
YELPは、フィードバック、好み、推奨事項に基づいて地元の企業やサービスを見つけるのに役立つ海外ネットワークです。現在の記事では、グラフDBMSに関連するNeo4jプラットフォームとPython言語を使用して、その特定の分析が実行されます。
私たちが見るもの:
- 例としてYELPを使用してNeo4jおよび大規模なデータセットを操作する方法。
- YELPデータセットがどのように役立つか。
- 部分的に:Neo4jの新しいバージョンの機能と、O'REILLYによる「GraphAlgorithms」2019の本がすでに古くなっている理由。
YELPとyelpデータセットとは何ですか
YELPネットワークは現在30か国をカバーしており、ロシア連邦はまだその数に含まれていません。ロシア語はネットワークでサポートされていません。ネットワーク自体には、さまざまな種類の企業に関するかなりの量の情報と、それらに関するレビューが含まれています。また、yelpにはレビューを残したユーザーに関するデータが含まれているため、安全にソーシャルネットワークと呼ぶことができます。そこには個人データはなく、名前だけがあります。それでも、ユーザーはコミュニティやグループを形成するか、さまざまな基準に従ってこれらのグループやコミュニティにさらに統合することができます。たとえば、訪問したポイント(レストラン、ガソリンスタンドなど)に割り当てられた星(星)の数によって。
YELPはそれ自体を次のように説明しています。
- 8,635,403件のレビュー
- 160,585社
- 200,000枚の画像
- 8メガロポリス
2,189,457人のユーザーからの1,162,119件の推奨事項。
120万を超えるビジネス用品:営業時間、駐車場、空き状況など。
2013年以来、Yelpは定期的にYelp Datasetコンテストを主催しており
、Yelpのオープンデータセットを探索して探索することをすべての人に奨励しています 。
データセット自体はリンクから 入手できます 。
データセットは非常に大量で、解凍後は5つのjsonファイルで構成されます。
すべて問題ありませんが、YELPのみが未処理の未処理データをアップロードし、それらの処理を開始するには前処理が必要です。
Neo4jのインストールとクイックセットアップ
分析には、Neo4jを使用し、グラフDBMSの機能とその単純な暗号言語を使用してデータセットを操作します。 Habreで繰り返し書かれているグラフデータベースとしてのNeo4j
について ( 初心者向けの記事はここと ここにあります)、再送信しても意味がありません。 プラットフォームでの作業を開始するには、デスクトップバージョン(約500Mb)をダウンロードするか、オンラインサンドボックスで作業する必要があります。この記事の執筆時点では、Neo4j Enterprise 4.2.6 for Developersと、その他の以前のバージョンのインストールが利用可能です。
さらに、このオプションが使用されます-Windows環境のデスクトップバージョン(Neo4jデスクトップ1.4.5、データベースバージョン4.2.5、4.2.1)で動作します。
最新バージョンは4.2.6ですが、neo4jで使用されるすべてのプラグインがまだ更新されていないため、まだインストールしないことをお勧めします。以前のバージョン-4.2.5で十分です。
ダウンロードしたパッケージをインストールした後、次のことを行う必要があります。
- ユーザーneo4jとパスワード123を指定して新しいローカルデータベースを作成します(正確には以下で説明します)。
画像

- 必要なプラグインをインストールします-APOC、グラフデータサイエンスライブラリ。
画像

- データベースが起動するかどうか、および開始ボタンをクリックしたときにブラウザが開くかどうかを確認します
画像


*-データベースが真剣に新しいバージョンを提案しようとしないように、オフラインモードを有効にします。
画像

Neo4jへのデータのロード
Neo4jのインストールですべてが順調に進んだ場合は、先に進むことができます。3つの方法があります。
最初の方法は、最初のクリーニングと変換を含め、データをデータベースに最初からインポートすることから長い道のりを進むことです。
2番目の方法は、完成したデータベースをダンプからロードして、作業を開始することです。
3番目の方法は、完成したデータベースを、新しく作成されたデータベースのあるフォルダーに直接ロードすることです。
その結果、すべての場合において、次のパラメーターを含むデータベースを取得する必要があります。

