こんにちは!深刻な障害に直面したことがないマイクロシステムプログラマーを見つけることは困難です。多くの場合、それはまったく処理されませんが、製造元の起動ファイルで提供されるハンドラーの無限のループにぶら下がっているだけです。同時に、プログラマーは失敗の理由を直感的に見つけようとします。私の意見では、これは問題を解決するための最良の方法ではありません。
この記事では、Cortex M3 / M4コアを備えた一般的なマイクロシステムの重大な障害を分析するための手法について説明します。おそらく、「テクニック」という言葉は大きすぎます。むしろ、重大な障害の発生を分析する方法の例を取り上げ、同様の状況で何ができるかを示します。多くの意欲的なプログラマーがこれらのツールを持っているので、私はIARソフトウェアとSTM32F4DISCOVERYデバッグボードを使用します。ただし、これはまったく関係ありません。この例は、ファミリの任意のプロセッサおよび任意の開発環境に適合させることができます。

HardFaultに陥る
HatdFaultを分析する前に、HatdFaultに入る必要があります。これを行うには多くの方法があります。無条件ジャンプ命令のアドレスを偶数に設定して、プロセッサをサム状態からARM状態に切り替えようとするとすぐに思い浮かびました。
小さな逸脱。ご存知のように、Cortex M3 / M4ファミリーのマイクロコンピューターは、Thumb-2アセンブリ命令セットを使用し、常にThumbモードで動作します。 ARMモードはサポートされていません。最下位ビットをクリアした状態で無条件ジャンプアドレス(BX reg)の値を設定しようとすると、プロセッサが状態をARMに切り替えようとするため、UsageFault例外が発生します。これについて詳しくは、[1]を参照してください(2.8節「指示セット」、4.3.4アセンブラー言語:呼び出しおよび無条件分岐)。
まず、C / C ++で偶数アドレスへの無条件ジャンプをシミュレートすることを提案します。これを行うには、func_hard_fault関数を作成し、ポインターアドレスを1つ減らした後、ポインターで呼び出すようにします。これは次のように実行できます。
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
私が何をしたかをデバッガーで見てみましょう。

赤で、偶数ジャンプアドレスを含むRONR1のアドレスで現在のジャンプ命令を強調表示しました。結果:

この操作は、アセンブラーインサートを使用してさらに簡単に実行できます。
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
Hooray、HardFaultに入り、ミッションが完了しました。
HardFault分析
HardFaultにはどこで行きましたか?
私の意見では、最も重要なことは、HardFaultにどこから到達したかを見つけることです。これは難しいことではありません。まず、HardFault状況用の独自のハンドラーを作成しましょう。
extern "C"
{
void HardFault_Handler(void)
{
}
}それでは、どうやってここにたどり着いたのかを理解する方法について話しましょう。 Cortex M3 / M4プロセッサコアには、コンテキスト保存[1](9.1.1スタッキング節)などのすばらしい機能があります。簡単に言うと、例外が発生すると、R0〜R3、R12、LR、PC、PSRレジスタの内容がスタックに保存されます。

