この最後の投稿は、分散分析に関するものです。ここで前の投稿を参照してください。
分散分析
分散分析(分散)。特別な文献では、英語ではANOVAとも呼ばれます。ANalysis Of VArianceは、グループ間の差異の統計的有意性を測定するために使用される一連の統計的手法です。これは、非常に才能のある統計学者であるロナルド・フィッシャーによって開発されました。ロナルド・フィッシャーは、生物学的検定の研究論文でも統計的有意性検定を普及させました。
注意..。以前および今回の一連の投稿では、「分散」という用語は、受け入れられている「分散」という用語で使用され、「分散」という用語は、括弧内の場所で示されていました。これは偶然ではありません。海外には「分散」と「共分散」のペアの用語があり、理論的には「分散」と「共分散」のように1つのルートで翻訳する必要がありますが、実際には、ペアの接続が壊れています。完全に異なる「分散」と「共分散」として翻訳されます。しかし、それだけではありません。海外での「分散」(統計的分散)は、分散の別個の一般的な概念です。分布が伸びたり縮んだりする程度、および統計的分散の尺度は、分散、標準偏差、および四分位範囲です。分散の一般的な概念としての分散、およびその尺度の1つとしての分散、平均からの距離を測定することは、2つの異なる概念です。さらに、差異のテキストでは、一般的に受け入れられている用語「差異」が全体を通して使用されます。ただし、この用語の不一致を考慮に入れる必要があります。
2つのサンプルを区別するための主要なメカニズムとしてサンプル平均に焦点を当てたz統計テストとt統計テスト。いずれの場合も、平均値の不一致を、合理的に予想できる不一致のレベルで割って、標準誤差で定量化して探しました。
サンプル間の不一致を示す可能性のあるサンプル指標は、平均だけではありません。実際、サンプルの分散は、統計的な不一致の指標としても使用できます。
、ページごと、および組み合わせ")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
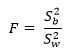
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
次の一連の投稿では、読者が希望する場合は、分散とF検定について学んだことを単一のサンプルに適用します。回帰分析法を提示し、それを使用して、オリンピック選手のサンプルの変数間の相関関係を見つけます。