最後のスキーム:
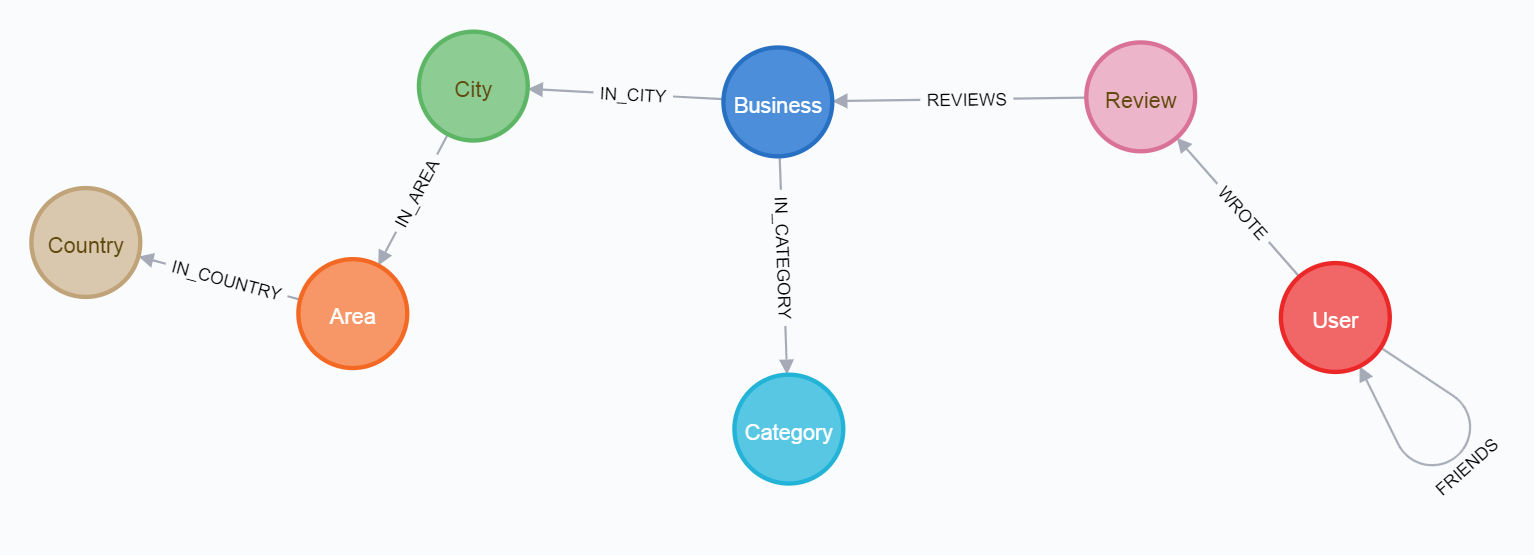
最初のパスを通過するには、最初にメディアの記事を読むことをお勧めし ます。
*これについてはTRANNgocThachに感謝します。
そして、既製のjupyterノートブック(私がWindows用に採用したもの)を使用します- リンク。
インポートプロセスは簡単ではなく、非常に長い時間がかかります-

バッチインポートが使用されるため、RAMが8GBしかない場合でも、メモリに問題はありません 。
ただし、インポートされたデータをチェックするとjupyterがクラッシュするため、上記のjupyterノートブックにこの点が記載されているため、10GBのスワップファイルを作成する必要があります。
2番目の方法は簡単です。
データベースを作成し、neo4j-admin(各データベースには独自のデータベースがあります)のあるフォルダーに移動して、以下を実行します。
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
ここで、G:\ neo4j \ dumps \ neo4j.dumpは、データベースダンプへのパスです。
3番目の方法は最速で、偶然に発見されました。これは、既製のneo4jデータベースを既存のneo4jデータベースに直接コピーすることを意味します。マイナス(これまでに発見された)のうち、Neo4jを使用してデータベースをバックアップすることはできません(neo4j-admin dump --database = neo4j --to = D:\ neo4j \ neo4j.dump)。ただし、これはバージョンの違いが原因である可能性があります。バージョン4.2.1では、データベースはバージョン4.2.5からコピーされました。さらに、アーティファクトは一般的なデータベーススキームに表示されますが、それでもその動作には影響しません。
このメソッドの実装方法:
- インポートが行われるデータベースの[管理]タブを開きます
画像