ここで私たちにとって最も重要なレジスターは、現在実行中の命令に関する情報を含むPCレジスターです。レジスタ値は例外時にスタックにプッシュされたため、最後に実行された命令のアドレスが含まれます。残りのレジスターは分析にとってそれほど重要ではありませんが、それらから何か有用なものを奪うことができます。 LRは最後の遷移のリターンアドレスであり、R0-R3、R12は移動する方向を示すことができる値であり、PSRはプログラムステータスの単なる一般的なレジスタです。
ハンドラーのレジスターの値を見つけることをお勧めします。これを行うために、次のコードを作成しました(製造元のファイルの1つに同様のコードがありました)。
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
その結果、保存されたすべてのレジスタの値
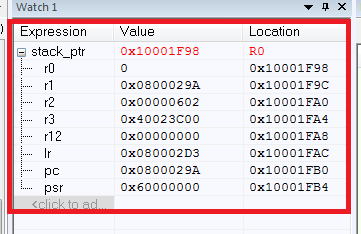
が得られます:ここで何が起こったのですか?まず、スタックポインタstack_ptrを取得しました。ここでは、すべてが明確です。アセンブラの挿入で問題が発生します(Cortexのアセンブラの説明を理解する必要がある場合は、[2]をお勧めします)。
MRS stack_ptr、MSPを介してスタックを保存しなかったのはなぜですか?実際のところ、Cortex M3 / M4コアには2つのスタックポインター[1](アイテム3.1.3スタックポインターR13)があります。メインMSPスタックポインターとPSPプロセススタックポインターです。これらは、さまざまなプロセッサモードで使用されます。これが何のために行われ、どのように機能するのかについては詳しく説明しませんが、少し説明します。
プロセッサの動作モード(このMSPまたはPSPで使用)を確認するには、通信レジスタの3番目のビットを確認する必要があります。このビットは、例外から戻るために使用されるスタックポインタを決定します。このビットが設定されている場合はMSP、そうでない場合はPSPです。一般に、C / C ++で記述されたほとんどのアプリケーションはMSPのみを使用し、このチェックは省略できます。
それで、収益は何ですか?保存されたレジスタのリストがあれば、PCレジスタからHardFaultのどこからプログラムが落ちたかを簡単に判断できます。PCは、アドレス0x0800029Aを指します。これは、「破壊」命令のアドレスです。また、他のレジスタの値の重要性を忘れないでください。
HardFaultの原因
実際、HardFaultの原因を突き止めることもできます。 2つのレジスタがこれに役立ちます。ハード障害ステータスレジスタ(HFSR)および構成可能な障害ステータスレジスタ(CFSR; UFSR + BFSR + MMFSR)。 CFSRレジスタは、使用障害ステータスレジスタ(UFSR)、バス障害ステータスレジスタ(BFSR)、メモリ管理障害アドレスレジスタ(MMFSR)の3つのレジスタで構成されています。それらについては、たとえば[1]と[3]で読むことができます。
私の場合、これらのレジスタが何を生成するかを確認することを提案します。

最初に、HFSRFORCEDビットが設定されます。これは、処理できない障害が発生したことを意味します。さらに診断するには、残りの障害ステータスレジスタを調べる必要があります。
次に、CFSRINVSTATEビットが設定されます。これは、プロセッサがEPSRを不正に使用する命令を実行しようとしたためにUsageFaultが発生したことを意味します。
EPSRとは何ですか? EPSR-実行プログラムステータスレジスタ。これは内部PSRレジスターです-特別なプログラムステータスレジスター(私たちが思い出すように、これはスタックに保存されます)。このレジスタの24番目のビットは、プロセッサ(ThumbまたはARM)の現在の状態を示します。これにより、失敗の理由を特定できます。それを数えてみましょう:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
実行の結果、値EPSR = 0が得られます。

レジスタにARMのステータスが表示され、失敗の原因が見つかりましたか?あんまり。実際、[3](p。23)によると、特別なMSRコマンドを使用してこのレジスタを読み取ると、常にゼロが返されます。このレジスタはすでに読み取り専用であるため、なぜこのように機能するのかは私にはよくわかりませんが、ここでは完全に読み取ることはできません(xPSRを介して使用できるのは一部のビットのみです)。おそらく、これらはいくつかのアーキテクチャ上の制限です。
その結果、残念ながら、このすべての情報は、通常のMKプログラマーには実質的に何も提供しません。そのため、これらすべてのレジスタは、保存されたコンテキストの分析への追加としてのみ考慮されます。
ただし、たとえば、障害の原因がゼロによる除算である場合(この障害は、CCRレジスタのDIV_0_TRPビットを設定することで許可されます)、DIVBYZEROビットがCFSRレジスタに設定されます。これにより、この障害の理由がわかります。
次は何ですか?
失敗の原因を分析した後、何ができるでしょうか?次の手順は適切なオプションのようです。
- 分析されたすべてのレジスタの値をデバッグコンソール(printf)に出力します。これは、JTAGデバッガーがある場合にのみ実行できます。
- 障害情報を内部または外部(利用可能な場合)のフラッシュに保存します。PCレジスタの値をデバイス画面に表示することもできます(利用可能な場合)。
- プロセッサNVIC_SystemReset()をリロードします。

ソース
- ジョセフ・ユウ。ARMCortex-M3の最も信頼のおけるガイド。
- Cortex-M3デバイス汎用ユーザーガイド。
- STM32 Cortex-M4MCUおよびMPUプログラミングマニュアル。