人と知り合うほど、犬が好きになります。
-マーク・トウェイン
PythonのリミックスブックHenryGarner« Clojureのデータ調査»(Clojure for Data Science)の初心者向けの以前の一連の投稿では、要約統計量の観点からサンプルを説明する方法を確認しました。統計的推測方法は母集団のパラメーターです。この分析は、母集団全体、特にサンプルについて何かを教えてくれますが、個々の要素について非常に正確なステートメントを作成することはできません。これは、データを2つの統計(平均と標準偏差)に減らすと、膨大な量の情報が失われるためです。
多くの場合、さらに進んで2つ以上の変数間の関係を確立するか、別の変数が存在する場合に1つの変数を予測する必要があります。そして、それはこの5ポストシリーズのトピックに私たちをもたらします-相関と回帰を探ります。相関は、2つ以上の変数間の関係の強さと方向性を扱います。回帰は、この関係の性質を決定し、それに基づいて予測を行うことを可能にします。
この一連の投稿では、線形回帰について説明します。データのサンプルが与えられると、モデルは線形方程式を学習し、これにより、以前は表示されなかった新しいデータについて予測を行うことができます。これを行うには、パンダライブラリに戻り、オリンピック選手の身長と体重の関係を調べます。マトリックスの概念を紹介し、パンダライブラリを使用してマトリックスを管理する方法を示します。
データについて
この一連の投稿では、2012年ロンドンオリンピックに出場したアスリートに関するGuardian News and MediaLtd。の好意によるデータを使用しています。このデータは、もともとガーディアン紙のブログから取られたものです。
データ調査
新しいデータセットに直面したときの最初のタスクは、データセットに何が含まれているかを理解するためにデータセットを調査することです。
all-london-2012-athletes.tsvファイルはかなり小さいです。最初の一連の投稿「Python、データ探索と選択」で行ったように、関数を使用してパンダを使用してデータを探索できますread_csv
。
def load_data():
return pd.read_csv('data/ch03/all-london-2012-athletes-ru.tsv', '\t')
def ex_3_1():
'''
2012 .'''
return load_data()
この例をPythonインタープリターコンソールまたはJupyterノートブックで実行すると、次の出力が表示されます。
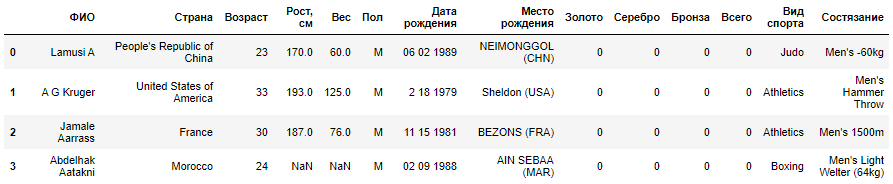
|
|
|
|
( , ) :
,
,
, .
, .
«» «»
( )
,
,
,
, , , . , .
2012 . . , , :
def ex_3_2():
'''
'''
df = load_data()
df[', '].hist(bins=20)
plt.xlabel(', .')
plt.ylabel('')
plt.show()
:
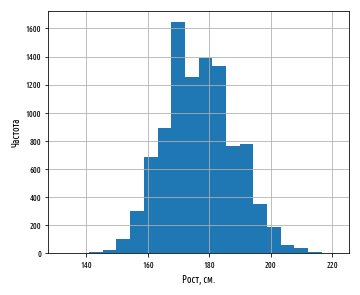
, . 177 . :
def ex_3_3():
''' '''
df = load_data()
df[''].hist(bins=20)
plt.xlabel('')
plt.ylabel('')
plt.show()
:
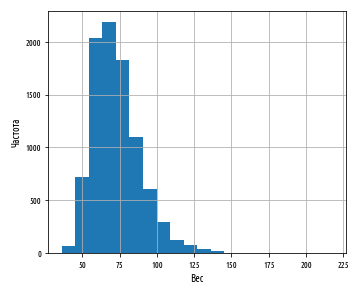
. , , , - . pandas skew
:
def ex_3_4():
''' '''
df = load_data()
swimmers = df[ df[' '] == 'Swimming']
return swimmers[''].skew()
0.23441459903001483
, numpy np.log
:
def ex_3_5():
'''
'''
df = load_data()
df[''].apply(np.log).hist(bins=20)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
:
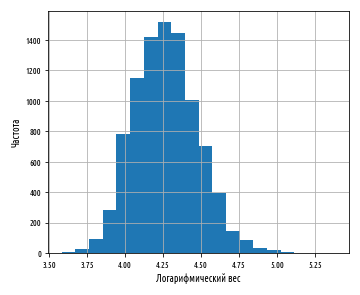
. , .
— , . . , .
, () . , , . 10 e, , 2.718. numpy np.log
np.exp
e. loge , ln, - , .
, . , c 1931 . , , . , , .
, , , , , .
, , , Wolfram MathWorld, .
, . , , .
, . , , :
def swimmer_data():
''' '''
df = load_data()
return df[df[' '] == 'Swimming'].dropna()
def ex_3_6():
''' '''
df = swimmer_data()
xs = df[', ']
ys = df[''].apply( np.log )
pd.DataFrame(np.array([xs,ys]).T).plot.scatter(0, 1, s=12, grid=True)
plt.xlabel(', .')
plt.ylabel(' ')
plt.show()
:

