ここで前の投稿を参照してください。
回帰
2つの変数が相関していることを知っておくと役立つ場合がありますが、身長データが存在する場合のオリンピック水泳選手の体重を予測するためにこの情報を単独で使用することはできません。相関関係を確立するときに、接続の強度と符号を測定しましたが、勾配は測定しませんでした。スロープ。予測を生成するには、別の変数の特定の単位変化に対する1つの変数の予想変化率を知る必要があります。
ある変数の特定の値、いわゆる独立変数を、別の従属変数の期待値に関連付ける方程式を導き出します。たとえば、線形方程式が特定の高さの重量を予測する場合、成長は独立変数であり、重量に依存します。
これらの方程式で表される直線は、回帰直線と呼ばれます。この用語は、19世紀の英国の博学者であるサーフランシスガルトンによって造られました。彼と彼の学生であるカール・ピアソンは、相関係数を導き出し、19世紀に線形関係を研究するための多数の方法を開発しました。これは、まとめて回帰分析法として知られるようになりました。
相関関係は因果関係を意味するものではなく、「依存」および「独立」という用語は暗黙の因果関係を意味するものではないことを思い出してください。これらは、入力および出力の数学値の単なる名前です。古典的な例は、消火のために送られた消防車の数と火災による被害との間に非常に正の相関関係があることです。もちろん、消火のために消防車を送ること自体は損害を引き起こしません。被害を減らす方法として、消火のために送られる車両の数を減らすことを勧める人は誰もいません。このような状況では、他の変数と因果関係がある追加の変数を探し、それらの間の相関関係を説明する必要があります。この例では、それは火のサイズである可能性があります..。このような根本的な原因は、従属変数間の関係を決定する能力を歪めるため、交絡変数と呼ばれます。
一次方程式
x とyとして表すことができる2つの変数は、厳密にまたは大まかに相互に関連付けることができます。独立変数x と従属変数yの間の最も単純な関係は単純で 、次の式で表されます。

a b . a , b — , . , a = 32 b = 1.8. a b, :

10° x 10:

, , 10° 50°F, . Python pandas, , :
''' '''
celsius_to_fahrenheit = lambda x: 32 + (x * 1.8)
def ex_3_11():
''' '''
df = pd.DataFrame({'C':s, 'F':s.map(celsius_to_fahrenheit)})
df.plot('C', 'F', legend=False, grid=True)
plt.xlabel(' ')
plt.ylabel(' ')
plt.show()
:
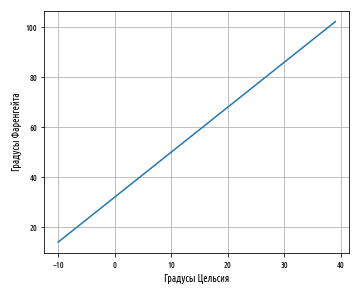
, 0 32 . a — y, x 0.
b; 2. , . , , .
, , . y x. , , , , :

, ε — , , a b x y. y — ŷ, — :

. - , , , . , , , ( ).
a b , x , . , , , x y.
, , , , , . , , .
, , , . , , , .
, , . , . Ordinary Least Squares (OLS), :

, , , . , , , :
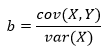
(a) — , X Y:

a b — , .
covariance
, variance
mean
, . :
def slope(xs, ys):
''' ( )'''
return xs.cov(ys) / xs.var()
def intercept(xs, ys):
''' ( Y)'''
return ys.mean() - (xs.mean() * slope(xs, ys))
def ex_3_12():
''' ( )
'''
df = swimmer_data()
X = df[', ']
y = df[''].apply(np.log)
a = intercept(X, y)
b = slope(X, y)
print(': %f, : %f' % (a,b))
: 1.691033, : 0.014296
0.0143 1.6910.
— ( ), () . np.exp
, np.log
. , 5.42 . , , .
, y x. , 1.014 . . , , , .
regression_line
x, ŷ a b.
''' '''
regression_line = lambda a, b: lambda x: a + (b * x) # fn(a,b)(x)
def ex_3_13():
'''
'''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=7)
s = pd.Series(range(150,210))
df = pd.DataFrame( {0:s, 1:s.map(regression_line(a, b))} )
df.plot(0, 1, legend=False, grid=True, ax=ax)
plt.xlabel(', .')
plt.ylabel(' ')
plt.show()
regression_line
x, a + bx.
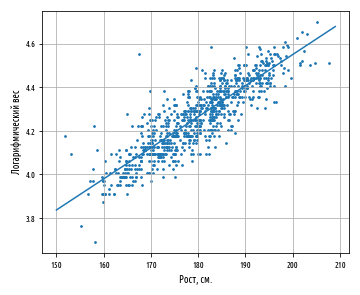
, , ŷ y.
def residuals(a, b, xs, ys):
''' '''
estimate = regression_line(a, b) #
return pd.Series( map(lambda x, y: y - estimate(x), xs, ys) )
constantly = lambda x: 0
def ex_3_14():
''' '''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
y = residuals(a, b, X, y)
ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=12)
s = pd.Series(range(150,210))
df = pd.DataFrame( {0:s, 1:s.map(constantly)} )
df.plot(0, 1, legend=False, grid=True, ax=ax)
plt.xlabel(', .')
plt.ylabel('')
plt.show()
— , Y X. , :
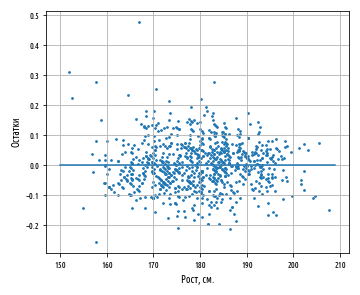
, , -, , . , . , , .
, , , . , . , , . , .
, . . , , , .. . , , , .
. , , , , .
R-
, , .. , . R2, R-, 0 1 . .
, R2 1, Y X. R2 :
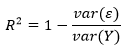
var(ε) — var(Y) — Y. , - . , . var(Y), .. .
, , a + bx. .
var(ε)/var(Y) — , . . , . R2 — , .
r, R2 , . , .
R2 . — , R2. R2 .
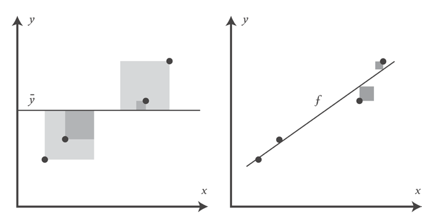
, , , , f. , y. R2 y:
def r_squared(a, b, xs, ys):
''' (R-)'''
r_var = residuals(a, b, xs, ys).var()
y_var = ys.var()
return 1 - (r_var / y_var)
def ex_3_15():
''' R-
'''
df = swimmer_data()
X = df[', '].apply( jitter(0.5) )
y = df[''].apply(np.log)
a, b = intercept(X, y), slope(X, y)
return r_squared(a, b, X, y)
0.75268223613272323
0.753. , 75% , 2012 ., .
( ), R2 r :
r , Y X, R2 0.52, .. 0.25.
, . , . .
. , , β (), :

- , β1 = a β2 = b , x1 1, β1 — , , x1 () , .
β, , :

x1 xn , y. β1 βn , .
, : , , , . , , .
, x. pandas, , : .
この投稿のソースコードの例は、私の Githubリポジトリにあります。すべてのソースデータは、本の著者のリポジトリから取得され ます 。
次の投稿、投稿#3のトピックは、行列演算、正規方程式、および共線性です。