
私は誰
私の名前はドミトリー・イワノフです。私はサンクトペテルブルクHSEの経済学の2年生です。私はJetBrainsResearchの研究グループ「AgentSystemsand Reinforcement Learning」と、高等経済学部のゲーム理論と意思決定の国際研究所で働いています。PU学習に加えて、機械学習と経済学の交差点での強化学習と研究に興味があります。
前文
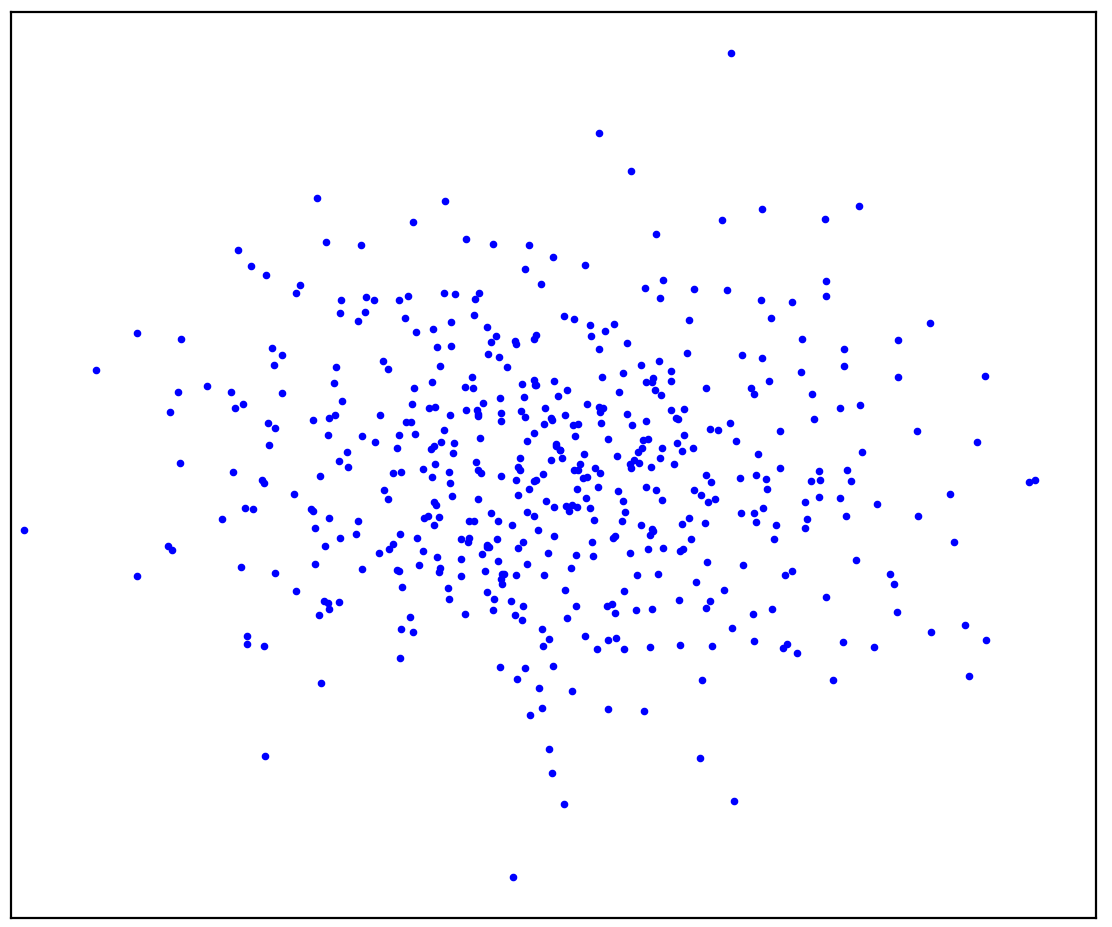
図:1a。ポジティブデータ
図1aは、ある分布によって生成された一連のポイントを示しています。これをポジティブと呼びます。正の分布に属さない他のすべての可能なポイントは、負と呼ばれます。提示されたポジティブポイントと考えられるすべてのネガティブポイントを分離する線を精神的に描くようにしてください。ちなみに、このタスクは「異常検出」と呼ばれます。
答えはここにあります

. 1.
. 1.