- データベースのあるフォルダーに移動し、そこにデータフォルダーをコピーして、一致する可能性のあるものを上書きします
画像

この場合、コピーが作成されたデータベース自体を開始しないでください。
- Neo4jを再起動します。
そして、これは以前に使用されたログインパスワード(neo4j、123)が競合を回避するのに役立つ場所です。
コピーされたデータベースを開始すると、yelpデータセットを含むデータベースが利用可能になります。

YELPを見る
YELPは、Neo4jブラウザーからも、同じjupyterノートブックからデータベースにクエリを送信することによっても学習できます。
データベースがグラフィカルであるという事実により、ブラウザには、これらのグラフが表示される快適な視覚的画像が付属します。
YELPに慣れ始めたら、データベースに含まれるのは米国、KG、CAの3か国のみであることを予約する必要があります。neo4j

ブラウザーで暗号言語でリクエストを書き込むと、データベーススキーマを表示できます。
CALL db.schema.visualization()
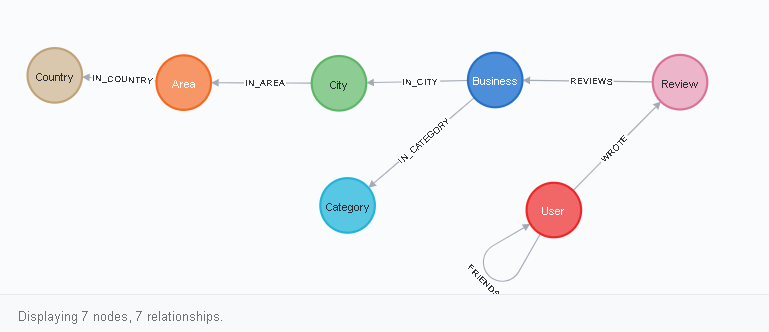
この図の読み方は?すべてがこのように見えます。ユーザーノードには、FRIENDSタイプのそれ自体へのリンクと、レビューノードへのWROTEリンクがあります。次に、Rewiewは、ビジネスなどとREVIEWS接続を持っています。たとえば、ユーザーの頂点(ノードラベル)の1つをクリックすると、これを視覚的に確認できます。

データベースは25人のユーザーを選択して表示します。ユーザー

の対応するアイコンを直接クリックすると、すべてのユーザーが表示されます。彼からの直接接続が表示され、FRIENDSとREVIEWの2つのタイプのユーザーの接続として、それらすべてが表示されます。
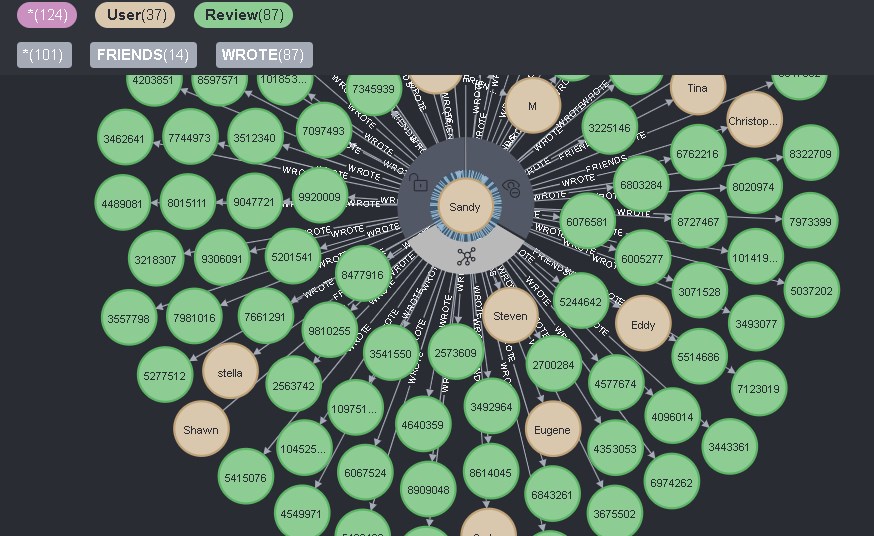
これは、便利であると同時に不便です。ワンクリックでユーザーの情報をすべて見ることができますが、同時にこのクリックで不要な情報を削除することはできません。
しかし、心配することは何もありません。このユーザーとそのすべての友達だけをIDで見つけることができます。
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

同様に、特定の人が書いたレビューを確認できます

。YELPは、2010年からのレビューをすでに保存しています。疑わしい有用性ですが、それでも。
これらのレビューを読むには、Aをクリックしてテキストビューに切り替える必要があります-