, . , . :

, , , . , , , . , , , - ( . . ). , , , , . ( ) , , , , , . .
, , 180 , 179.5 180.5 , 80 79.5 80.5 . , -0.5 0.5 (, c , ):
def jitter(limit):
''' ( )'''
return lambda x: random.uniform(-limit, limit) + x
def ex_3_7():
''' '''
df = swimmer_data()
xs = df[', '].apply(jitter(0.5))
ys = df[''].apply(jitter(0.5)).apply(np.log)
pd.DataFrame(np.array([xs,ys]).T).plot.scatter(0, 1, s=12, grid=True)
plt.xlabel(', .')
plt.ylabel(' ')
plt.show()
:

, — , , , .
. .
, X Y, :


xi — X i, yi — Y i, x̅ — X, y̅ — Y. X Y , : , — , , . , , , , . .
:

Python :
def covariance(xs, ys):
''' (, .. n-1)'''
dx = xs - xs.mean()
dy = ys - ys.mean()
return (dx * dy).sum() / (dx.count() - 1)
, pandas cov
:
df[', '].cov(df[''])
1.3559273321696459
1.356, . .
. , . -1 +1. .
, . standard score, z- — , . , , — . , .
r , dxi dyi :

X Y , , σx σy — X Y:

, , r.
. :
def variance(xs):
''' ,
n <= 30'''
x_hat = xs.mean()
n = xs.count()
n = n - 1 if n in range( 1, 30 ) else n
return sum((xs - x_hat) ** 2) / n
def standard_deviation(xs):
''' '''
return np.sqrt(variance(xs))
def correlation(xs, ys):
''' '''
return covariance(xs, ys) / (standard_deviation(xs) *
standard_deviation(ys))
pandas corr
:
df[', '].corr(df[''])
, r . r -1.0 1.0, .
, r = 0, , . . , , r :

, , y = 0. r 0, . ; y . .
:
def ex_3_8():
''' pandas
'''
df = swimmer_data()
return df[', '].corr( df[''].apply(np.log))
0.86748249283924894
0.867, , , .
r ρ
, . ; , : . r, ρ ().
, , , , . , . , , , -.
— , , — . , r, ρ, :
r
, , , . , , , . , .
, , (, , ) . , , .
, , :


H0 - , . , , .
H1 - , . , , . , .
r :

, r (, ρ ), , , .
t- t-:

df — . n - 2, n — . , :

t- 102.21. p- t-. scipy () t- stats.t.cdf
, (1-cdf) stats.t.sf
. p- . 2, :
def t_statistic(xs, ys):
''' t-'''
r = xs.corr(ys) # , correlation(xs, ys)
df = xs.count() - 2
return r * np.sqrt(df / 1 - r ** 2)
def ex_3_9():
''' t-'''
df = swimmer_data()
xs = df[', ']
ys = df[''].apply(np.log)
t_value = t_statistic(xs, ys)
df = xs.count() - 2
p = 2 * stats.t.sf(t_value, df) #
return {'t-':t_value, 'p-':p}
{'p-': 1.8980236317815443e-106, 't-': 25.384018200627057}
P- , 0, , , , . .
, , , , , , , , , ρ, . , r ( %), ρ .
, . r 1, r r .

r- ρ, 0.6.
, z- r . , , .
z- :

z :

, r z z-, SEz r.
SEz, , . 1.96, , 95% . , 1.96 r ρ 95%- .

, scipy stats.norm.ppf
. , .
, , , .. 2.5%, , 95%- . 100%. , 95% , 97.5%:
def critical_value(confidence, ntails): #
'''
'''
lookup = 1 - ((1 - confidence) / ntails)
return stats.norm.ppf(lookup, 0, 1) # mu=0, sigma=1
critical_value(0.95, 2)
1.959963984540054
95%- z- ρ :

zr SEz, :

r=0.867 n=859 1.137 1.722. z- r-, z-:

:
def z_to_r(z):
''' z- r-'''
return (np.exp(z*2) - 1) / (np.exp(z*2) + 1)
def r_confidence_interval(crit, xs, ys):
'''
'''
r = xs.corr(ys)
n = xs.count()
zr = 0.5 * np.log((1 + r) / (1 - r))
sez = 1 / np.sqrt(n - 3)
return (z_to_r(zr - (crit * sez))), (z_to_r(zr + (crit * sez)))
def ex_3_10():
'''
'''
df = swimmer_data()
X = df[', ']
y = df[''].apply(np.log)
interval = r_confidence_interval(1.96, X, y)
print(' (95%):', interval)
(95%): (0.8499088588880347, 0.8831284878884087)
95%- ρ, 0.850 0.883. , .
この投稿のソースコードの例は、私の Githubリポジトリにあります。すべてのソースデータは 、本の著者のリポジトリから取得され ます。
次の投稿、投稿#2では、シリーズ自体のトピック、つまり回帰とその品質を評価するための手法について検討します。