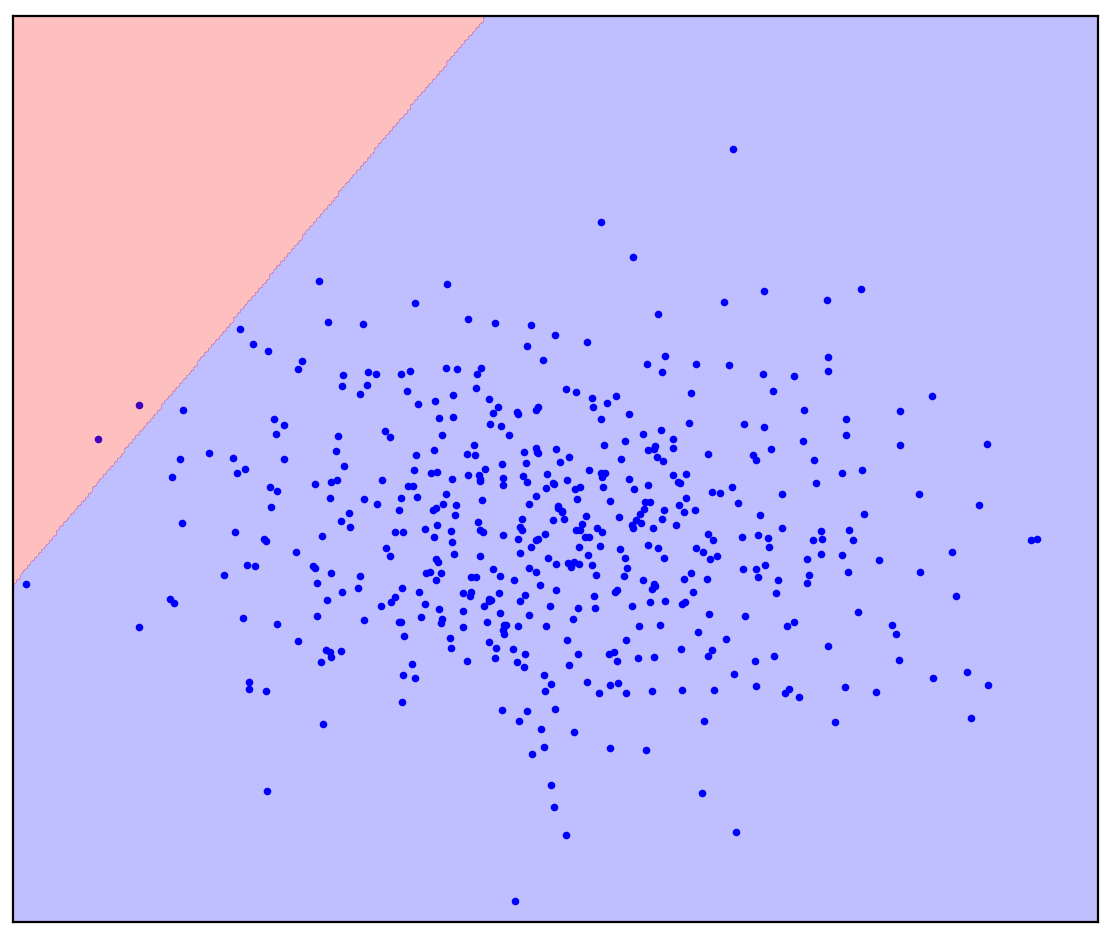
図1bのようなものを想像したかもしれません:データを楕円で囲みました。実際、これは異常検出方法がいくつ機能するかです。
ここで、問題を少し変更しましょう。直線で正の点と負の点を分離する必要があるという追加情報を用意しましょう。あなたの心にそれを描いてみてください。
答えはここにあります
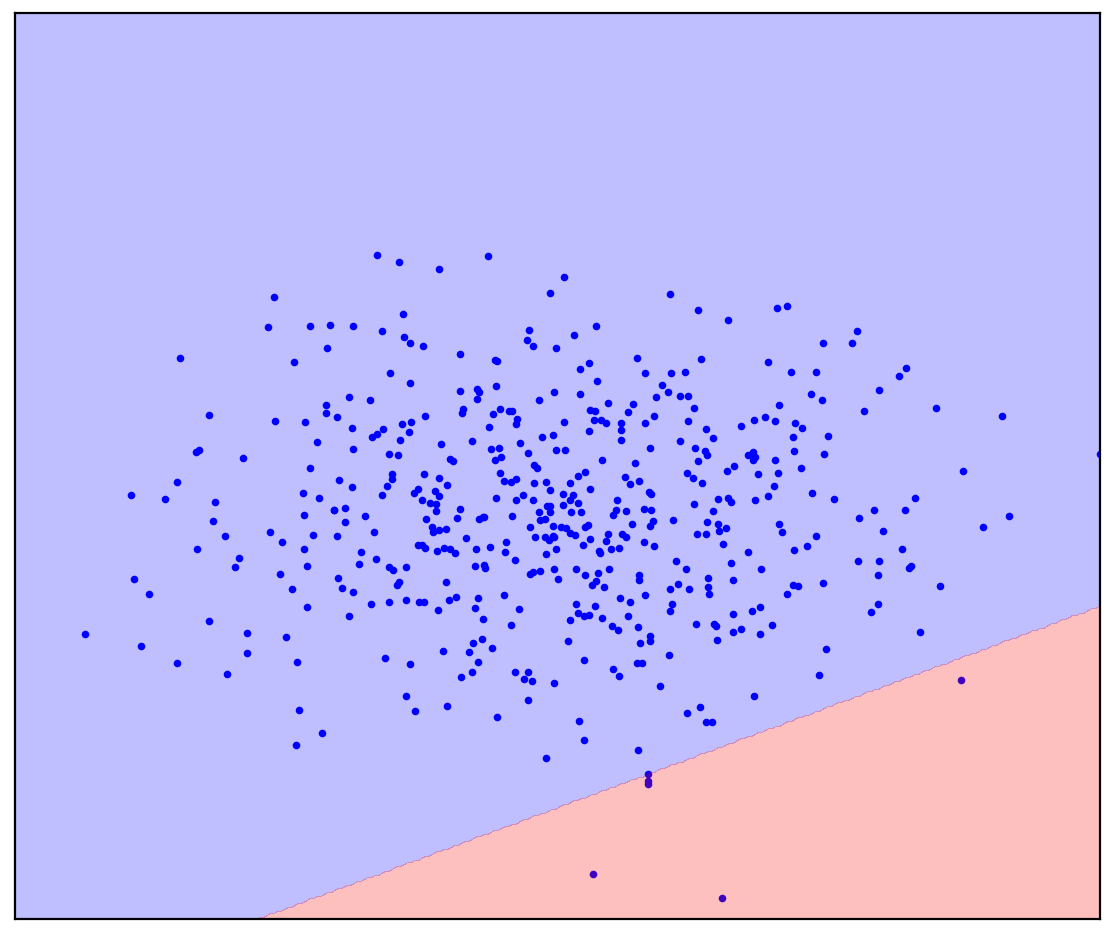
. 1. ( One-Class SVM)
. 1. ( One-Class SVM)
直線の分割線の場合、単一の答えはありません。どちらの方向に直線を引くかは明確ではありません。
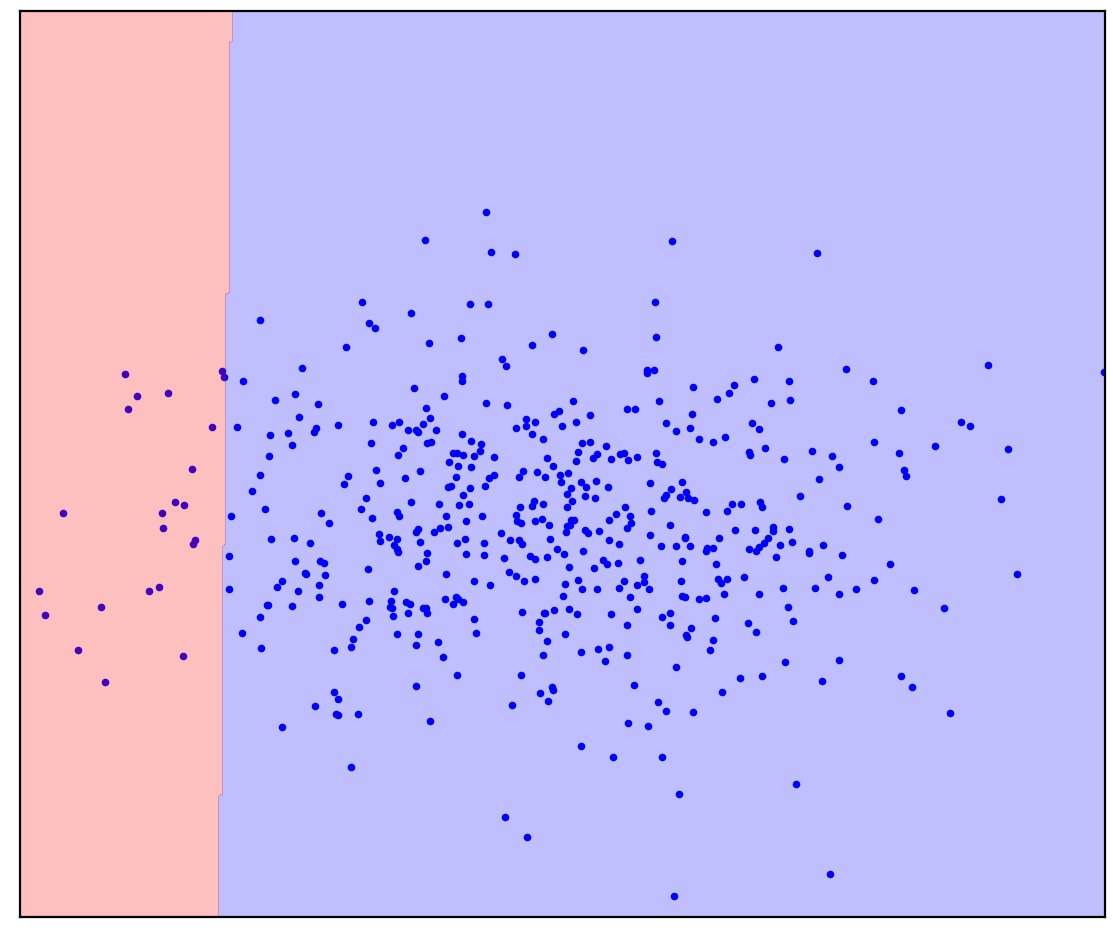
次に、正と負の混合を含むいくつかの未割り当てポイントを図1dに追加します。最後に、心の努力をして、良い点と悪い点を分ける線を想像していただきたいと思います。ただし、今回はラベルのないデータを使用できます。

図:1d。正(青)とラベルなし(赤)のポイント。マークされていないポイントは、正と負で構成されます
答えはここにあります

. 1.
. 1.
楽になりました!マークされていない特定のポイントがどのように生成されるかは事前にはわかりませんが、ポジティブなポイントと比較することで大まかにマークを付けることができます。青のように見える赤い点はおそらく正です。それどころか、異なるものはおそらく否定的です。その結果、「純粋な」ネガティブデータがないにもかかわらず、それらに関する情報をラベルのない混合物から取得して、より正確な分類に使用することができます。これは、私が話したいポジティブラベルなし学習アルゴリズムが行うことです。
前書き
ポジティブ-ラベルなし(PU)学習は、「ポジティブおよびラベルなしデータからの学習」と解釈できます。実際、PU学習は、一方のクラスのラベル付きデータのみが存在する場合のバイナリ分類の類似物ですが、両方のクラスのデータのラベルなしの混合が利用可能です。一般的なケースでは、混合物のデータの量が正のクラスに対応し、どれだけが負のクラスに対応するかさえわかりません。このようなデータセットに基づいて、バイナリ分類子を構築します。これは、両方のクラスの純粋なデータが存在する場合と同じです。
おもちゃの例として、猫と犬の写真の分類子を考えてみましょう。猫の写真と、猫と犬の両方の写真がたくさんあります。出力では、分類子を取得する必要があります。これは、各画像について猫が描かれる確率を予測する関数です。同時に、分類子は、猫と犬の既存の写真の組み合わせにマークを付けることができます。同時に、分類器をトレーニングするために写真を手動でマークアップすることは、困難/費用がかかる/時間がかかる/不可能である可能性があります。