サンディが約10年前に書いた場所を見て、yelp.comで見つけましょう-

そのような場所は実際に存在します -www.yelp.com/ biz / cafe-sushi- cambridge、
そしてここに彼女自身のレビューを持つSandy自身があります -www.yelp.com/biz/cafe-sushi-cambridge?q = I %20was%20really%20excited
画像

jupyterノートブックからのNeo4jデータベースでのPythonクエリ
O'REILLYの前述の無料の本「GraphAlgorithms」2019の情報を部分的に使用します。この本の構文が多くの場所で古くなっていることも一因です。
neo4jブラウザー自体を起動する必要はありませんが、作業するベースを起動する必要があります。
ライブラリのインポート:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
DB接続:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
データベース内の各ラベルの頂点の数を数えましょう。
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
出力:
+ ---------- + --------- +
|ラベル|カウント|
| ---------- + --------- |
|国| 3 |
|エリア| 15 |
|市| 355 |
|カテゴリ| 1330 |
|ビジネス| 160585 |
|ユーザー| 2189457 |
|レビュー| 8635403 |
+ ---------- + --------- +
確かに、neo4jブラウザーで以前に見たように、データベースには3か国があります。
そして、このコードはリンク(エッジ)の数を数えます:
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
出力:
+ ------------- + --------- +
| relType | カウント|
| ------------- + --------- |
| IN_COUNTRY | 15 |
| IN_AREA | 355 |
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| レビュー| 8635403 |
| 書いた| 8635403 |
| フレンズ| 8985774 |
+ ------------- + --------- +
原則は明確だと思います。最後に、リクエストを作成してレンダリングしましょう。
レビューが最も多いバンクーバーのトップ10ホテル
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
結果は次のようになります

。X軸はホテルの星評価を表し、Y軸は各評価の合計パーセンテージを表します。
YELPデータセットがどのように役立つか
利点の中には次のものがあります:
- コンテンツに関してはかなり豊富な情報フィールド。特に、星1.0または5.0のレビューを収集して、あらゆるビジネスにスパムを送信できます。うーん。少し間違った方向ですが、ベクトルは明確です。
- データセットが大きいため、さまざまなデータマイニングプラットフォームのパフォーマンスをテストするという点で、さらに厄介な問題が発生します。
- 提示されたデータには一定の回顧があり、原則として、それに関するレビューに基づいて、企業がどのように変化したかを理解することが可能です。
- アドレスが利用可能であれば、データは企業のベンチマークとして使用できます。
- データセット内のユーザーは、多くの場合、ユーザーを人工的なソーシャルに形成することなく、そのまま使用できる興味深い相互接続された構造を形成します。ネットワークであり、他の既存のソーシャルネットワークからこのネットワークを収集していません。ネットワーク。
短所:
- 30カ国のうち3カ国しか代表されておらず、これが完全ではないという疑いがあります。
- レビューは10年間保存されますが、これは既存のビジネスの特性を歪め、しばしば台無しにする可能性があります。
- ユーザーに関するデータはほとんどなく、非人称的であるため、データセットに基づくレコメンデーションシステムは明らかに不十分です。
- FRIENDSリンクは有向グラフを使用します。つまり、Anyaは友達です-> Petyaです。PetyaはAnyaと友達ではないことがわかりました。これはプログラムで解決できますが、それでも不便です。
- データセットは「生」でレイアウトされており、前処理にはかなりの労力が必要です。
Neo4j
Neo4jは動的に更新され、Neo4j Desktop1.4.5で使用される新しいバージョンのインターフェイスはあまり便利ではないと思います。特に、以前のバージョンにあったデータベース内のノードとリンクの数に関する情報に関しては、明確さが欠けています。さらに、データベースを操作するときにタブをナビゲートするためのインターフェイスが変更されており、それに慣れる必要もあります。
更新の主な厄介な点は、グラフアルゴリズムをグラフデータサイエンスライブラリプラグインに統合することです。以前はneo4j-graph-algorithmsと呼ばれていました 。
統合後、多くのアルゴリズムが構文を大幅に変更しました。このため、O'REILLYによる2019 GraphAlgorithmsの本を研究するのは難しい場合があります。
neo4jのYelpデータベースダンプ- ダウンロード..。