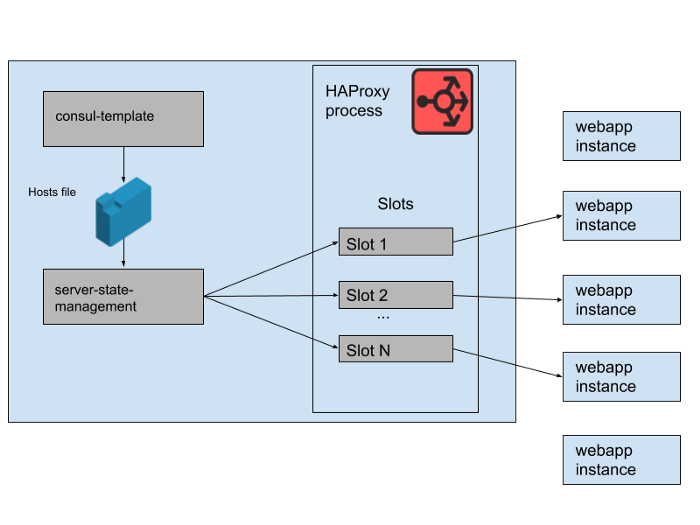
図。 3. HAProxyプロセスの「スロット」で、一部の冗長なWebアプリケーションインスタンスがトラフィックを受信していない
ただし、日中に問題が発生した。 consul-templateによって生成されたホストリストをHAProxyサーバーの状態と同期するプログラムにバグがありました。プログラムは常に、新しいwebappインスタンス用のスロットを見つけようとしましたが、動作しなくなった古いwebappインスタンスによって占有されていたスロットを解放しました。このプログラムは、空のスロットを見つけることができなかったため、エラーをスローして早期に終了し始めました。つまり、実行中のHAProxyインスタンスが状態を更新していませんでした。日が進むにつれ、webapp自動スケーリンググループが拡大および縮小し、HAProxy状態のバックエンドのリストはますます時代遅れになりました。
午後4時45分、ほとんどのHAProxyインスタンスは、午前中に利用可能な一連のバックエンドにのみリクエストを送信でき、この古いwebappバックエンドのセットは少数派になりました。私たちは定期的に新しいHAProxyインスタンスを提供しているため、正しい構成の新しいインスタンスがいくつかありましたが、それらのほとんどは8時間以上前のものであり、そのため完全で古いバックエンド状態のままになっています。最終的に、サービスがクラッシュしました。これは、トラフィックの減少に伴ってWebアプリケーション層のスケーリングを開始するのが米国の営業日の終わりに発生しました。オートスケールは最初に古いwebappインスタンスをシャットダウンします。これは、HAProxyのサーバー状態で要求に応えるのに十分な量が残っていなかったことを意味します。
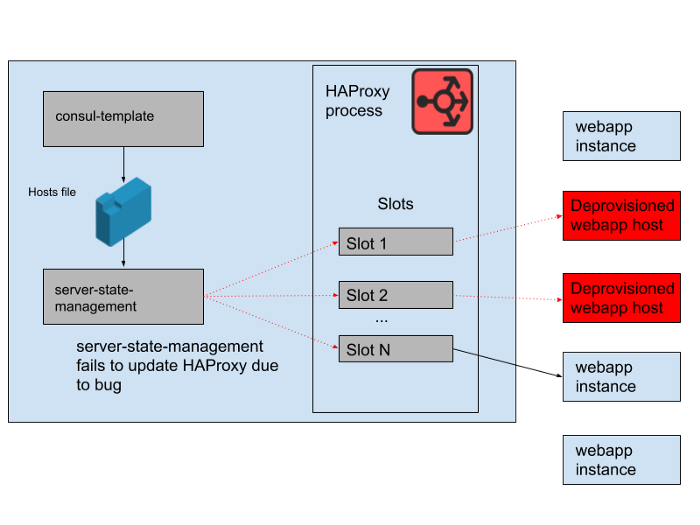
図。 4.時間の経過とともにHAProxyの状態が変化し、スロットが主にリモートホストを参照するように
なり、障害の原因が判明したら、HAProxyフリートをスムーズに再起動することですぐに修正されました。その後、私たちはすぐに質問をしました:なぜ監視はこの問題を捉えなかったのですか?この特定の状況に対するアラートシステムがありますが、残念ながら意図したとおりに機能しませんでした。システムが長期間「正常に動作した」ため、変更を必要としなかったことが原因の1つとして、監視の失敗に気づかなかった。このアプリケーションの一部であるより広範なHAProxyデプロイメントも比較的静的です。変化の速度が遅い場合、監視および警告インフラストラクチャとやり取りするエンジニアは少なくなります。
すべてのロードバランシングを徐々にEnvoyに移行しているため(最近、WebSocketトラフィックをそれに移動しました)、このHAProxyスタックの再加工はあまり行いませんでした。 HAProxyは何年もの間信頼性の高いサービスを提供してきましたが、このインシデントのように運用上の問題があります。 HAProxyサーバーの状態を管理するための複雑なパイプラインを、Envoyとエンドポイント検出用のxDSコントロールプレーンの独自の統合に置き換えます。 HAProxyの最新バージョン(バージョン2.0以降)も、これらの運用上の問題の多くを解決します。それでも、しばらくの間、内部サービスメッシュでEnvoyを信頼してきました。そのため、負荷分散をそれに転送するように努めています。 Envoy + xDSの大規模な最初のテストは有望に見え、この移行により、将来的にパフォーマンスと可用性の両方が向上するはずです。新しい負荷分散とサービス検出アーキテクチャは、この障害の原因となった問題の影響を受けません。
Slackをアクセス可能で信頼性の高い状態に保つよう努めていますが、この場合は失敗しました。Slackはユーザーにとって不可欠なツールです。そのため、お客様が気づいたかどうかに関わらず、すべてのインシデントから学ぶよう努めています。この不具合によりご迷惑をおかけしましたことをお詫び申し上げます。私たちは、この知識を使用してシステムとプロセスを改善することを約束します。