PU学習はかなり自然な作業です。現実の世界で見つかったデータはしばしば汚れています。ダーティデータから学習する機能は、比較的高品質の便利なライフハックのようです。それにもかかわらず、逆説的に、PU学習について聞いたことがある人はほとんどいませんし、特定の方法について知っている人はさらに少なくなっています。そこで、この分野について話すことにしました。

図:2.JürgenSchmidhuberおよびYannLeCun、NeurIPS 2020
PU学習の応用
PU学習が役立つケースを非公式に3つのカテゴリーに分けます。
最初のカテゴリはおそらく最も明白です。通常のバイナリ分類の代わりにPU学習を使用できます。一部のタスクでは、データは本質的にわずかに汚れています。原則として、この汚染は無視でき、従来の分類器を使用できます。ただし、分類器をトレーニングするとき(Kiryo et al。、2017)、またはトレーニング後の予測自体(Elkan&Noto、2008)でさえ、損失関数をほとんど変更することはできず、分類はより正確になります。
例として、病気の遺伝子の発生に関与する新しい遺伝子の同定を考えてみましょう。標準的なアプローチは、すでに陽性であることがわかっている疾患遺伝子を治療し、他のすべての遺伝子を陰性として治療することです。まだ発見されていない病気の遺伝子がこの否定的なデータに存在する可能性があることは明らかです。さらに、タスク自体は、「ネガティブ」データの中からそのような疾患遺伝子を検索することです。この内部矛盾はここで注目されます:(Yang et al。、2012)。研究者たちは、標準的なアプローチから逸脱し、すでに発見された疾患遺伝子に関連しない遺伝子を非標識混合物と見なし、PU学習法を適用しました。
もう1つの例は、専門家によるデモンストレーションに基づく強化学習です。課題は、専門家と同じように行動するようにエージェントをトレーニングすることです。これは、生成的敵対的模倣学習(GAIL)メソッドを使用して実現できます。 GAILはGANのような(生成的敵対ネットワーク)アーキテクチャを使用します:エージェントは軌道を生成するため、弁別者(分類子)はそれらを専門家のデモンストレーションと区別できません。 DeepMindの研究者は最近、GAILでディスクリミネーターがPU学習問題を解決することに気づきました(Xu&Denil、2019)..。通常、ディスクリミネーターはエキスパートデータをポジティブと見なし、生成されたデータをネガティブと見なします。この近似は、ジェネレーターがポジティブに見えるデータを生成できないトレーニングの開始時に十分に正確です。ただし、トレーニングが進むにつれて、生成されたデータは、トレーニングの終了時に識別者が区別できなくなるまで、エキスパートデータのように見えます。このため、研究者(Xu&Denil、2019)は、生成されたデータを、混合比が可変のラベルなしデータであると見なしています。その後、GANは、画像を生成するときに同様の方法で変更されました(Guo et al。、2020)。

図: 3.標準PN分類の類似物としてのPU学習
2番目のカテゴリーでは、 PU学習は、1クラス分類(OCC)の類似物として異常検出に使用できます。正確にタグなしのデータがどのように役立つかについては、前文ですでに見てきました。すべてのOSSメソッドは、例外なく、ネガティブデータの分布について仮定することを余儀なくされています。たとえば、正のデータを楕円(多次元の場合はハイパースフィア)に丸で囲み、その外側ではすべての点が負になるのが賢明です。この場合、ネガティブデータが均等に分散されていると仮定します(Blanchard et al。、2010)..。PU学習方法では、このような仮定を行うのではなく、ラベルのないデータに基づいてネガティブデータの分布を推定できます。これは、2つのクラスの分布が強く重複している場合に特に重要です(Scott&Blanchard、2009)。PU学習を使用した異常検出の一例は、偽のレビュー検出です(Ren et al。、2014)。

図:4.偽のレビューの例
ロシアの公的調達オークションにおける破損の検出
PU学習の3番目のカテゴリは、バイナリ分類もシングルクラス分類も使用できない問題に起因する可能性があります。例として、ロシアの公共調達のオークションでの破損を検出するための私たちのプロジェクトについて説明します(Ivanov&Nesterov、2019)。
法律によると、すべての公的調達オークションに関する完全なデータは、それらを解析するために1か月を費やしたいすべての人のためにパブリックドメインに配置されます。 2014年から2018年にかけて開催された100万を超えるオークションからデータを収集しました。誰が、いつ、どれだけ、誰が勝ったか、どの期間にオークションが行われたか、誰が開催したか、何を購入したかなど、すべてがデータに含まれています。ただし、もちろん「破損はここにあります」というラベルはないので、通常の分類器を作成することはできません。代わりに、PU学習を適用しました。基本的な前提:不当なアドバンテージを持つ参加者は常に勝ちます。この仮定を使用すると、オークションの敗者は公正(ポジティブ)と見なされ、勝者は潜在的に不正(タグなし)と見なされます。この設定では、PU学習メソッドは、勝者と敗者の微妙な違いに基づいて、データ内の疑わしいパターンを見つけることができます。もちろん、実際には困難が生じます。分類子の機能の正確な設計、その予測の解釈可能性の分析、およびデータに関する仮定の統計的検証が必要です。
非常に控えめな見積もりによると、データ内のオークションの約9%が破損しており、その結果、州は年間約1億2,000万ルーブルを失っています。損失はそれほど大きくはないように思われるかもしれませんが、私たちが調査しているオークションは、公共調達市場の約1%しか占めていません。


図:5.ロシアのさまざまな地域での腐敗した公的調達オークションのシェア(Ivanov&Nesterov、2019)
最後に
PUが人類のすべての問題の解決策であるという印象を与えないために、私は落とし穴に言及します。従来の分類では、データが多いほど、分類子の精度が高くなります。さらに、データ量を無限大に増やすことで、理想的な(ベイジアン式による)分類器に近づくことができます。したがって、PU学習の主な問題は、それが不適切な問題、つまり、無限の量のデータがあっても明確に解決できない問題であるということです。ラベルのないデータの2つのクラスの比率がわかっている場合は状況が良くなりますが、この比率を決定することも不適切な問題です(Jain et al。、2016)..。定義できる最善の方法は、比率の間隔です。さらに、PU学習方法では、この比率を推定して既知であると見なす方法が提供されないことがよくあります。それを推定する別々の方法があります(タスクは混合比率推定と呼ばれます)が、特に2つのクラスが混合物で非常に不均一に表される場合、それらはしばしば遅いか不安定です。
この投稿では、PU学習の直感的な定義と応用について話しました。さらに、公式とその説明を使用したPU学習の正式な定義、および古典的および現代的なPU学習方法について説明します。この投稿が興味をそそるなら、私は続編を書きます。
書誌
Blanchard, G., Lee, G., & Scott, C. (2010). Semi-supervised novelty detection. Journal of Machine Learning Research, 11(Nov), 2973–3009.
Elkan, C., & Noto, K. (2008). Learning classifiers from only positive and unlabeled data. Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD 08, 213. https://doi.org/10.1145/1401890.1401920
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., & Tao, D. (2020). On Positive-Unlabeled Classification in GAN. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8385–8393.
Ivanov, D. I., & Nesterov, A. S. (2019). Identifying Bid Leakage In Procurement Auctions: Machine Learning Approach. ArXiv Preprint ArXiv:1903.00261.
Jain, S., White, M., Trosset, M. W., & Radivojac, P. (2016). Nonparametric semi-supervised learning of class proportions. ArXiv Preprint ArXiv:1601.01944.
Kiryo, R., Niu, G., du Plessis, M. C., & Sugiyama, M. (2017). Positive-unlabeled learning with non-negative risk estimator. Advances in Neural Information Processing Systems, 1675–1685.
Ren, Y., Ji, D., & Zhang, H. (2014). Positive Unlabeled Learning for Deceptive Reviews Detection. EMNLP, 488–498.
Scott, C., & Blanchard, G. (2009). Novelty detection: Unlabeled data definitely help. Artificial Intelligence and Statistics, 464–471.
Xu, D., & Denil, M. (2019). Positive-Unlabeled Reward Learning. ArXiv:1911.00459 [Cs, Stat]. http://arxiv.org/abs/1911.00459
Yang, P., Li, X.-L., Mei, J.-P., Kwoh, C.-K., & Ng, S.-K. (2012). Positive-unlabeled learning for disease gene identification. Bioinformatics, 28(20), 2640–2647.